1 概述
golang的坑,常见问题
2 语法
2.1 闭包的局部变量
package main
import (
"fmt"
"sync"
)
func doing(i int) {
fmt.Println(i)
}
func main() {
waitgroup := sync.WaitGroup{}
for i := 0; i != 5; i++ {
waitgroup.Add(1)
go func() {
defer waitgroup.Done()
doing(i)
}()
}
waitgroup.Wait()
}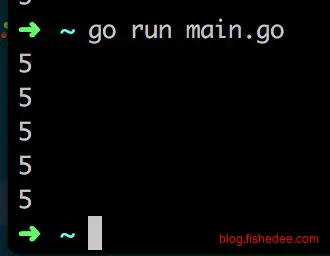
控制台的输出与你想象中的不太一样,闭包捕获变量的方式是通过变量的引用来实现的,所以它输出的是最后i变量的值,而不是建立闭包时的值。
go func(i int) {
defer waitgroup.Done()
doing(i)
}(i)
解决的办法,就是将当时的局部变量i以参数的形式传递到闭包中就可以了。
这个问题跟js常见的闭包变量引用是一样的。
2.2 defer的函数作用域
package main
import (
"fmt"
)
func main() {
for i := 0; i != 10; i++ {
defer fmt.Println(i)
}
fmt.Println("mc")
}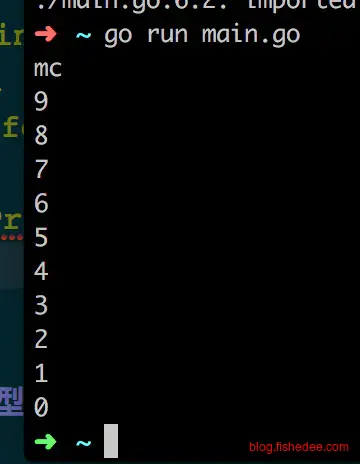
这是以上这段程序的输出,比较神奇的是for里面的defer不会在for的块作用域结束时执行,而是在函数的作用域结束时才执行。所以,mc的输出是最先输出,而不是最后输出的。那是因为defer的执行是以函数作用域为执行块,而不是块作用域。
package main
import (
"fmt"
)
func main() {
for i := 0; i != 10; i++ {
defer func() {
err := recover()
if err != nil {
fmt.Printf("recover %v\n", err)
}
}()
if i%2 == 0 {
panic(i)
}
}
}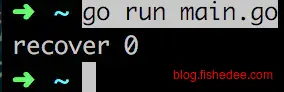
同样的道理,如果我们在for的块作用域中不断defer。我们本意是希望屏蔽掉每次for内部的执行错误,好让每一次的for循环都能全部执行下去。但是,事与愿违,程序其实只会在函数结束时才recover一次,其他for循环的执行都全部忽略掉了。
package main
import (
"fmt"
)
func main() {
for i := 0; i != 10; i++ {
func() {
defer func() {
err := recover()
if err != nil {
fmt.Printf("recover %v\n", err)
}
}()
if i%2 == 0 {
panic(i)
}
}()
}
}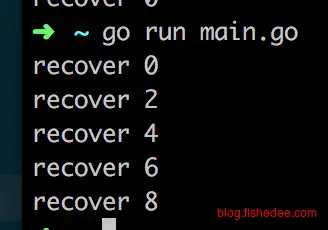
如果要达到我们想要的效果,我们需要为defer建立一个单独的函数作用域。这就是defer的函数作用域带来的recover执行不及时的问题。
package main
import (
"fmt"
"os"
)
func main() {
for i := 0; i != 10; i++ {
f, err := os.Open("/mm")
if err != nil {
fmt.Println(err)
continue
}
defer f.Close()
}
}同理,以上的代码也是我们常见的写法,在for循环里面不断打开文件,然后期望在每次for以后自动关闭文件。但是,defer的函数作用域,导致程序实际上一次打开了很多文件,并只在函数结束时才对所有的文件执行Close操作,这很有可能会导致too many open files的问题。
时刻要注意,defer的作用域与变量是不一样的,它是函数作用域,不是块作用域。
3 内建类型
3.1 slice的append的毁坏数据
package main
import (
"fmt"
)
type Dir struct {
Name []byte
Child []Dir
}
func getName(dir Dir, parent []byte) [][]byte {
result := [][]byte{}
cur := dir.Name
curAbsolute := append(parent, cur...)
result = append(result, curAbsolute)
for _, child := range dir.Child {
result = append(result, getName(child, curAbsolute)...)
}
return result
}
func main() {
var data = Dir{
Name: []byte("ak"),
Child: []Dir{
Dir{
Name: []byte("/bg"),
Child: []Dir{
Dir{[]byte("/cm"), nil},
Dir{[]byte("/dc"), nil},
},
},
Dir{
Name: []byte("/eh"),
Child: []Dir{
Dir{[]byte("/fm"), nil},
Dir{[]byte("/gn"), nil},
},
},
},
}
result := getName(data, nil)
for _, single := range result {
fmt.Println(string(single))
}
}以上代码的作用就是将目录的所有文件以绝对路径的方式全部打印出来
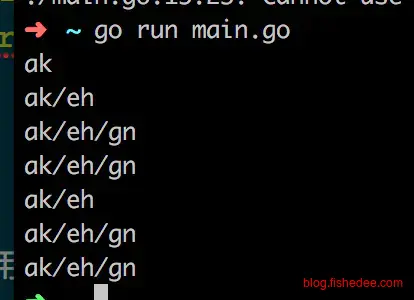
但是结果是错误的,只有第二层级的目录是对的,第一层级的目录像是被覆盖了。
cur := dir.Name
curAbsolute := append(parent, cur...)问题在于curAbsolute的生成方式,它是通过parent与cur拼接起来的。
cur := dir.Name
curAbsolute := []byte{}
curAbsolute = append(curAbsolute, parent...)
curAbsolute = append(curAbsolute, cur...)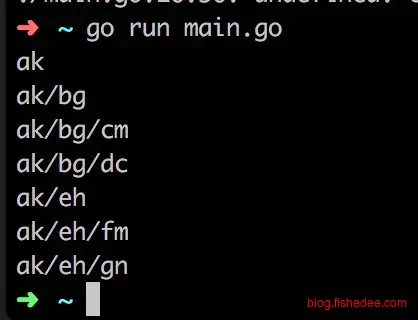
答案是要让curAbsolute从一个空的byte开始生成起来,才没有问题。为什么?
因为slice的拼接操作是引用操作,不是值操作的。第一次的合并是从parent为ak,而cur为/bg合并起来的。合并后,slice会让parent原地扩容到5个字节,并且让parent的数据末三个字节设置为/bg。这个时候的curAbsolute与parent指向的都是同一块地址,它们只是大小不一样而已。而第二层目录合并时(parent为ak,而cur为/eh时),slice发现底层的parent的cap足够5个字节,它就只需要将末三个字节设置为/eh就可以了。这个时候新的curAbsolute和原来的curAbsolute都是指向同一块内存的,所以第一个的curAbsolute的数据被毁坏了。
解决办法很简单,我们让每次的curAbsolute都是指向不一样的地址就可以了,让它每次都是从一个空的slice开始建造起来就可以了。注意,slice的合并操作与string的合并操作是不一样的,一个是引用方式的,另外一个是值方式的。所以,将原来代码的[]byte改成string,是不会有这个问题的。
3.2 channel的len操作
package main
import (
"fmt"
"sync"
)
func run(check chan bool, group *sync.WaitGroup) {
if len(check) == 0 {
fmt.Println("Add Only One")
check <- true
}
group.Done()
}
func main() {
group := &sync.WaitGroup{}
check := make(chan bool, 1)
for i := 0; i != 5; i++ {
group.Add(1)
go run(check, group)
}
group.Wait()
fmt.Println("Done!")
}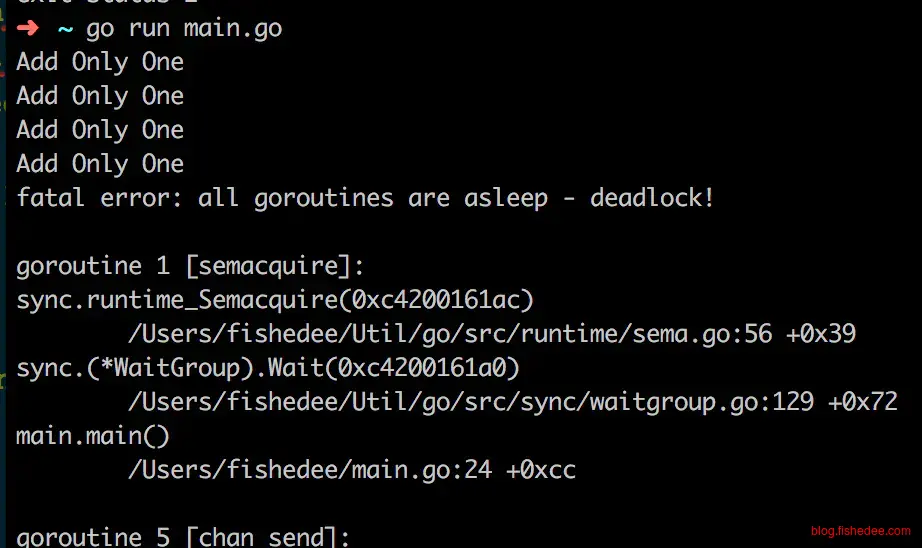
以上的代码会造成死锁。我们的本意是想实现一个非阻塞的写操作,如果缓冲区为空,则写入,缓冲区为满,则不写入。但是,channel的length操作只是一个简单的原子读操作,它并没有与后面的一个写操作组合成一个原子操作。这最终导致在并发的时候,多个线程同时读到一个旧的数据,然后一起并发地写入到已经满的channel中,然后一部分的线程就这么阻塞了。
package main
import (
"fmt"
"sync"
)
var mutex sync.Mutex
func run(check chan bool, group *sync.WaitGroup) {
mutex.Lock()
defer mutex.Unlock()
if len(check) == 0 {
fmt.Println("Add Only One")
check <- true
}
group.Done()
}
func main() {
group := &sync.WaitGroup{}
check := make(chan bool, 1)
for i := 0; i != 5; i++ {
group.Add(1)
go run(check, group)
}
group.Wait()
fmt.Println("Done!")
}解决办法一,使用mutex,将写操作和读操作组合成一个原子操作。
package main
import (
"fmt"
"sync"
)
func run(check chan bool, group *sync.WaitGroup) {
select {
case check <- true:
fmt.Println("Add Only One")
default:
}
group.Done()
}
func main() {
group := &sync.WaitGroup{}
check := make(chan bool, 1)
for i := 0; i != 5; i++ {
group.Add(1)
go run(check, group)
}
group.Wait()
fmt.Println("Done!")
}解决办法二,使用select,default,最为优雅的非阻塞写操作,而且速度最快。
所以,最好不要使用channel的len操作,在并发的环境下,它仅仅只是一个原子读操作,你读到的数据可能是旧数据,不能依据这个数据执行其他操作。
4 http库
4.1 输出丢失
package main
import (
"fmt"
"net/http"
"net/http/httptest"
)
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "html")
w.WriteHeader(500)
var data = []byte("Hello World")
w.Write(data)
w.Header().Set("Content-Length", fmt.Sprintf("%v", len(data)))
}
func main() {
r, _ := http.NewRequest("GET", "/", nil)
w := httptest.NewRecorder()
ServeHTTP(w, r)
fmt.Println(w.Result().Header, w.Result().StatusCode)
}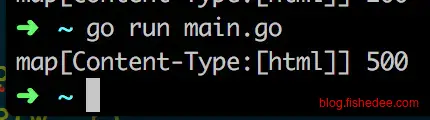
在ServeHTTP中设置了Content-Length,但是输出的结果中却不包含Content-Length的header。
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "html")
var data = []byte("Hello World")
w.Write(data)
w.Header().Set("Content-Length", fmt.Sprintf("%v", len(data)))
w.WriteHeader(500)
}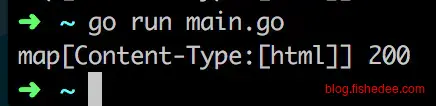
另外,在代码中输出WriteHeader为500,会发现最终输出的结果竟然是200。
这是因为,golang中的ResponseWriter中有这样的规定:
- header输出只有在WriteHeader和Write之前才是有效的,在WriteHeader和Write之后设置都是无效的。
- statusCode输出只有在Write之前才是有效的,在Write之后设置都是无效的。
为什么要这样设计?因为http的回复报文中,header在前,body在后。如果write body以后还能设置header的信息,这代表http需要将body信息缓存在内存中,不能直接写到socket上。对于大body的数据,缓存在内存中会导致很大的性能问题(占用内存太大)。
4.2 优雅关闭不及时
package main
import (
"context"
"fmt"
"net/http"
"os"
"os/signal"
)
type test struct {
}
func (this *test) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(500)
w.Write([]byte("Hello World"))
}
func main() {
server := &http.Server{
Addr: ":8585",
Handler: &test{},
}
go server.ListenAndServe()
fmt.Println("running...")
ch := make(chan os.Signal, 100)
signal.Notify(ch, os.Kill, os.Interrupt)
<-ch
fmt.Println("closing...")
server.Shutdown(context.TODO())
fmt.Println("exit!")
}自从golang 1.8以后,http就原生提供了优雅关闭的函数Shutdown。但是,在上面的测试程序中,如果:
- 打开程序
- 打开Chrome(非隐身模式),连续不断刷新localhost:8585地址十次左右
- 然后ctrl+c关闭程序
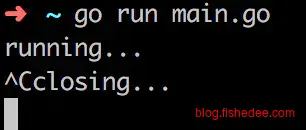
你就会发现程序卡在closing的位置,也就是Shutdown无法及时优雅关闭。按道理说,这个时候已经没有任何一个连接在server上运行,优雅关闭的速度应该是要很快才对的。
这个问题我调试了很久,最终发现问题在:
- net/http中的连接只有五种状态,new,active,closed,idle和Hijacked,具体解释看这里
- 当Shutdown被调用时,Hijacked连接会被忽略(常用来做websocket和long-poll连接),closed连接已经关闭了,idle连接会被直接关闭(持久连接),active连接就是ServeHTTP正在处理的连接,Shutdown会等待它完成后才返回。而new连接则会等待它读取http的header信息,然后转换为active连接,最后等待它处理完成后才返回。也就是说,Shutdown会耐心地等待new和active状态的连接才会返回,其他状态的连接则直接忽略。
- Chrome浏览器比较特别,在连续不断刷新时,它会预先与后端建立一个持久连接,这个持久连接仅仅用来作为方便下次请求使用,所以这个连接一个header都没有发送出去。也就是,这个连接会被golang server设置为new状态。
- 当Shutdown被触发时,即使目前server一个请求都没有需要处理,但由于存在了一个new状态的连接,Shutdown就需要等到它完成为止,而Chrome却在等待下一个用户触发的请求到来,所以Shutdown就卡在那里了!
解决方法有两个:
- 设置server的ReadHeadTimeout为2秒,代表new状态的连接,如果在2s内还没发送完所有的header请求就强制关闭对方。所以Shutdown就无需要等待Chrome浏览器了,当Shutdown触发时,最长2秒就能马上返回了。
- 设置server的SetKeepAlivesEnabled为false,禁止持久连接。这样每个请求完毕后,Chrome都必须要主动关闭连接,无法提前预先建立持久连接。当Shutdown触发时,马上就能返回了。
这是问题真是挺蛋疼的,但是,这提醒了我们在建立server时最好都设置好每个timeout是多少,不然可能会被设计不良的客户端占用连接资源。值得一说的是,这个问题在safari是不存在的,它没有像Chrome一样通过提前建立持久连接来加速网络请求。
4.3 TIME_WAIT和CLOSE_WAIT过多
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'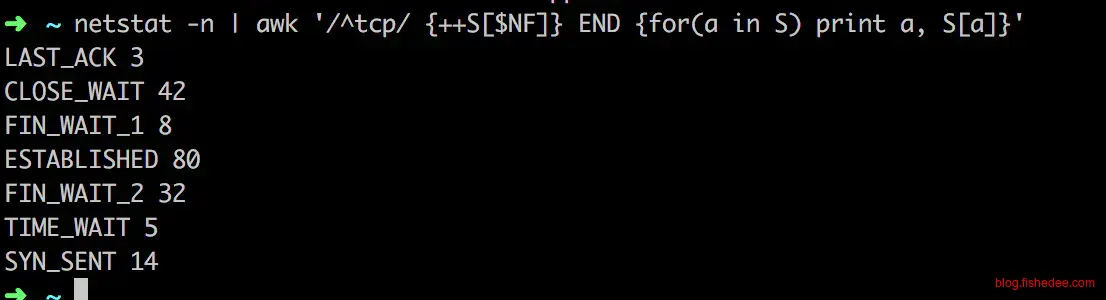
我们用netstat可以查看到目前的tcp连接中,各个状态的数量,最常见的问题是,TIME_WAIT和CLOSE_WAIT状态的数量过多了,严重占用端口资源。
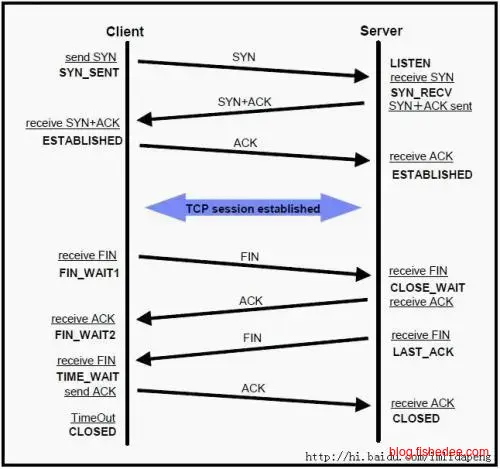
众所周知,TCP连接是三次握手,四次挥手的状态。当客户端或服务器其中一方想主动关闭连接时,主动关闭方就会进入FIN_WAIT1状态,对方收到FIN包后进入CLOSE_WAIT状态,返回返回ACK包。被动关闭方,需要调用系统的close方法回收socket资源,这个时候系统发送FIN包给主动关闭方,并且被动关闭方进入到LAST_ACK状态。主动关闭方收到FIN包后进入到TIME_WAIT状态,并回复ACK包,然后超时2MSL个时间(大概为2分钟)后,主动关闭方进入到CLOSED状态,彻底回收socket资源。被动关闭方收到ACK包后,从LAST_ACK状态进入到最终的CLOSED状态。
经过上面冗长的分析,我们得到两个要点:
- TIME_WAIT状态只在主动关闭方出现,这个主动关闭方可能是客户端,也有可能是服务器。TIME_WAIT状态的消失只能通过2MSL时间转换为CLOSED状态后消失。无法人工删除,因为这是一个非常谨慎的TCP设计方案,最好不要通过修改系统参数来避免这个2MSL的等待时间。
- CLOSE_WAIT状态就简单得多,就是被动关闭方收到主动关闭方的FIN包时就会进入,只要被动关闭方调用close关闭socket就能马上进入LAST_ACK状态。
好了,经过以上的分析,我们知道,TIME_WAIT会过多的原因只有一个,就是本地主动关闭的连接太多了,常见的具体原因是:
- http.Client中没有设置MaxIdleConnsPerHost,如果你的httpclient后端只有有限的几个host的服务器,由于默认的MaxIdleConnsPerHost只设置为2,这代表,大部分的持久连接都会在完成请求后,会被http.Client主动关闭,导致大量的TIME_WAIT事件发生。如果MaxIdleConnsPerHost设置得比较大,这些连接请求完成后则会被http.Client放进连接池中留作下次使用,不会去主动关闭,大大减少短连接的使用,避免了TIME_WAIT事件的发生。
- http.Server中直接连前端的浏览器,没有经过中转网关。这样会导致大量设计不良的爬虫直接使用短连接连接server。由于这些请求都是带上Connection: close参数,导致http.Server主动关闭这些短连接,使得服务器大量留下了TIME_WAIT状态。解决方法很简单,让http.Server前面建立一个nginx网关,将短连接转换为长连接来连接后端的golang服务,这样这些TIME_WAIT状态会耗费在网关层,而不是在服务层。
- http.Server中连接第三方服务时没有使用连接池,第三方服务例如redis,mysql,rabbitmq这种,然后每个操作都是使用短连接来操作,用完就主动关闭,这样会大大增加server端的TIME_WAIT状态,耗费了大量的端口资源。解决办法,就是用连接池了,没什么好说的。
最后一个,CLOSE_WAIT状态过多,这个最容易解决了,就是服务器或客户端接收到对方主动关闭的消息后,马上调用close释放socket资源就可以了。CLOSE_WAIT状态过多都是由于,程序考虑不够充分,没有调用close释放socket资源导致的。常见的情况是,服务器使用websocket或者long-poll做推送服务,当前端主动关闭浏览器后,服务器忘了立即close对应的socket资源,导致CLOSE_WAIT太多了。
5 io库
5.1 半读取返回
package main
import (
"fmt"
"io"
"time"
)
func writer(w io.Writer) {
mm := "Hello World"
for i := 0; i != len(mm); i++ {
temp := []byte{mm[i]}
w.Write(temp)
time.Sleep(time.Millisecond * 100)
}
}
func main() {
r, w := io.Pipe()
go writer(w)
buffer := make([]byte, 5, 5)
n, err := r.Read(buffer)
if err != nil {
panic(err)
}
fmt.Println(string(buffer[0:n]))
}
注意,上面的例子,即使输入的是长度为5的buffer,输出也只是单个字符H。这是因为io.Reader的Read的语义是,在指定的buffer以内读取对应的数据,返回的数据大小可能少于或等于buffer的长度。所以,就会出现这样的问题。
n, err := io.ReadFull(r, buffer)
解决办法很简单,将read改为io.ReadFull,那么io就会读取和buffer刚好大小的数据。如果遇到了EOF,或者中途的任何错误,返回的err都会是非nil。
6 总结
说是golang的坑,还不如说是自己考虑得还不够仔细。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!