1 概述
深度学习的应用场景
2 图像处理
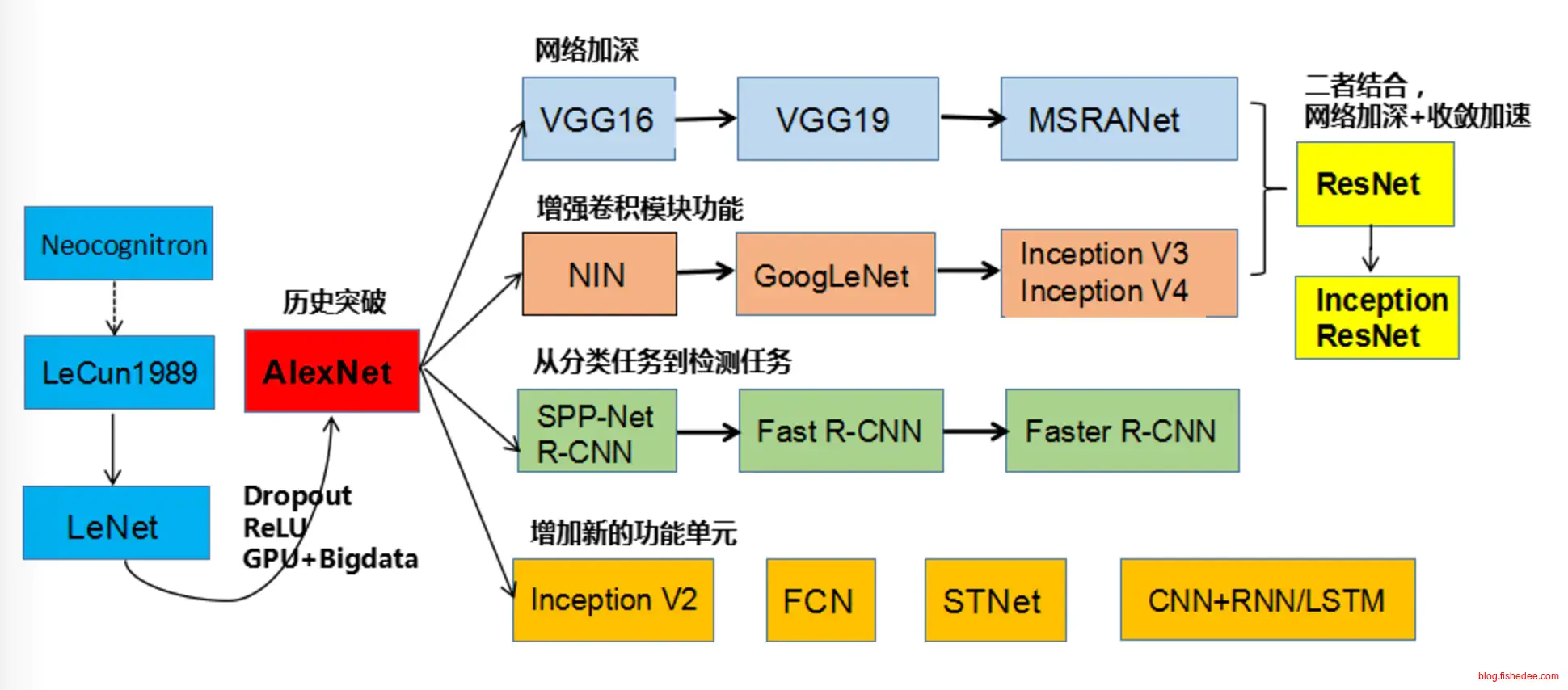
深度学习最开始爆发的地方就是图像处理,使用卷积和池化组成的CNN网络大幅降低了需要训练的权重数量,并且具有了平移,偏置等鲁棒性。
总的来说,目前深度学习在分类,相似匹配,文字识别上所向披靡,甚至超越了人类的识别能力,准确率在99%以上。而目标定位,语义分割上接近能用但不太准确的地步,准确率在85%左右。而生成和变换上仍然处于初期的研究投入的阶段。
2.1 预处理
2.1.1 像素归一化
深度学习对于图像处理可以说是量身定做的,注意一下图像先改一化为[0,1]之间就可以了,然后将像素矩阵扔进去训练就可以了。
2.1.2 大小归一化
输入到神经网络的图像被放缩到统一尺寸中。
2.2 分类
2.2.1 LeNet5
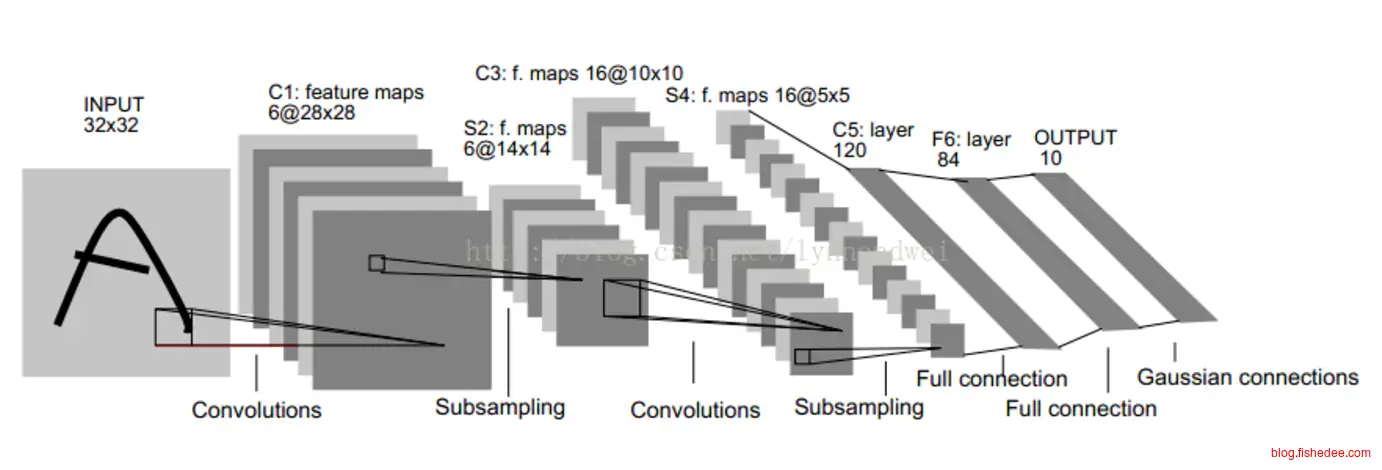
结构为:
- 32x32的输入层
- 6个28x28的卷积层C1,卷积核为5x5
- 6个14x14的下采样层S2,采样核为2x2,步长为2
- 16个10x10的卷积层C3,卷积核为5x5
- 16个5x5的下采样层C4,采样核为2x2,步长为2
- 120个1x1的卷积层C5,卷积核为5x5
- 84个单元的全连接层F6
- 10个单元的输出层
所有的激活函数都为Sigmoid。
这个是当年银行级别的手写字体识别程序。
2.2.2 AlexNet
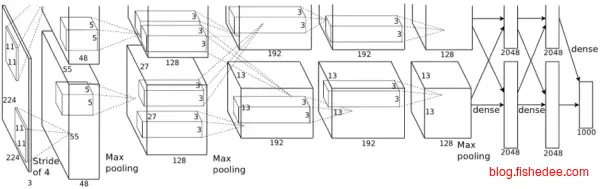
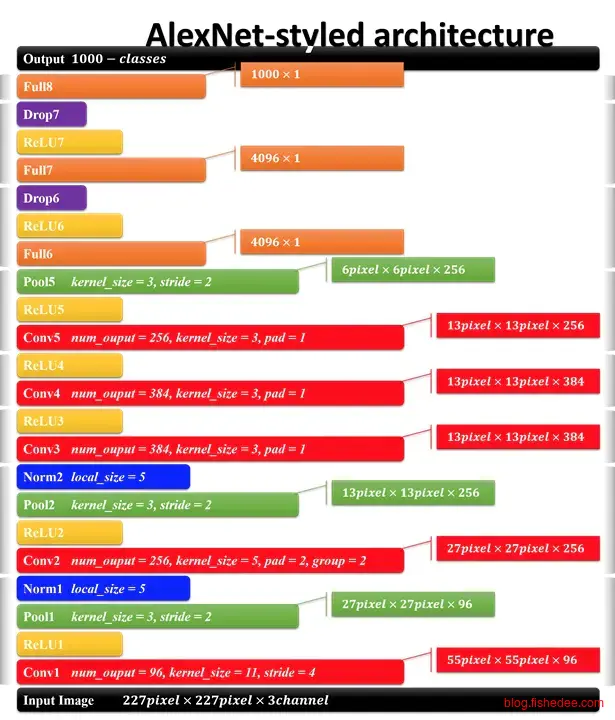
结构为:
- 224x224的输入层
- 96个11x11卷积层,和最大池化层,以及正则层
- 256个5x5卷积层,和最大池化层,以及正则层
- 384个3x3卷积层
- 384个3x3卷积层
- 256个3x3卷积层,和最大池化层
- 4096个全连接层,和dropout层
- 4096个全连接层,和dropout层
- 1000个全连接层
AlexNet直接刷新了ImageNet的识别率,奠定了深度学习在图像识别问题上优势地位,其主要优化在于
- 网络够深,5个卷积层和3个全连接层
- 使用relu激活函数,收敛很快
- 加入了正则层和dropout层,防止过拟合
- 使用数据提升,将数据随机平移变化来增强泛化能力
- 分块训练,当年的GPU没有这么强大,AlexNet创新地将图像分为上下两块分别训练,然后在全连接层合并在一起。
总体的数据参数大概为200m
2.2.3 NetworkInNetwork
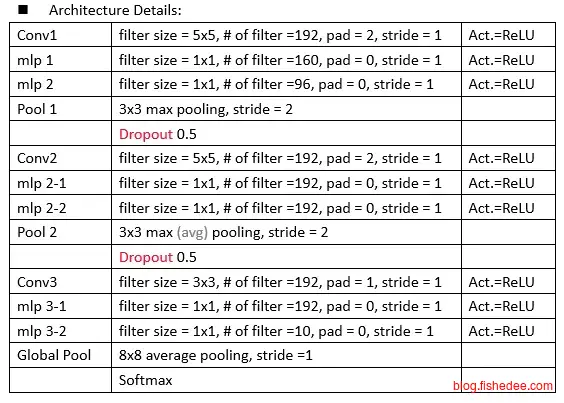
结构为:
- 224x224的输入层
- 192个5x5卷积层
- 160个1x1卷积层
- 96个1x1卷积层,和最大池化层,以及正则层
- 192个5x5卷积层
- 192个1x1卷积层
- 192个1x1卷积层,和最大池化层,以及正则层
- 192个3x3卷积层
- 192个1x1卷积层
- 10个1x1卷积层
- 全局平均池化层
NetworkInNetwork继续进一步刷新了ImageNet的识别率,带来了很多创新的思路,其主要优化为:
- 网络很深,9个卷积层和0个全连接层
- 引入1x1卷积层,代替了原来的全连接层,这个1x1卷积层不仅降低了需要训练的参数量,还让逻辑分类操作从最后一层提前到前面的层,实现非线性的特征提取能力,相当于做了一个局部像素的全连接层,相当神奇。
- 引入全局池化层,简化了原来的全连接层。
2.2.4 VGG19
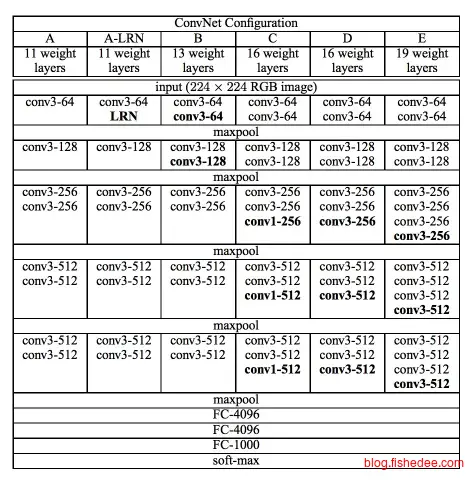
VGG19开拓了没有最深,只有更深的想法,高达16层的卷积层和3层的全连接层,太恐怖了。当然,VGG19也很牛逼,比NIN还要高的识别率,同时也是目前最常用的fine-tune模型。其主要优化为:
- 网络超深,16层的卷积层和3层的全连接层
- 全3x3的卷积层,它用实验表明,与其用大的卷积核来提高卷积的感受范围,还不如使用单一的3x3的卷积核叠加来实现,这样效果更好。
2.2.5 GoogleNet
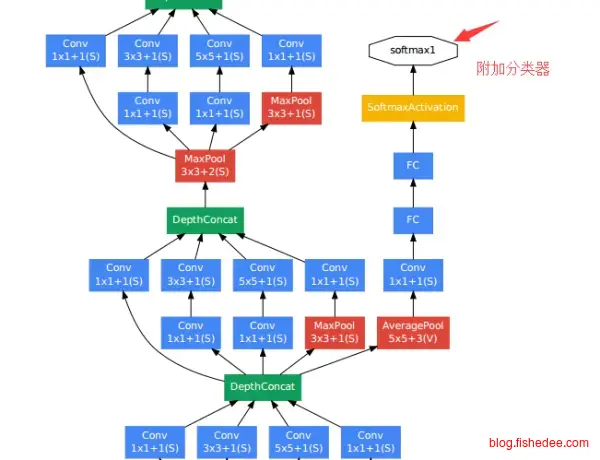
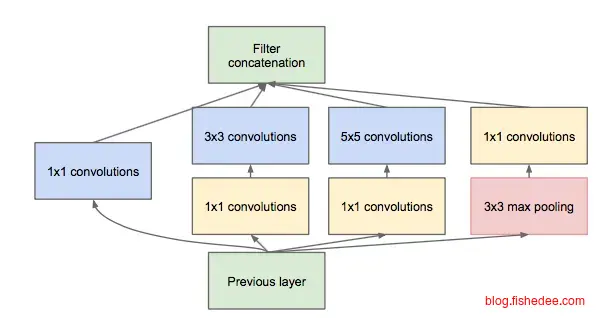
GoogleNet是NIN的改进,它认为单一3x3的卷积核层叠会使得卷积无法做到尺度不变的感受。所以,它的主要改进为:
- 输入层并行多个卷积层,每个卷积层的卷积核大小都不一样,这样就能使得每一层次的感受都能让网络适应不同的尺度,并行多个卷积层后再用一个concat操作将多个输出并起来。
- 使用1x1卷积核降维和非线性分析,这里主要是借鉴了NIN的想法,在3x3和5x5卷积核之前先套入一个1x1卷积核降低参数量,并且实现非线性分析。
- 中途附加分类器,为了避免梯度弥散和爆炸的问题,GoogleNet创新地在中途网络加入分类器,让误差能从中途插入到网络中,从而解决这个问题。
2.2.6 ResNet
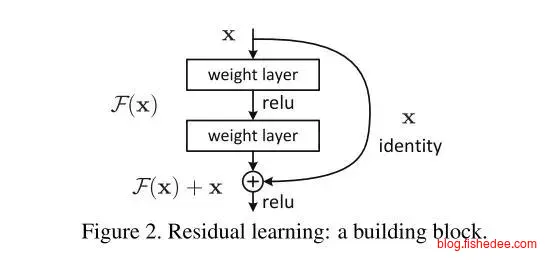
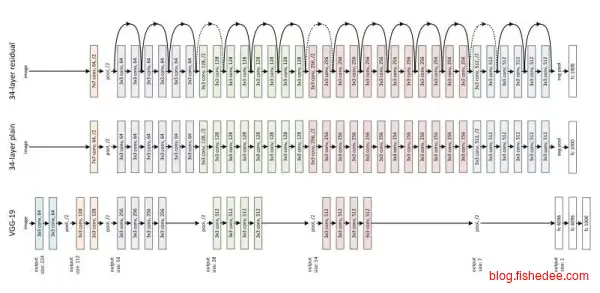
ResNet是VGG的改进版本,它认为原来的卷积方式已经足够牛逼了,分类器性能上不去的主要原因还是层数太少,而层数太多网络就很难训练,所以解决超深网络的训练问题才是关键。它创新性地加入了Skip-Connection来将梯度跨层反向传播回去,这一个改进让它横扫2015几乎所有的视觉识别模型。模型深度高达惊人的152层,目前甚至已经有1000层的ResNet被训练出来了!它的改进主要为:
- 使用Skip-Connection将梯度反向传播到前面的层,大大提高了可训练卷积层的深度。
2.2.7 Xception
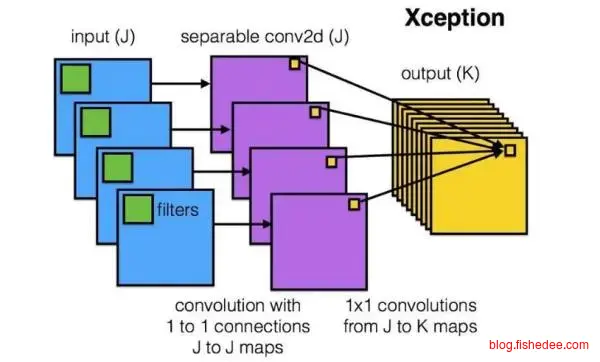
Xception是GoogleNet的进化版本,它认为NIN提出的1x1卷积核其实就是将传统的3x3卷积核的非线性输出和卷积两个操作分离了,只进行了非线性输出,不卷积操作而已。那么,有没有只进行卷积操作,不进行非线性输出操作呢?Xception的答案就是可分离卷积核。它首先对每个通道进行自己独立的卷积操作,不进行非线性输出操作,然后将特征图进行1x1卷积核操作。
实践证明这样的方法,不但减少了参数量,而且泛化性能更强。在imagenet 1000中,Xception比GoogleNet的参数要少,但效果要更好。基于可分离卷积核(DepthWise Convolution)的想法,Google提出了针对手机的MobileNet,实现了实时性的深度学习识别。
2.2.8 DenseNet
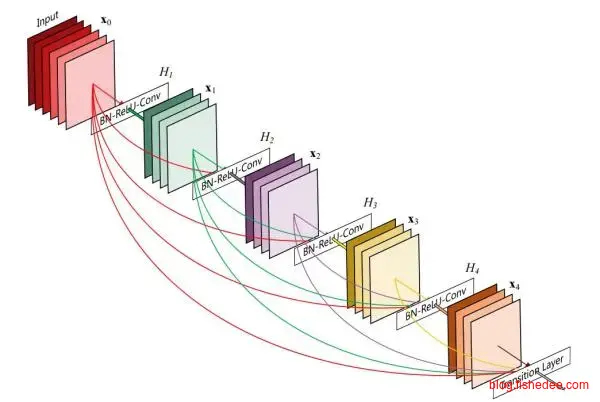
DenseNet是对ResNet的进一步优化,ResNet的跨层连接仅仅是为了反向传递梯度,DenseNet认为跨层连接更能提高泛化能力。所以,它将每一层的输出到连接到后面每一层的输入上,实践这样,这样的网络的确能提高泛化能力,但其主要的问题是权重的指数增长,导致GPU的显存根本不够用。
2.3 相似匹配
相似匹配就是图像检索的实现,常用于相似人脸检测,以图搜图等场景
2.3.1 VGG
在数据充分,标签少的情况下,将相似匹配问题转换为分类问题就可以了。例如,要做一个明星人脸检索系统,数据集中已有100个明星,每个明星都有100张各个环境下的人脸照片。然后,我们可以直接套用VGG网络,逐个照片放进去做softmax分类,分类的结果就是明星的名称。
那么,经过这样训练得到的网络后,我们可以认为cnn层提取出来的都是人脸特征信息,具有分辨人脸特征的信息。因此,扔掉VGG的全连接层,只保留卷积层,将每个明星的人脸在卷积层输出的信息作为特征指纹放到数据库中。当需要搜索人脸时,就先将搜索人脸放入同一个卷积层中提取特征指纹,然后再在数据库中搜索就可以了。
总体来说,它的思路是:
- 使用分类模型来训练出人脸特征指纹提取器
- 将特征指纹存放到数据库中,检索时使用kNN算法来检索出最接近的图像
2.3.2 Siamese
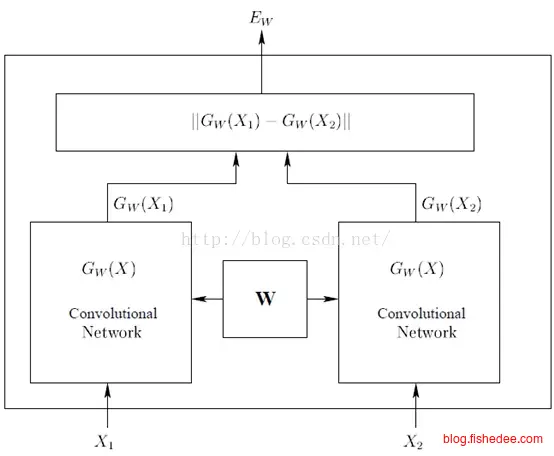
分类模型的主要问题是,需要每个分类中的数据集足够多,不然容易过拟合。Siamese网络从另外一个角度来解决这个问题,做相似匹配的关键是训练出特征提取器。Siamese网络的输入是两张图片,X1和X2,他们都进入了共享权重的卷积层提取出特征\(G(X_1),G(X_2)\),然后接入一个Lambda层,这一层就是算出这两个特征向量的欧式距离\(D(G(X_1),G(X_2))\)。
然后,我们将输入数据集打乱,以任意配对的两幅图像放入网络中,显然,训练时我们是知道这两幅图片是不是相同标签的。注意,这个网络跟普通的神经网络不一样,它不会直接输出图片是否相似,而只会输出这两幅图片的特征向量的欧式距离。
那么,我们的Loss的距离应该怎么设计呢?显然的是,我们的目标是,同一标签的两幅图像输入后,输出的欧式距离应该尽可能小,不同标签的两幅图像输入后,输出的欧式距离应该尽可能大。
\[ Loss = \begin{cases} D(G(X_1),G(X_2)),相同标签时\\ \max\{0,1-D(G(X_1),G(X_2))\},不同标签时\\ \end{cases} \]
所以,Loss可以如上面方程这么设计,不过一般我们都会使用像crossentory的方法来组合两个case。
总体来说,它的思路是:
- 使用相似模型来训练出特征指纹提取器,将图像随机分成相同标签和不同标签两个pair放入网络中,通过loss来调整特征指纹提取器
- 将特征指纹存放到数据库中,检索时使用kNN算法来检索出最接近的图像
2.3.3 2-channel
2-channel网络是Siamese的进化版,它的主要改进是,将提取特征和比较特征都放在一个网络中做,这样的话精度比较高,但是就无法像Siamese一样将特征指纹存放到数据库中任意检索。
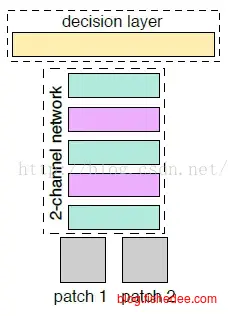
2-channel网络的第一个改进是,将两幅图像看成是双通道的单一图像放入到网络中,网络的前半部分都是卷积层,后半部分是全连接层,输出是sigmoid,指出这两幅图片是否相似。训练时就很简单了,扔图像对进去,根据是否相同来调整。另外,注意图像的特征比较过程在卷积层就已经执行了,而不只在全连接层。
训练好这样的网络后,检索图片时需要这样做。把待检索的图片与数据库的所有图片构成一一图像对,然后放入神经网络中,由神经网络告诉我们它们的相似度是多少,然后按相似度从高到低排序就可以了。注意这里跟Siamese的做法完全不一样,这里的时间复杂度要高很多。
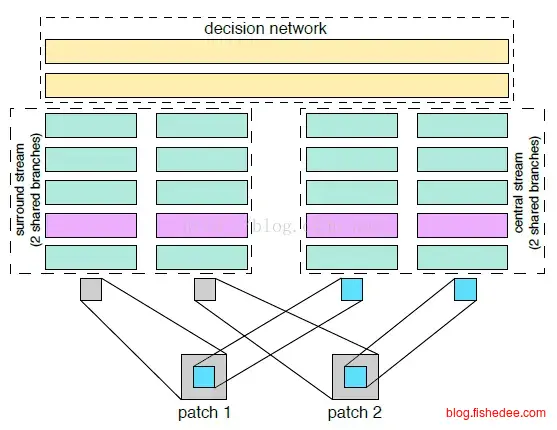
2-channel网络的第二个改进是,Central-surround two-stream network。就是输入时,不仅输入整张图片,还放入图片对中间crop的部分。这样做的原因增加网络的鲁棒性,相当于在神经网络层做数据增强。
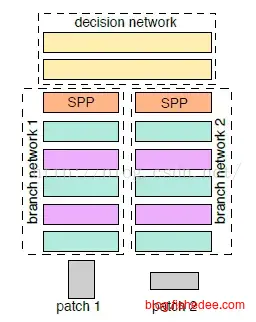
2-channel网络的第三个改进是,在卷积层的末尾使用空间金字塔池化SPP,这个优化的重点在于输入图像不再需要调整为同一尺寸后再输入了。因为SPP在池化时会将卷积层数据池化到同一个大小的特征向量中。
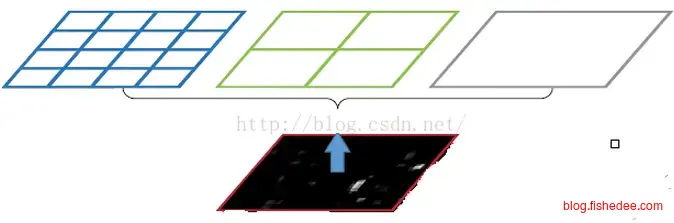
SPP池化层的想法其实很直接,以前池化核的大小不都是2x2,4x4这样固定的么,我把它改为根据图像宽高自适应变换不就好了。例如,我要做三层的池化,首先是整个图像所有像素做一个池化操作,然后是整个图像划分为4份再在每份上做一个池化操作,最后是整个图像划分为16份再在每份上做一个池化操作,那么第一步输出1个数值,第二步输出4个数值,第三步输出16个数值,一共31个数值,这31个数值就是池化层的输出了。而且31这个数字显然对任意的输入图像都是一样呀,那么,经过SPP池化层后,就可以接入固定尺寸的全连接层了。
总的来说,2-channel实用意义不大,它把特征比较这一步也做了,使得无法在数据库上实现快速检索图像的能力,得不偿失呀。不过它的Central-surround two-stream network和SPP倒是可以借鉴一下。
2.3.4 LSH哈希
LSH哈希是VGG相似匹配的改进版本,为了加快在图像在数据库上的检索实现的。原来检索图像时需要在数据库上执行kNN操作比较慢,不够快。LSH哈希的想法是在卷积层后面接入一个降维层,降维为128维的特征哈希,降维层后面才接全连接分类层。那么训练时就跟原来的方法一样训练就可以了。
建立索引时,将图像集的cnn特征向量,和特征哈希(特征哈希都按照四舍五入的原则转化为01编码就可以了)都存放到数据库中。检索时先检索特征哈希相同的图像,然后再在这少量的图像中执行kNN算法,从而大大提高了搜索的速度。
当然,特征哈希的引入会降低搜索的精度了。
2.4 目标定位
2.4.1 RCNN
预测方法
- 使用Selective-Change找到候选区域,大约有2000个候选区域
- 对每个候选区域使用训练好的CNN网络提取特征向量
- 对每个候选区域的特征向量使用SVM做分类,同时扔掉那些没有分类的候选区域
- 合并同一个分类的相邻候选区域,并且使用全连接网络来回归精修位置。
训练方法
- 使用Selective-Change找到候选区域,候选区域的选择为相似颜色,相似纹理,合理形状等等,这是一个无监督的方法。
- 训练使用CNN特征提取器的方法,首先使用CNN接上全局分类器训练来初始化权重,然后用CNN后面接上局部区域分类器来微调权重。
- 训练SVM,每个种类一个SVM分类器来用局部区域分类器来训练SVM。
- 训练位置精修回归器,在CNN后面接上回归器来训练精修权重。
不得不说,这是个很dirty的方法,而且还慢,不过它是首个使用CNN来做目标定位的方法。慢的主要原因是每个候选区域都需要做一次CNN特征提取。
2.4.2 SPPNet
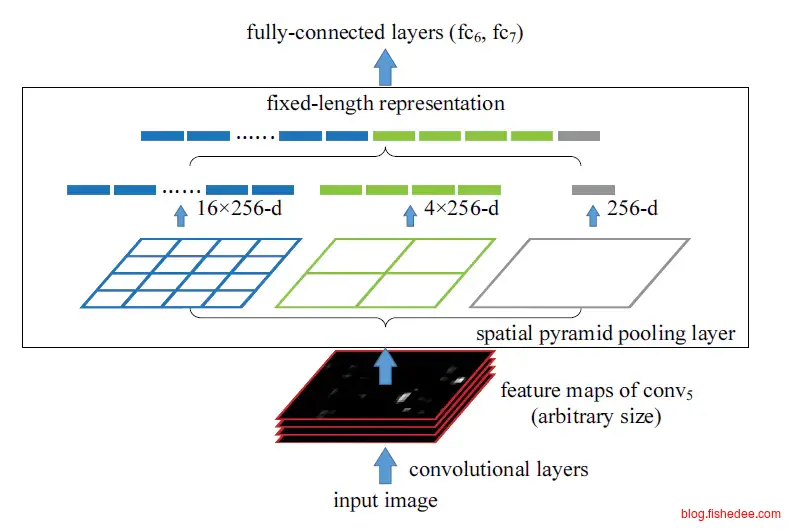
SPPNet的主要改进在于,加入一个空间金字塔池化层,来让任意图像都能输出一样的池化层。原来在训练CNN时,由于候选区域都大小都不一样,候选区域需要先放缩都同样大小后,然后每张图都走一遍CNN才能取到一样的特征向量。
但是有了SPPNet以后,我们先将整张图进行所有的卷积操作,然后在卷积层上取候选区域对应位置的卷积结果,然后执行一次空间金字塔池化层,就能得到原来所有候选区域一样的特征向量。换句话说,我们从原来的每个候选区域取一次CNN,变成整张图取一次CNN,然后每个候选区域取一次空间金字塔池化层。就可以了,大大减少了计算量。
预测方法
- 使用Selective-Change找到候选区域,大约有2000个候选区域
- 对整张图做一次CNN网络提取卷积向量,每个候选区域根据位置取对应的卷积向量做空间金字塔池化层,得到每个候选区域的特征向量。
- 对每个候选区域的特征向量使用SVM做分类,同时扔掉那些没有分类的候选区域
- 合并同一个分类的相邻候选区域,并且使用全连接网络来回归精修位置。
SPPNet大大提高了训练和预测的速度,而且并没有太多的精确度损失。可是SPPNet仍然离不开多阶段操作,一次取候选区域,一次取特征向量,一次用SVM分类,最后一次回归位置,实在麻烦而且dirty。
2.4.3 Fast-RCNN
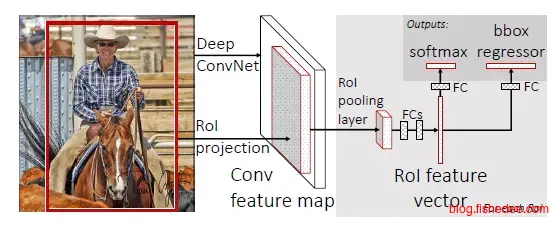
Fast-RCNN的主要优化在两点
- 不再使用SVM做分类器,而是用两个全连接层分别做分类器和位置回归,多任务一起训练后,全连接层分类器比SVM更准确了。
- 用ROI pooling代替SPPNet,这是一个简化版的SPPNet,SPPNet是多尺度的池化层。例如SPPNet整图,半图,四分之一图各做Pooling,而ROI pooing层则暴力地只提取四分之一图做Pooling。
预测方法
- 使用Selective-Change找到候选区域,大约有2000个候选区域
- 对整张图做一次CNN网络提取卷积向量,每个候选区域根据位置取对应的卷积向量做ROI pooling层,得到每个候选区域的特征向量。
- 对每个候选区域的特征向量使用两个全连接层,同时输出分类和位置静修。
Fast-RCNN比SPPNet快了一点点,而且去掉了SVM分类器,整体阶段少了一次。可是仍然需要一次Selective-Change的运算。
2.4.4 Faster-RCNN
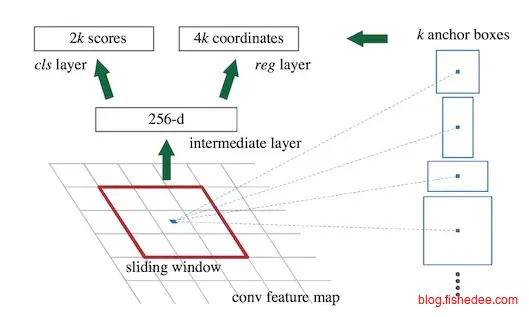
Faster-RCNN是Fast-RCNN的改进,其主要的改进为将Selective-Change改为Region Proposal Network(RPN)。首先,整张图片依然是直接放入cnn,然后cnn的最后一层卷积层中,每个点会对应原图的某个范围,例如由于输入图像M=800,N=600,且Conv Layers做了4次Pooling,feature map的长宽为[M/16, N/16]=[50, 38],也就是每个feature map的点相当于原图的16x16的大小。
然后,以每个点作为中心点,生成k个锚点,代表以该中心点附近的k个范围,正方形,竖长方形,横长方形等等。就这样,每个锚点生成两个输出,一个输出为单分类,是否含物体,第二个输出为物体的具体位置。
例如,如果最后一个卷积层是(128,32,32),代表128个特征层,32x32的大小。设每个点生成m个锚点,那就是共(m,32,32)个分类输出,(4m,32,32)个精修位置输出。最后,代入已经训练好的数据,我们就能训练好这个RPN网络了。
要注意的是,这个RPN的网络输出与Fast-RCNN是共享CNN的特征提取层的,唯一不同就是RPN在特征提取层外加入了位置精修和是否含物体的输出而已。整体来说,RPN是个全卷积网络,利用了在卷积层上可以做滑动窗口的神奇想法,大幅提高了依赖cpu的Selective-Change操作,十分牛逼。
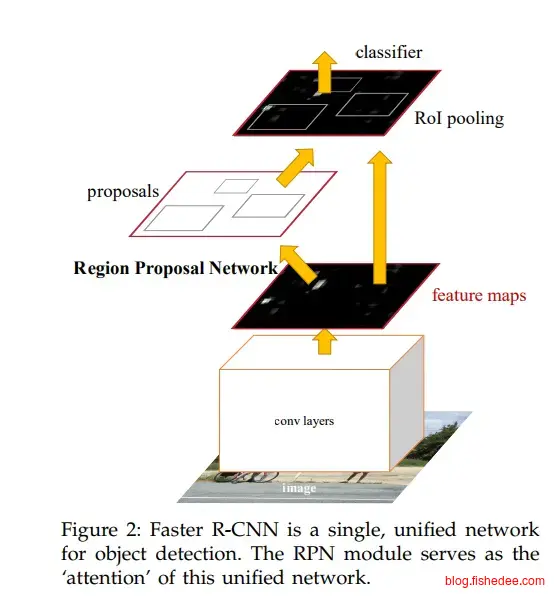
Faster-RCNN的其他操作则与Fast-RCNN是一样的。预测方法为:
- 对整张图做一次CNN网络提取卷积向量,然后接入RPN网络输出候选区域,然后提取候选区域的前300个就可以了
- 每个候选区域根据位置取对应的卷积向量做ROI pooling层,得到每个候选区域的特征向量。
- 对每个候选区域的特征向量使用两个全连接层,同时输出分类和位置精修。
几乎为end-to-end的训练方法,而且速度快得吓人。但是美中不足的是需要分别训练RPN网络和Fast-RCNN网络,并且对小物体的识别不太足够。因为在卷积层上做滑动窗口操作时,每个点所对应的图像太大了,信息量太多。
2.4.5 YOLO
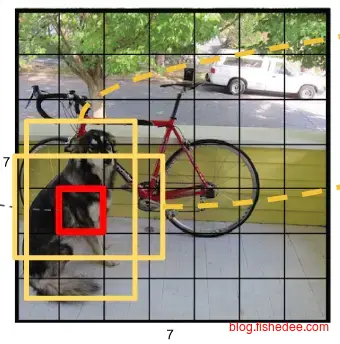
YOLO的想法和Faster-RCNN已经很接近了,只不过Faster-RCNN的RPN是用Anchor-Box来预测分类和位置精修,YOLO是用全连接层来预测分类和位置精修。所以Faster-RCNN的RPN是全卷积网络,可以输入不同尺寸的图像,而YOLO则需要输入固定尺寸的图像。
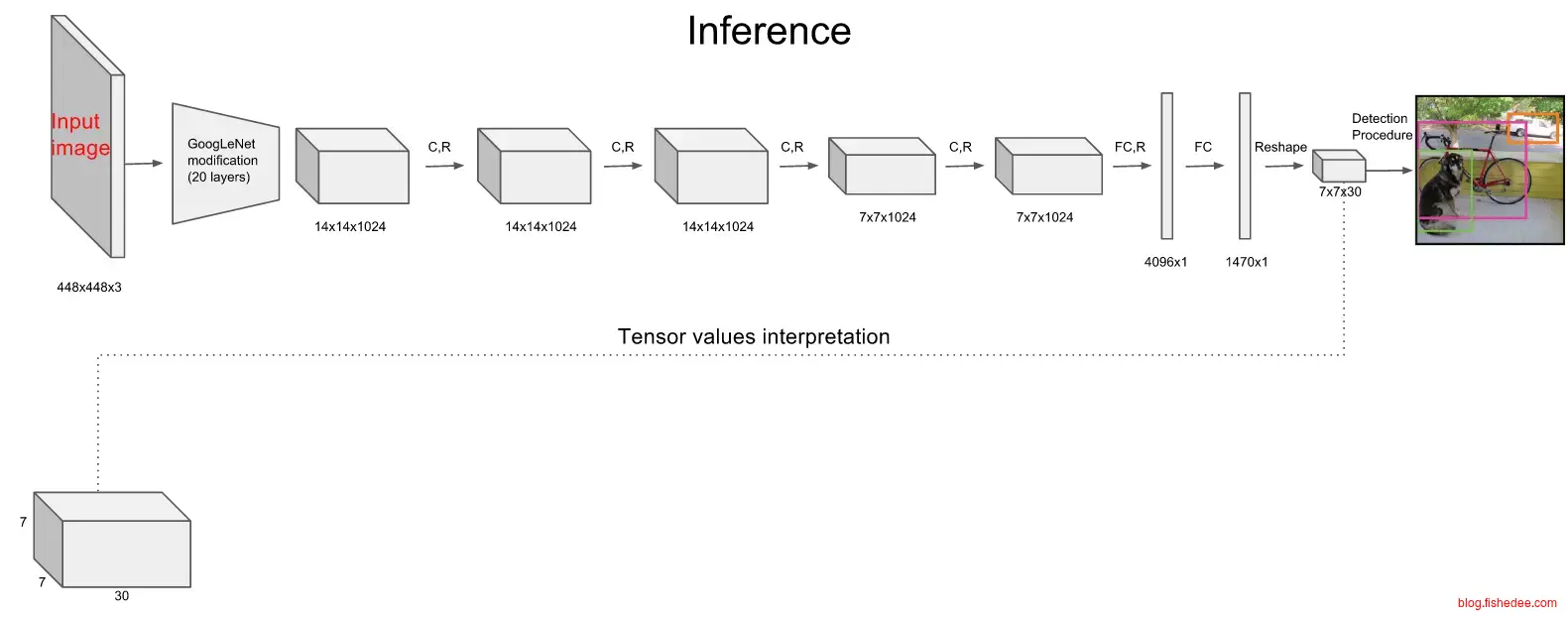
首先,YOLO将图像统一到448x448的尺寸中,然后输入到预训练好的GoogleNet中得到14x14x1024的数据,然后接入4个卷积层和2个全连接层,得到7x7x30的数据输出。
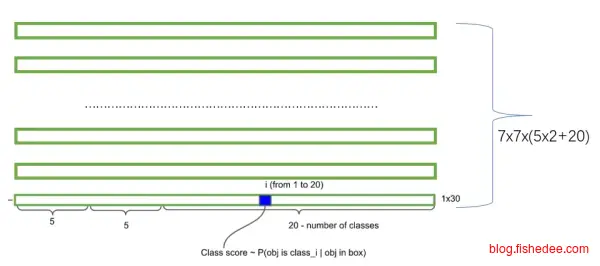
7x7x30代表的是,整个图像分为7x7共49个区域,每个区域包括2个bounding box(图中黄色实线框),bounding box的信息有(x_center,y_center,w,h,confidence),剩余的20维度信息就是20个分类的概率信息。
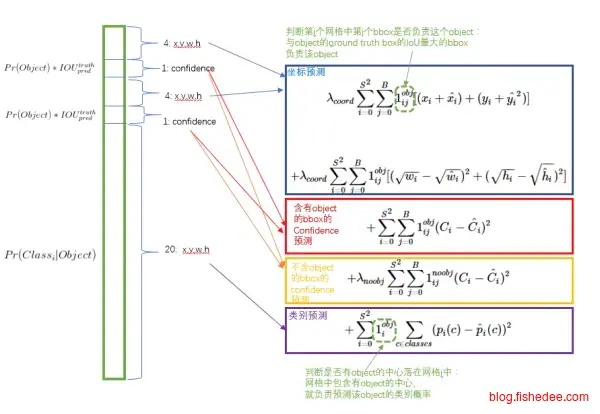
Loss的设计如上图所示。YOLO是第一个End-To-End的目标定位的模型,检测速度较快,不过精度就真的比较弱了。
2.4.6 SSD
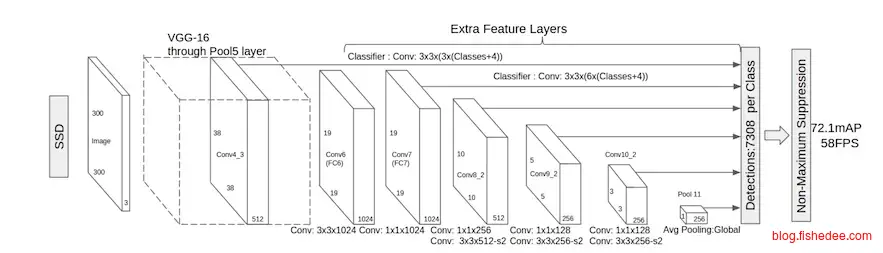
SSD是为了速度和性能而来的超强框架,它的想法是,既然RPN网络本身就能输出单分类,和位置精修,为什么RPN网络不直接连多分类和位置精修都做了,根本不需要Fast-RCNN网络的参与呀。
另外,对于每个anchor点,不仅连接最近一个卷积层的信息,还连接前面一个卷积层的信息,甚至是第一个卷积层的信息,这样就能解决小物体识别的问题了。就这样,SSD诞生了。
SSD只有一个神经网络层,同时输出多分类和位置精修信息。速度超快,位置也准确。
2.5 语义分割
=,=,这里的模型基本都看得不太懂
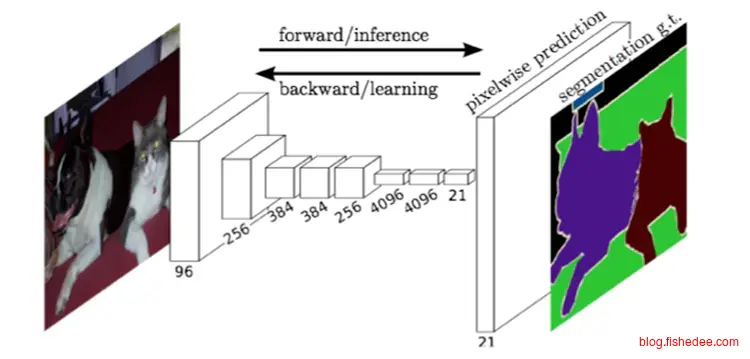
2.5.1 FCN
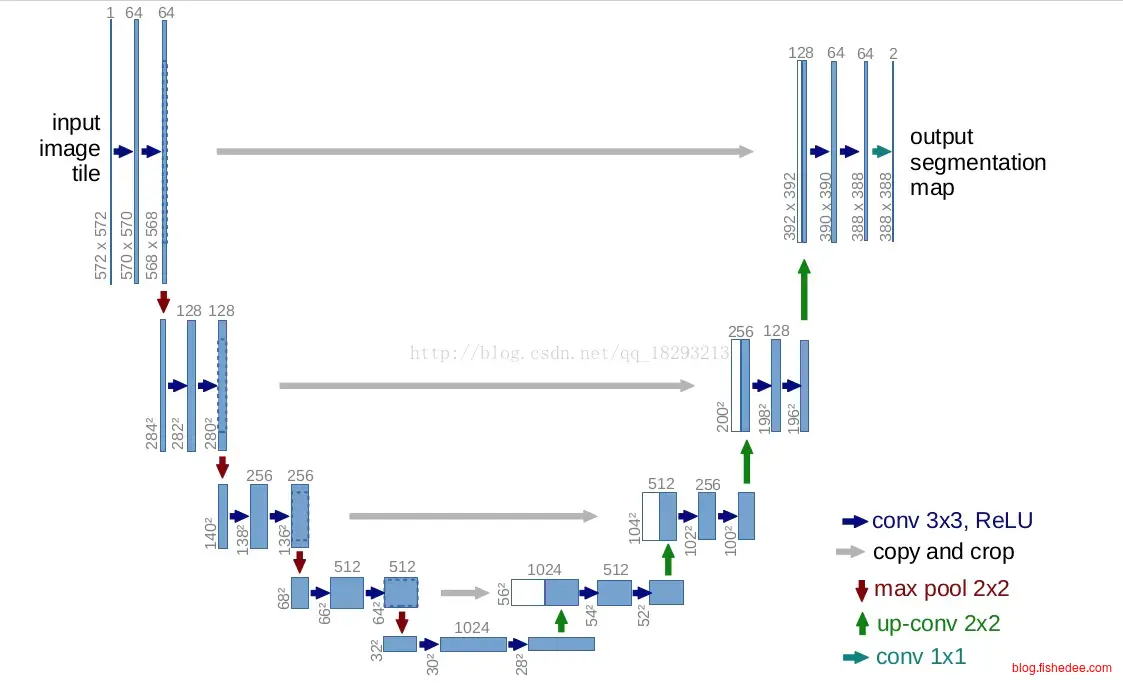
2.5.2 U-Net
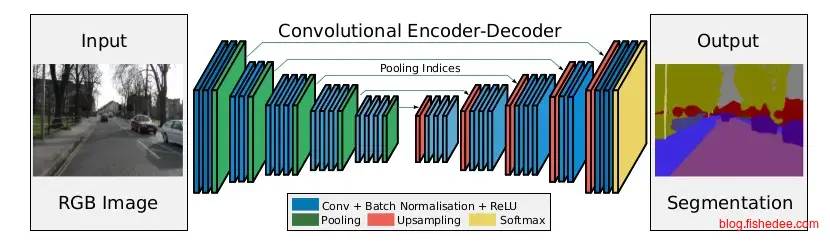
2.5.3 SegNet
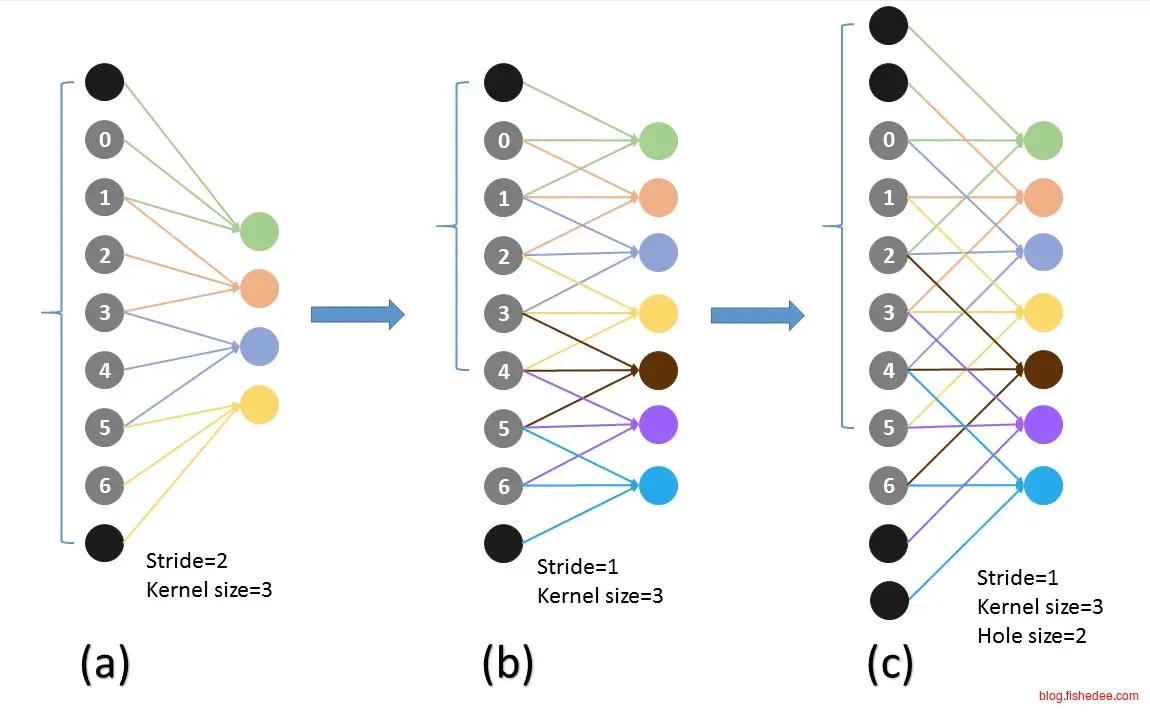
2.5.4 DeepLab
2.5.5 Mask-RCNN
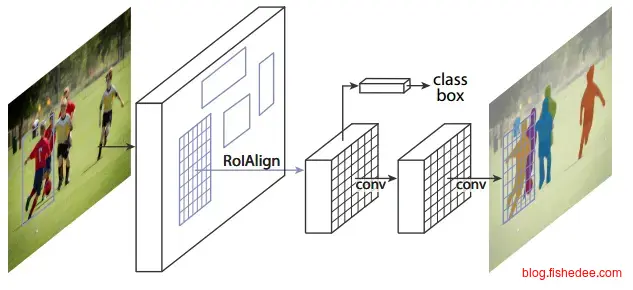
http://blog.csdn.net/yang9649/article/details/74691192
2.6 随机生成
2.6.1 VAE
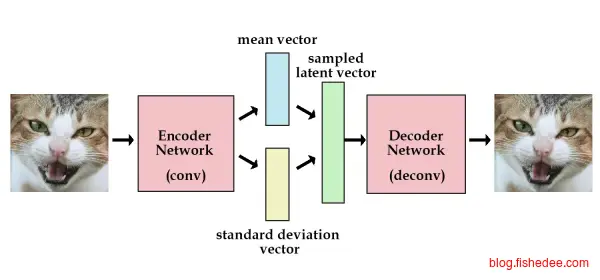
变分自动编码机,在《深度学习概览》就说过了
2.6.2 GAN
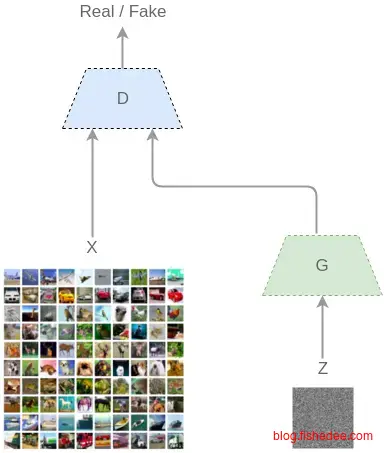
通过让两个神经网络左右互搏的方式来生成图像,逼真度比较高
2.7 语义生成
2.7.1 cGAN
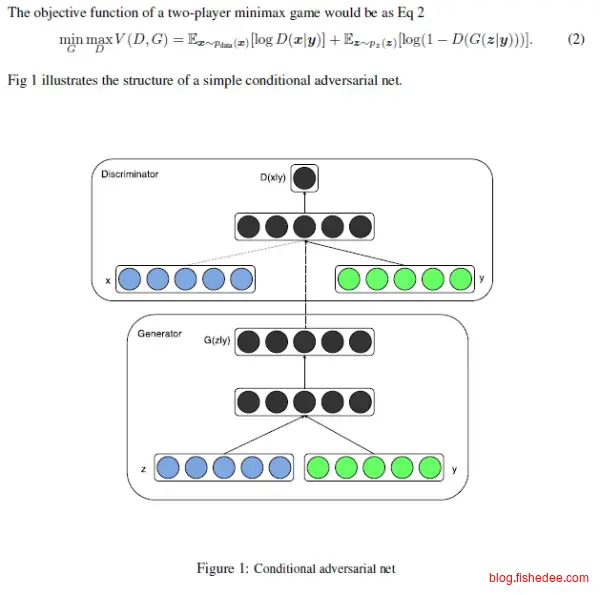
让GAN加入先验信息,使得生成网络可以按照我们需要的条件来生成数据。
2.8 变换
2.8.1 AE

AE可以用来做去噪,AE输入的是经过噪音污染后的图像,输出的是原来的图像,经过多轮训练后,AE就学到了特定噪音污染的去噪处理,相当神奇。但是,这种方法只对相当有规律的噪音有效。
2.8.2 pix2pix

pix2pix其实是cGAN的图像版本,在已经有一一对应的标注样本数据下,pix2pix能学习到输入图像到输出图像的映射。
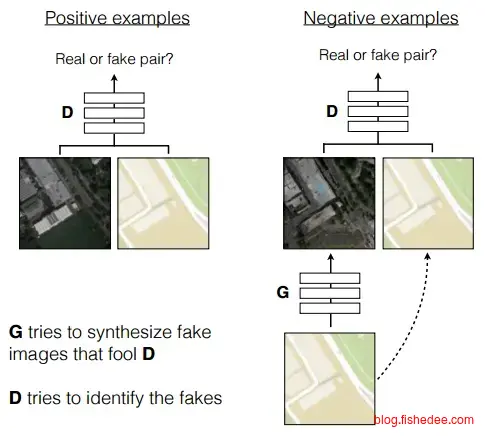
pix2pix的整体结构,跟cGAN差不多,输入是原图像,经过生成网络转换为Fake图像,然后用已有的Real图像来训练判别网络,判别网络训练好后再单独训练生成网络,不断重复这个过程就可以了。
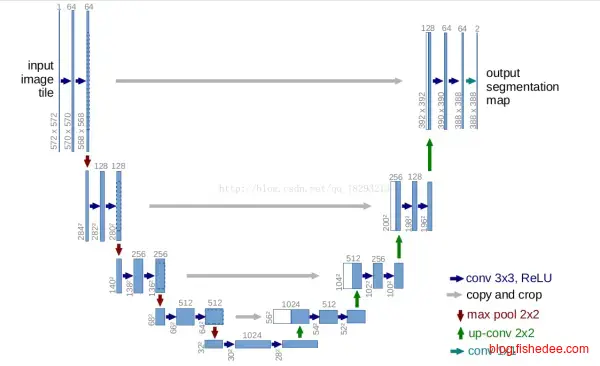
pix2pix的主要亮点在于它的生成网络使用的是U-Net结构,一个能很好地重用低层特征和高层特征的结构。判别网络就是简单的四层卷积层。
pix2pix可以说是非常强大的图像变换结构了。
2.8.3 CycleGAN

CycleGAN是pix2pix的更进一步,输入的样本不再需要是一一标注的,只需要两类样本就可以了,网络会自己寻找到它们之间的映射。例如,我有一堆苹果的图片和一堆橙子的图片,我希望找到苹果图片转换为橙子图片的映射。但是我手上并没有苹果和橙子的一一对应映射对,是无法用pix2pix来训练的。
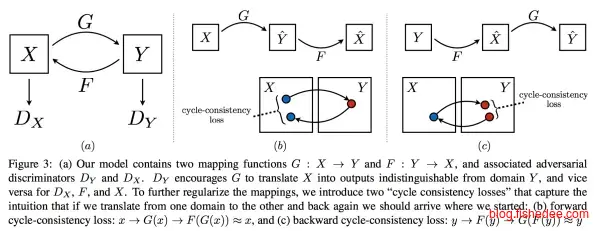
CycleGAN的思路是通过建立两个GAN网络来实现的,其中有个巧妙的loss设计是,两层映射以后必须要映射回自己本身。具体的在《深度学习概览》中已经说过了。
2.9 文字识别
2.9.1 CNN+Mutlitask
这是CNN的经典结构,一个输入(图像),一个输出(各分类的概率)。但是在文字识别的环境下,我们输入的是一整张图片,输出的是多个文字。一个很直观的办法是让CNN改为Mutlitask学习,一个输入(图像),多个输出(第一个字的分类,第二个字的分类等等)。这样做的话多个输出是共享一个特征层的,多任务一起学习,效率和速度都不错,只是这样就只能让应付输出数字的个数是固定的场景了。
2.9.2 LSTM+CTC
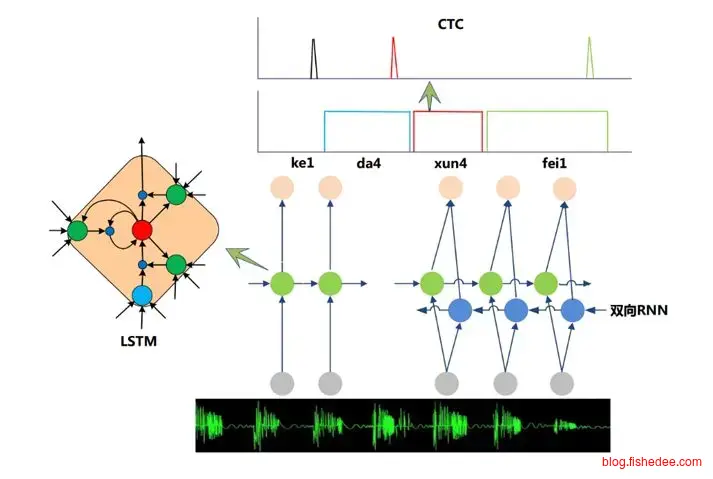
LSTM+CTC是将语音识别的解决方案迁移到文本识别来。首先,将整个图片输入到lstm层,一列看成一个单词,图片有N列,就会被看成N个单词,然后这列的像素就看成是这个单词的描述。另外,lstm层设置为return_sequence=True,也就是每个单词都输出一个softmax,代表这个单词归属于哪一类。在ocr的问题上,就是图片的每一列都输出各个文字的类别概率。注意,输出的类别中需要增加一个Blank类别,代表空白无输出。
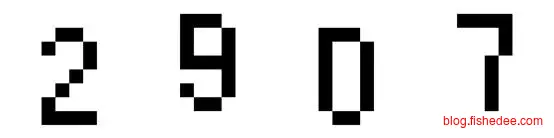
现在,假设我们要识别图片为上图,并假设这个图片就只有10列(实际上肯定不止,这张图片宽度至少50了),那么神经网络的输出为一个矩阵,宽度为10(代表有10列),高度为11(代表0~9十个数字,与Blank组合起来一共11个类别),矩阵中的每个元素代表这个位置输出的类别的概率。
那么,有了这个输出矩阵以后,我们怎么求出输出的序列是2907,而不是22907呢?首先,我们将矩阵中每列最大概率的类别留下来,该列其他的类别扔掉,我们就能得到一个长度为10的序列。如果它的最大输出概率序列如下:
\[ -22299-0-7 \]
那么,我们将重复数字合并为一个,并且将空格扔掉,就会得到最终序列2907。
如果它的最大输出概率序列如下:
\[ -22-2990-7 \]
我们就会认为最终的输出序列为22907。
就这样,我们找到了一种方法,输出的数据永远是T的长度(在这个例子中是10个),但对应的序列长度是任意长度的。好了,我们讲完了在已知网络训练好后,怎么从输出中获取序列的问题后,我们来讲如何训练这个lstm网络。
训练这个网络的关键在于,求解输出矩阵的loss。我们求解的方法称为ctc loss。首先,将目标序列(长度为L)扩增,在重复字的中间都插入一个blank,扩增后序列的长度为L’。例如,目标序列是2907,那么扩增后的序列依然为2907,但目标序列是2007时,那么扩增后的序列为20-07。
然后我们将扩增后的序列,通过任意重复字,和插入blank的方式来达到T的长度。例如,2907可以扩增为以下序列:
\[ 22222222907 -2222222907 2222222-907 ... \]
这个时候二次扩增的序列长度已经和输出矩阵对齐了,就这样我们求出每个扩增序列的出现概率然后相加,得出的就是,输出矩阵中表达的是目标序列时它的概率是多少。那么这个loss的设计就很简单了,就是1-P就可以了。
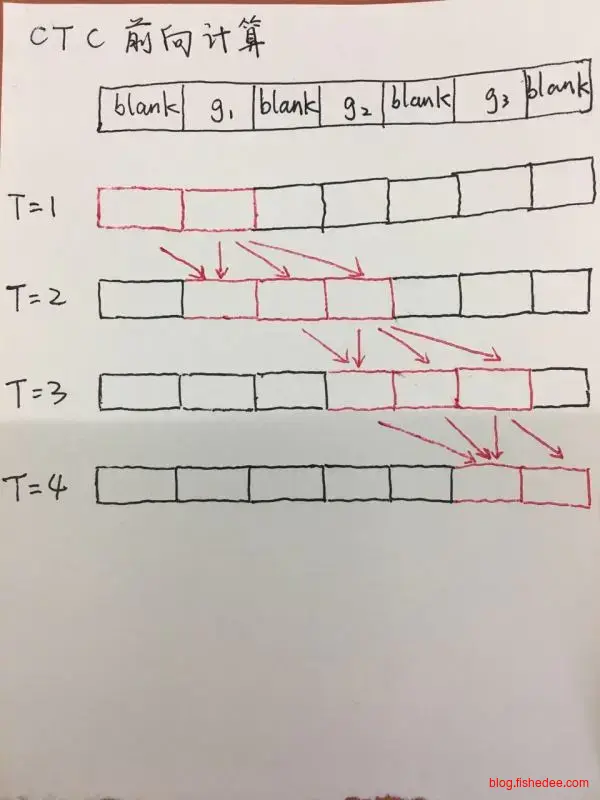
不过这种通过扩增目标序列对齐求概率的方法比较慢,需要穷举目标序列的所有扩增可能性。更好的办法是使用动态规划来优化这个时间复杂度,并根据剩余的步数来剪枝,这种新的办法就是wrap-ctc了。
ctc loss的概率求解思路其实很像hmm的概率计算呀,ctc可以用在任意的序列分类识别的问题上,它是实现语音识别中End-To-End的关键步骤。
2.9.3 CTPN+CRNN
CTPN+CRNN是一套完整的自然图片ocr识别系统
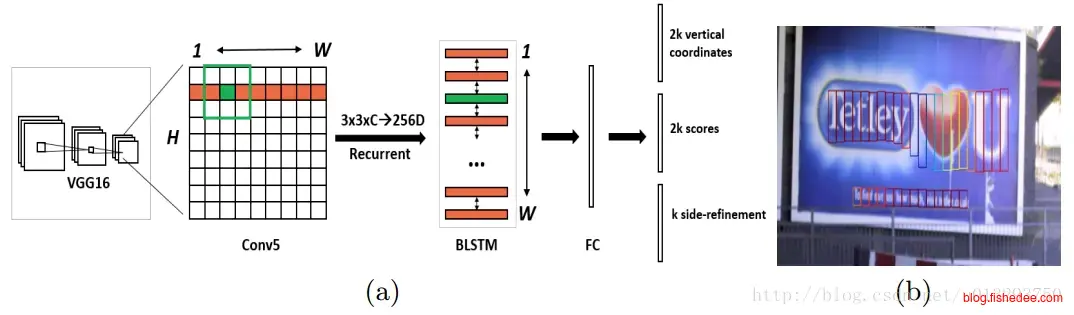
首先,CTPN网络是文字检测网络,网络首先通过VGG提取特征,然后经过双向lstm,生成anchor box。相当于Faster-RCNN的RPN网络,不过多了lstm的那一层。

经过这一层后就得到很多的文本框


使用nms重叠的文本框,并将相邻的文本框以特定的规则合并起来,就能得到一个大的文本框。在这里CTPN已经能够提取出一个个的文本框了。
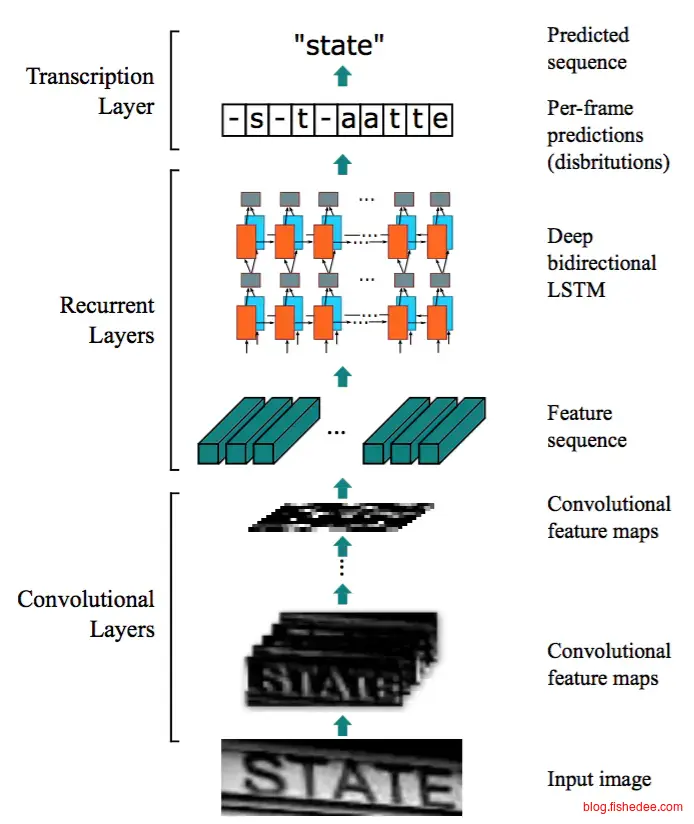

CRNN就是CNN+RNN+CTC的合并方法了,没什么好说的,就是在之前的LSTM+CTC的基础上加上了CNN预提取特征,识别率目前是最高的。
3 语音处理
3.1 预处理
对于语音来说,一般先用傅立叶变换为频域图,然后归一化再扔进去神经网络中训练就可以了。
3.2 识别
3.2.1 LSTM+CTC
3.2 生成
3.2.2 WaveNet
4 文本处理
4.1 预处理
4.1.1 向量化
对于自然语言来说,深度学习还是比较头疼。不像图像和语音,每个采样点都是一个连续量。自然语言的输入都是字母或者单词,这些单词不是连续量,是离散量,我们直接将单词转换为utf-8编码扔进去神经网络是有问题的。因为对于神经网络来说[20105]和[20106]是两个相近的数字,它们是的输出应该是差不多的,但是在utf-8编码中20105的意思是“我”,20106的意思是“戒”,两者完全没有关系。
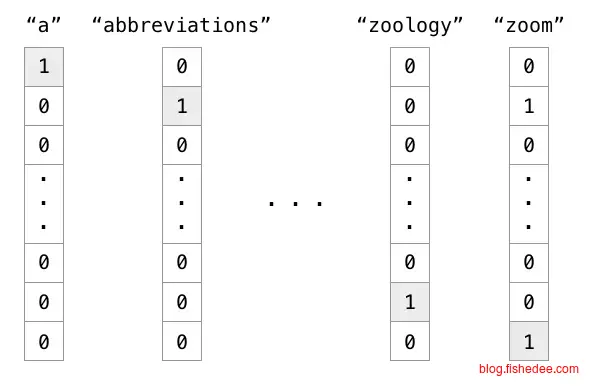
所以,对于输入神经网络的数据是离散量时,应该采用one-hot编码,例如有个枚举量代表浏览器型号,可选类型为[“Firefox”,“Chrome”,“Safari”,“Internet
Explorer”]时,代表Firefox的输入编码应该为[1,0,0,0],代表Chrome的输入编码应该为[0,1,0,0],代表IE的输入编码应该为[0,0,0,1],以此类推。由于输入时位置都不一样,固不同的枚举神经网络不会认为是相近的东西。对于文字而言,“我”的编码应该是[0….1….0],1的位置在第20105个,而”戒”的编码应该是[0….1….0],1的位置在第20106个。但是,这种编码的缺点也很明显,就是过于稀疏,数据太大了。
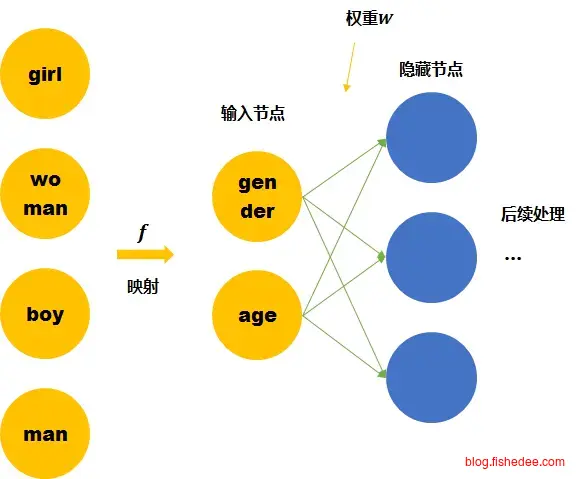
解决这个问题的办法寻找文本之间的相似性来实现降维,虽然文字本身是个枚举量,两两之间应该是零关联。但是像“喜欢”和“喜爱”这个单词就是相近的意思,“早餐”和“午餐”也是有相近描述内容的意思。我们能不能换个角度将文本按照词性的相似性将他们压缩到长度只有50~100个维度的数据呢。例如,喜欢的表示为[77..,88,…4],那么喜爱的表示为[77…,89,….4],以代表这两个单词就是相近的,同时也是不一样的。这样的编码不仅指出了单词之间的距离,还指出了单词之间的相似度。
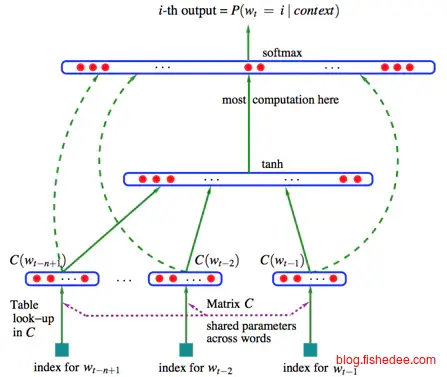
实现时有两个方法,一个方法是离线处理,使用类似word2vec(类似的还有GloVe)的工具,它从现有的巨大语料库中已经分析出文字之间的相似性,你扔给它one-hot编码,它就直接返回给你50~100个维度上短编码。就是做这样的意思,它通过输入字符集,以及大量的数据集,就能将文本从one-hot编码转换为。
另外一个办法是在线处理,加入Word Embedding层作为神经网络的第一层,输入是one-hot编码,输出是多维度数据,让神经网络在训练时自动根据场景也把这一层的映射给训练了。这个方法对于word的种类不多时很有效,而且还能将输入变为最简单的枚举量方法。这个Word Embedding层一般有两个参数,input_dim是单词种类数目,output_dim是映射到低维度的向量维度。
4.2 分类
文本分类、情感分析
4.2.1 CNN
4.2.2 RNN
4.2.3 层叠RNN
4.2.4 双向RNN
4.3 生成
翻译,摘要,问答
4.3.1 多标签
4.3.2 seq2seq
4.3.3 Attention
4.4 结构分析
分词,词性标注,命名实体识别
4.2.1 CNN+CRF
4.2.2 RNN+CRF
5 总结
深度学习可谓是打开了新世界的大门,改变了原来需要人工提取图像,语音,文本特征的方法,实现了定义模型,让机器自动抽取特征匹配识别,十分牛逼。从各种各样的应用场景中,我们不难发现,目前深度学习的主要研究仍然是在CNN与RNN的变种模型上,这不禁让我们感到惊讶,为什么这么古老模型的依然如此有效,而连接这么多层的全连接层反而没什么起色(单纯的全连接层还没有SVM这些传统的分类器更有效)。
我认为,答案就在于,CNN和RNN融合了人们的先验知识到神经网络中,这让神经网络的搜索空间大大减少,从而提高了泛化性能和特征抽取的能力。
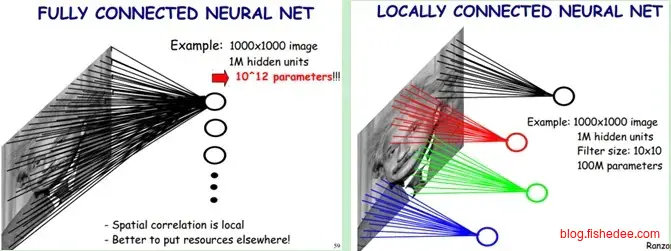
在图像处理中,一个明显的先验知识是,图像处理的局部相关性和平移不变性。
局部相关性,图像中判断一个像素点是不是一个眼睛,它的关键在于这个像素附近四周的像素(15x15的邻域),而与这个像素相遥远的其他像素来说并不重要。也就是这个人的嘴巴是向下弯的,还是向下弯的并不会影响这个位置是不是眼睛的判断。这就是图像的局部相关性,所以,CNN的第一个优化就是使用卷积核单元来提取特征,这个神经元不像原来的神经元一样感受域是整块图像,而只集中在它附近的一个较小的邻域上。
平移不变性,图像中判断一个像素点是不是一个眼睛,只跟它和它周围像素的色彩有关,跟它自身所处的位置无关。也就是说这个图块是在图像的左上角,还是在图像的右下角,它的特征抽取方式是应该是要一样的,这就是图像的平移不变形。所以,CNN的第二个优化就是使用同一个卷积核共享权值和偏置。
所以,正因为语音,文本,图像中处处都可以找到这样的局部相关性和平移不变性的先验特征,我们才能如此有效地套用CNN模型,相比全连接层大大减少了需要训练的神经元权值,提高了泛化性能。
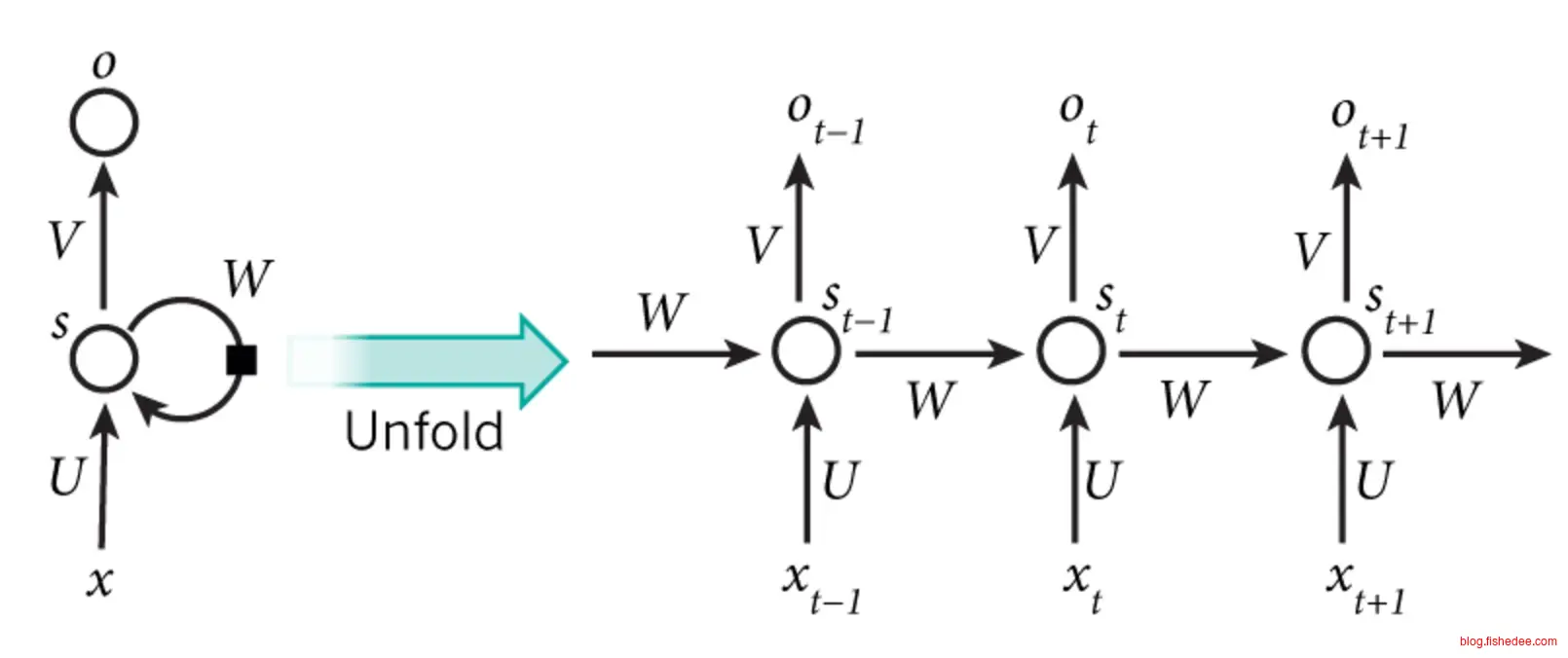
在文本处理中,一个明显的先验知识是,文本信息的平移不变性和关系不变性。
平移不变性,是指每个单词在不同位置的含义都是固定的,例如“大象”是在句子的开头,还是在句子的末尾,我们都认为它是一个名词,跟它在哪里的位置是没有关系的。当然,部分具有二义的词语是跟位置有关的,但准确的来说它是跟前后上下文有关,而不是它是第几个位置有关。所以,平移不变性使得RNN对每个单词的输入都是共享权值的。
关系不变性,是指句子的特征是上下文相关的,而这种上下文相关的关系是关系不变性的。例如,主谓宾,定状补的上下文语法关系在文本中是遵从同一套规则的,不会说这个句子在文本的开头,所以它的语法是主宾谓,在文本末尾时它的语法是主谓宾。所以,关系不变性使得RNN在神经元相互连接时也是共享权值的。
所以,这两个优化使得RNN在分析上下文关系效果效果拔群。同时也比全连接层减少大量的需要训练的权值。
从以上的CNN和RNN的分析中,我们可以将神经网络看成是一种通用的解决方案搜索机,为了减少搜索空间,我们需要根据要解决的问题,找出它们的先验知识来简化神经网络的结构,从而减少搜索空间来更好更快地得出结果。从这个角度看,CNN和RNN就像是概率统计学习中的假设。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!