1 概述
golang性能测试与调优,最近突发奇想,试图写一个超越gin速度的httprouter。中途遇到了很多问题,甚是有趣。
2 测试
2.1 正确的性能测试程序
性能测试的第一步就是写测试程序,可是怎么写正确本身就是个问题。
2.1.1 普通姿势
package main
import (
"testing"
)
func doSomething() {
}
func BenchmarkDemo(b *testing.B) {
for i := 0; i != b.N; i++ {
doSomething()
}
}普通的性能测试就是利用传入的b.N作为循环体变量,doSomething就是要测试对象程序,golang会对doSomething重复调用来确定性能测试的结果。
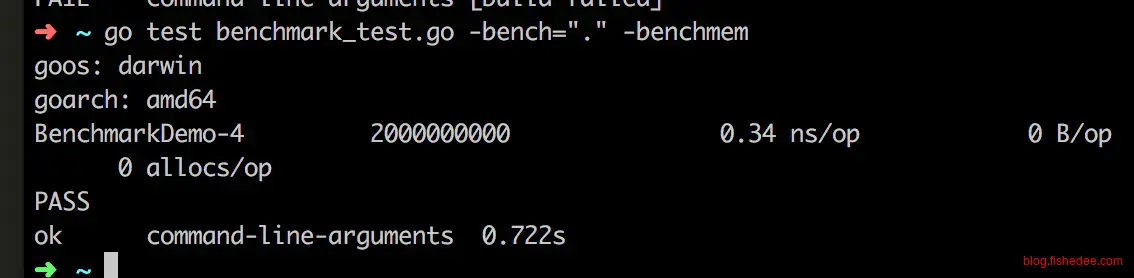
然后执行以上命令就能进行性能测试了
2.1.2 分离测试数据与测试步骤
func doSomething() {
}
func doSomethingPrepare(n int) {
for i := 0; i != n; i++ {
_ = time.Now()
}
}
func BenchmarkDemo(b *testing.B) {
doSomethingPrepare(b.N)
b.ResetTimer()
for i := 0; i != b.N; i++ {
doSomething()
}
}有些时候在benchmark之前需要做一些准备工作,并且,我们不希望这些准备工作纳入到计时里面,我们可以使用 b.ResetTimer(),代表重置计时为0,以调用时的时刻作为重新计时的开始。
2.1.3 避免频繁调用timer
func doSomething() {
}
func doSomethingPrepare() {
for i := 0; i != 1000; i++ {
_ = i
}
}
func BenchmarkDemo(b *testing.B) {
b.ResetTimer()
for i := 0; i != b.N; i++ {
b.StopTimer()
doSomethingPrepare()
b.StartTimer()
doSomething()
}
}对于之前的例子,我们可能会选择在性能测试的循环体中,每次循环准备一次,然后在循环体内部用stopTimer与startTimer。注意!这样是错误的,千万不能这样做!
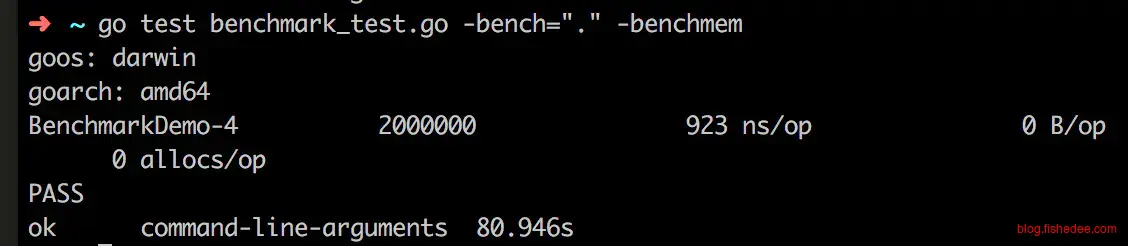
如果按着这样做的话,就会使得计算出来的时间过于偏大。实际的doSomething是个空函数,不可能需要每个操作需要923ns这么多的。
func startTimer(){
begin := time.Now()
}
func stopTimer(){
end := time.Now()
}
duration += end - begin这里的问题在于startTimer与stopTimer不是没有成本的,查看源代码可以知道,每次startTimer与stopTimer的调用都需要调用一次time.Now(),而每次的time.Now()调用一次的耗时就大概需要900ns。所以这样的耗时就会累积到每次循环体中,最终导致测试的时间过于偏大。因此,最好不要将startTimer,stopTimer,resetTimer放在循环体内,而要放在循环体外,这样900ns的代价只会累加一次,而不是b.N次!
func BenchmarkDemo(b *testing.B) {
b.ResetTimer()
for i := 0; i != b.N; i++ {
b.StartTimer()
b.StopTimer()
}
}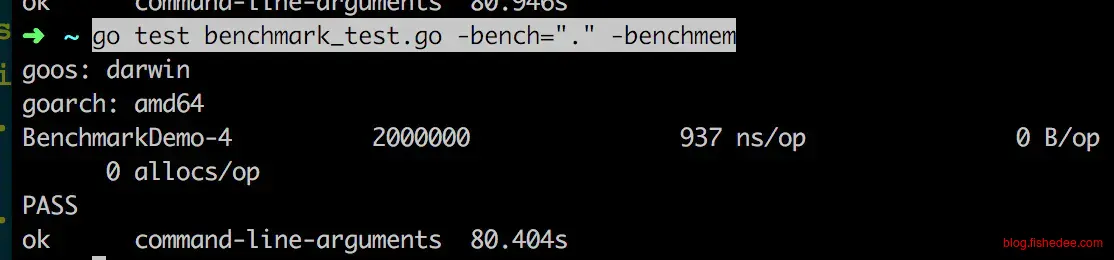
再进一步地,即使循环体为空,什么都不做,仅仅只是调用startTimer与stopTimer,依然需要巨量的耗费时间。
2.1.4 避免测试数据过大
func doSomethingPrepare(size int) []string {
data := []string{}
temp := 10000000
for i := 0; i != size; i++ {
temp++
data = append(data, strconv.Itoa(temp))
}
return data
}
func BenchmarkDemo(b *testing.B) {
data := doSomethingPrepare(b.N)
b.ResetTimer()
for i := 0; i != b.N; i++ {
_ = strings.Count(data[i], "0")
}
}以上代码测试的是,长度为8的字符串,Count函数的执行时间。其中doSomethingPrepare是数据准备代码。
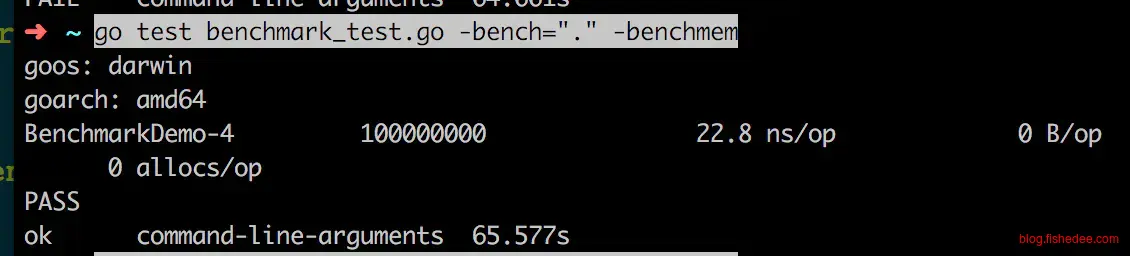
测试的代码比实际的要偏大一点,为什么?

可以看到,测试的时候由于b.N很大,导致生成的测试数据过大,远远超过实际内存的大小。那么,在跑测试代码时,不仅受到代码本身质量影响,还收到内存不足导致的不断换页的影响,大大偏大了实际时间
func doSomethingPrepare(size int) []string {
data := []string{}
temp := 10000000
for i := 0; i != size; i++ {
temp++
data = append(data, strconv.Itoa(temp))
}
return data
}
func BenchmarkDemo(b *testing.B) {
data := doSomethingPrepare(1024)
b.ResetTimer()
for i := 0; i != b.N; i++ {
_ = strings.Count(data[i%1024], "0")
}
}正确的方法是使用固定的数据集,将数据内存限制在一个较小的领域,避免换页影响代码的真实性能。
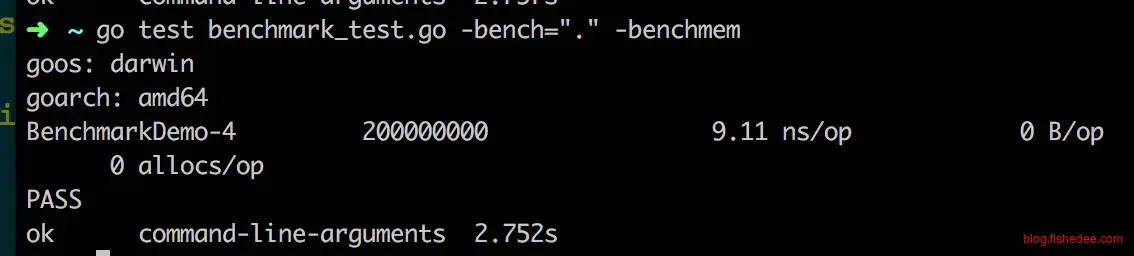
可以看出,一样的长度为8的字符串,在没有了换页的问题后,真实性能是9.11ns,而不是22.8ns。换页的时间甚至大大超过了Count函数本身的时间。
2.2 指定任务的cpu profile
func runProfile(handler func()) {
f, err := os.Create("cpu.prof")
if err != nil {
log.Fatal(err)
}
defer f.Close()
fmt.Println("start cpu prof")
// 开始 CPU profile
if err := pprof.StartCPUProfile(f); err != nil {
log.Fatal(err)
}
defer pprof.StopCPUProfile()
// 要剖析的任务
handler()
}对指定的程序,进行cpu profile,需要注入代码
go tool pprof -http=:8080 cpu.prof生成了cpu.prof以后,使用go tool来查看火焰图
2.3 单元测试的cpu profile
go test benchmark_test.go -cpuprofile=cpu.profile -bench="." -benchmem在完成了性能测试后,我们需要找出程序的瓶颈地方,就需要在go test时加入-cpuprofile=cpu.profile参数就可以了。
go tool pprof -web main.test cpu.profile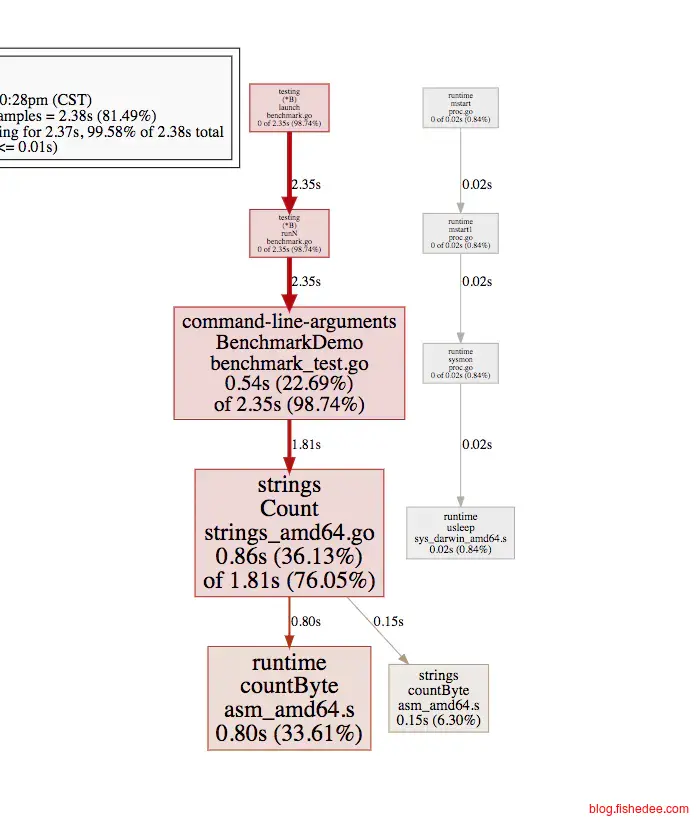
然后执行go tool pprof就能看成总体性能的瓶颈在哪里了,相当的直观和简单。
3 调优
指出常见的调优方法,哪些是靠谱的,哪些是不靠谱的。
3.1 运算符
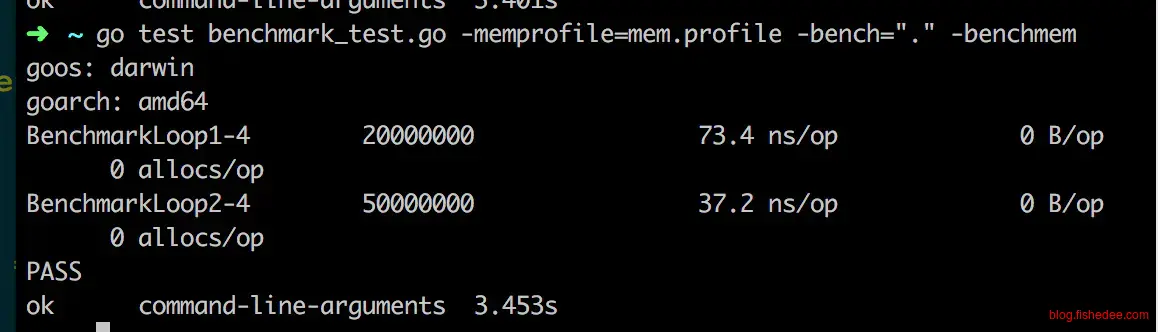
3.1.1 循环体
func BenchmarkLoop1(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := 0; j != 1000; j++ {
_ = j
}
}
}
func BenchmarkLoop2(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := range make([]struct{}, 1000) {
_ = j
}
}
}常见的[0,j]的遍历,有一种是for遍历,还有一种是for range遍历。
实践表明,这两种方法相差不多,没有必要改为for range遍历。
3.1.2 除法
func prepare(n int) (int, int, []int) {
return 9, 511, make([]int, 1024)
}
func BenchmarkLoop1(b *testing.B) {
length, _, data := prepare(b.N)
for i := 0; i != b.N; i++ {
for j := 0; j != 100; j++ {
_ = data[j%length]
}
}
}
func BenchmarkLoop2(b *testing.B) {
_, mask, data := prepare(b.N)
for i := 0; i != b.N; i++ {
for j := 0; j != 100; j++ {
_ = data[j&mask]
}
}
}循环使用下标的算法中,一种是取模,另外一种是取mask。
实践表明,取mask的方法要快速得多,几乎是取模的三倍。
3.1.3 switch
var (
data = map[string]int{
"GET": 1,
"GET2": 2,
"GET3": 3,
"GET4": 4,
"GET5": 5,
}
list = [5]string{"GET", "GET2", "GET3", "GET4", "GET5"}
)
func BenchmarkLoop1(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := len(list) - 1; j >= 0; j-- {
_ = data[list[j]]
}
}
}
func BenchmarkLoop2(b *testing.B) {
for i := 0; i != b.N; i++ {
var method int
for j := len(list) - 1; j >= 0; j-- {
switch list[j] {
case "GET":
method = 1
break
case "GET2":
method = 2
break
case "GET3":
method = 3
break
case "GET4":
method = 4
break
case "GET5":
method = 5
break
default:
method = 0
break
}
_ = method
}
}
}对于常量字符串的映射算法,一种是map,另外一种是switch。
实践表明,switch几乎是map的两倍。
3.2 字符串与切片
3.2.1 尽量使用库
var data string
var data2 string
func init() {
data = "/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd1"
data2 = "/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd2"
}
func BenchmarkCmp1(b *testing.B) {
for i := 0; i != b.N; i++ {
_ = data == data2
}
}
func BenchmarkCmp2(b *testing.B) {
for i := 0; i != b.N; i++ {
isOk := true
for j := 0; j != len(data); j++ {
if data[j] != data2[j] {
isOk = false
break
}
}
_ = isOk
}
}简单的比较两个字符串,一个是使用自带的等号操作符,另外一个使用的是直接遍历。
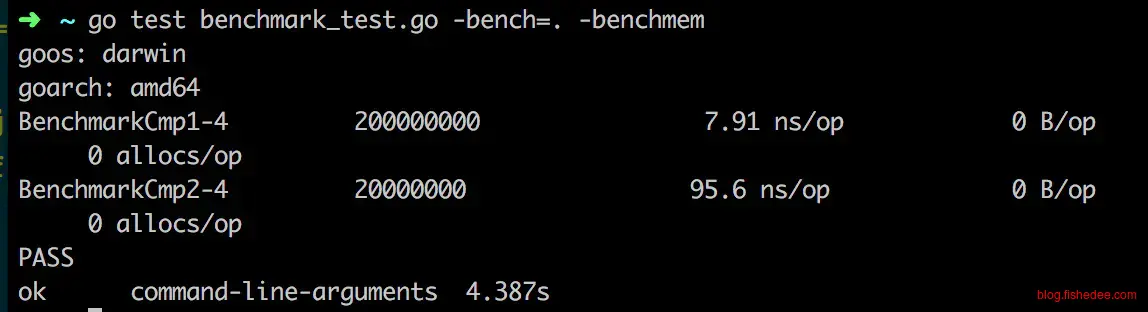
时间相差超过10倍,自带的等号操作符快得震惊。为什么,因为运行在golang的代码,每一个字符的对比除了比较字符本身以外,还需要检查下标是否越界,c和c++这类没有检查下标越界的语言就没有那么大的区别)。而golang自身的操作符是嵌入到语言里面的,所以它可以越过检查下标越界的这一步,只需要比较字符就好了。另外,很多标准库里面的代码也是这样,他们用了内嵌汇编和unsafe转换等的黑魔法实现了快得多的速度。所以,一般情况下,同样的操作,我们尽可能使用标准库的实现。
func BenchmarkCount1(b *testing.B) {
b.ResetTimer()
for i := 0; i != b.N; i++ {
count := 0
for j := 0; j != len(data); j++ {
if data[j] == '/' {
count++
}
}
_ = count
}
}
func BenchmarkCount2(b *testing.B) {
b.ResetTimer()
for i := 0; i != b.N; i++ {
count := strings.Count(data, "/")
_ = count
}
}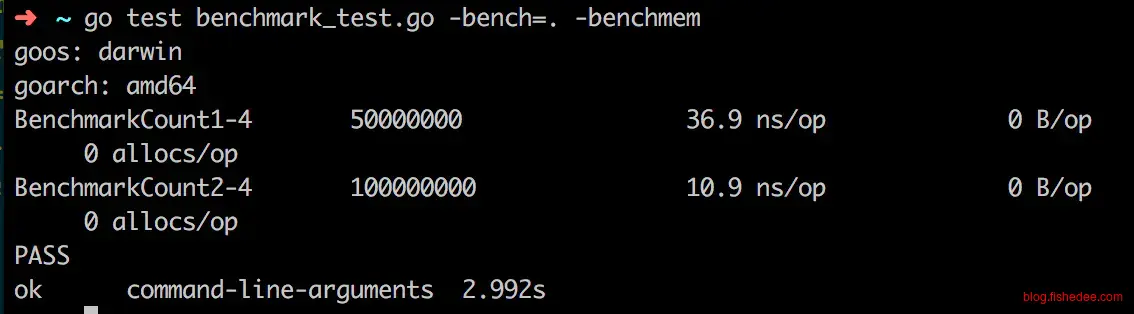
同样地,对字符串的特定字符计数操作,标准库与直接实现相比相差3倍
3.2.2 尽量使用切分
func BenchmarkCmp1(b *testing.B) {
for i := 0; i != b.N; i++ {
isOk := true
for j := 0; j != 20; j++ {
if data[j] != data2[j] {
isOk = false
break
}
}
_ = isOk
}
}
func BenchmarkCmp2(b *testing.B) {
for i := 0; i != b.N; i++ {
_ = (data[:20] == data2[:20])
}
}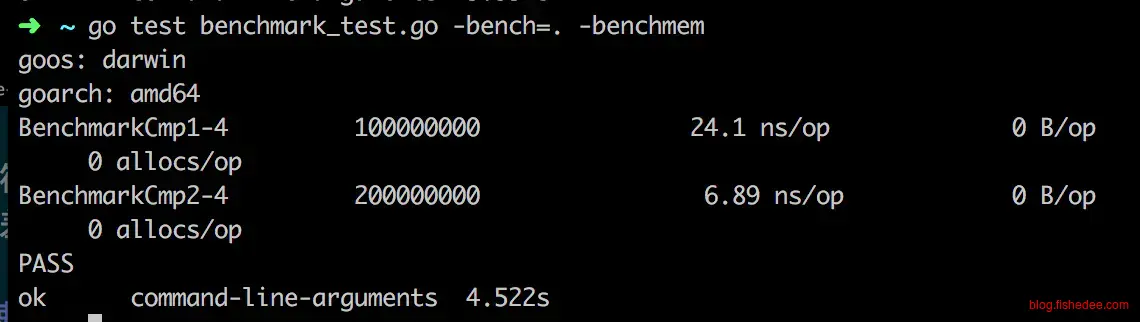
注意要巧妙地使用字符串和切片中切分操作,切分操作能在O(1)的时间内实现,它仅仅是修改了指向数据的指针而已,并没有重新复制数据。有了切分操作后,我们就能对子字符串和子切分执行标准库的操作,能大大地提高效率。
3.2.3 预分配内存
func BenchmarkAdd1(b *testing.B) {
for i := 0; i != b.N; i++ {
temp := ""
for j := 0; j != 10; j++ {
temp += data
}
_ = temp
}
}
func BenchmarkAdd2(b *testing.B) {
temp := make([]byte, len(data)*10)
for i := 0; i != b.N; i++ {
temp2 := temp
for j := 0; j != 10; j++ {
index := copy(temp2, data)
temp2 = temp2[index:]
}
_ = string(temp)
}
}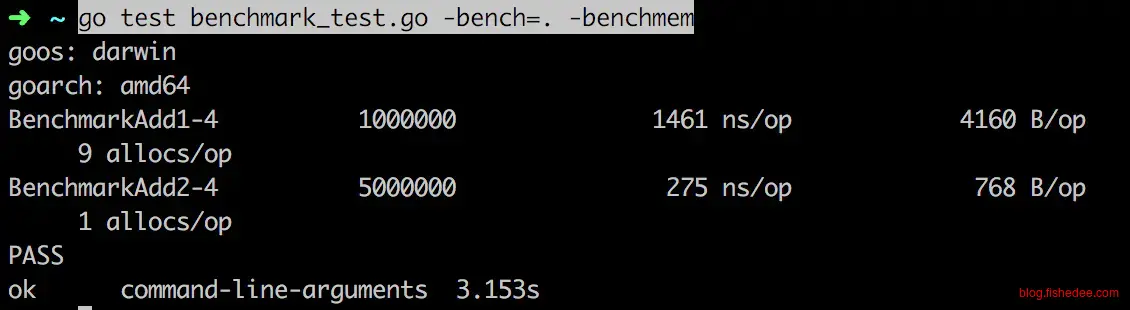
对于字符串的拼接操作,如果我们在拼接前就预先分配好内存,那么拼接时的速度就会飞快地执行,否则每一次的拼接都需要重新分配一次内存,golang 1.10的StringBuilder就是类似的原理。
func BenchmarkAppend1(b *testing.B) {
for i := 0; i != b.N; i++ {
temp := []int{}
for j := 0; j != 100; j++ {
temp = append(temp, j)
}
_ = temp
}
}
func BenchmarkAppend2(b *testing.B) {
for i := 0; i != b.N; i++ {
temp := make([]int, 0, 100)
for j := 0; j != 100; j++ {
temp = append(temp, j)
}
_ = temp
}
}
func BenchmarkAppend3(b *testing.B) {
for i := 0; i != b.N; i++ {
temp := make([]int, 100, 100)
for j := 0; j != 100; j++ {
temp[j] = j
}
_ = temp
}
}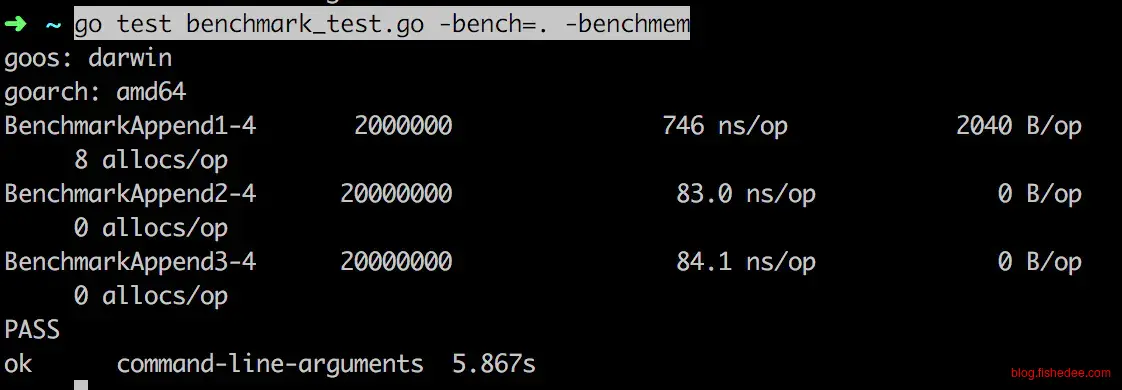
切片的append操作也是如此,如果在append前能大概确定数组的数量,那么可以在append前预先设置好切片的cap,那么append的速度就会飞一样的快。注意,append2与append3相差不大,这说明了slice的size有没有预先设置没有关系,关键是cap。
3.2.4 字符串遍历
func BenchmarkIt1(b *testing.B) {
for i := 0; i != b.N; i++ {
for _, char := range data {
_ = char
}
}
}
func BenchmarkIt2(b *testing.B) {
for i := 0; i != b.N; i++ {
for _, char := range []byte(data) {
_ = char
}
}
}
func BenchmarkIt3(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := 0; j != len(data); j++ {
_ = data[j]
}
}
}
func BenchmarkIt4(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := len(data) - 1; j >= 0; j-- {
_ = data[j]
}
}
}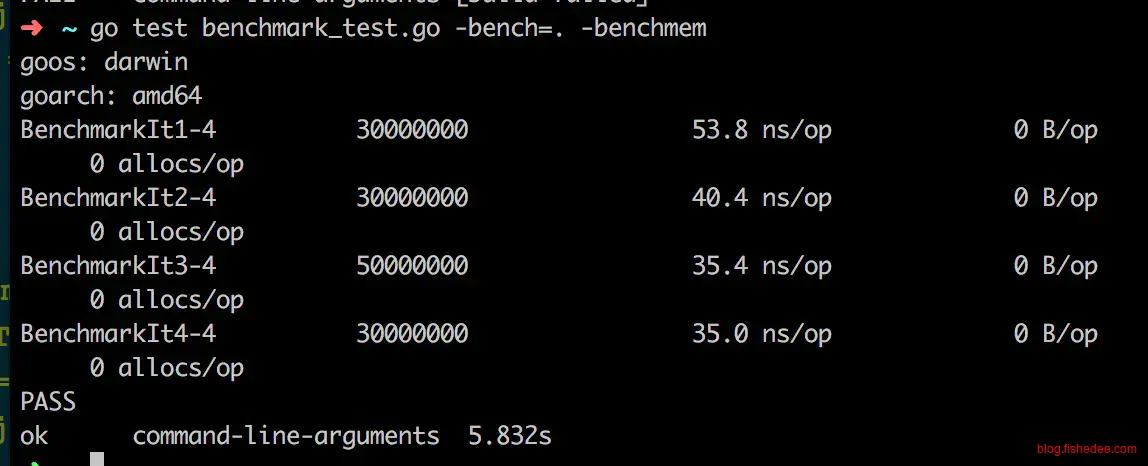
四种方式的遍历字符串,最快的是直接的下标遍历,为什么?因为字符串直接for range时,它返回的不是byte,而是rune,字符串在遍历时是需要内部转换的,因为字符串的底层数据储存是[]byte,不是[]rune,所以直接for range是最慢的。而for range []byte与下标遍历相差不大了,都可以用。
3.2.5 切片遍历
var data []int
func init() {
for j := 0; j != 1000; j++ {
data = append(data, j)
}
}
func BenchmarkIt1(b *testing.B) {
for i := 0; i != b.N; i++ {
for _, char := range data {
_ = char
}
}
}
func BenchmarkIt2(b *testing.B) {
for i := 0; i != b.N; i++ {
for j := 0; j != len(data); j++ {
_ = data[j]
}
}
}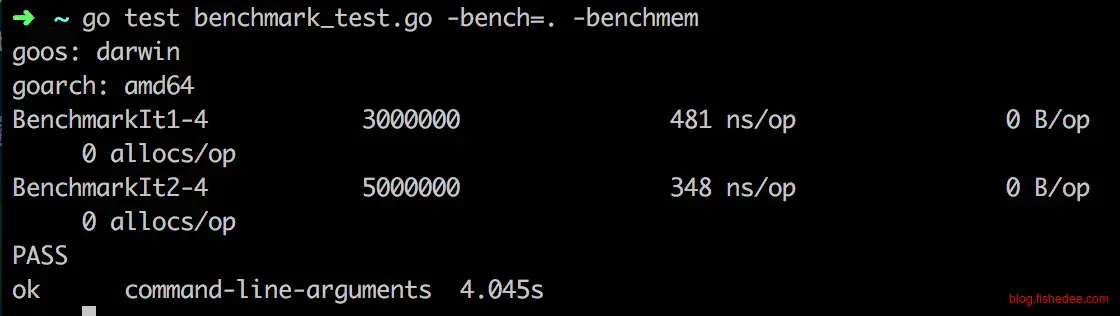
slice切片的遍历类似string,最快的依然是下标操作,for range略慢,但没有string的直接for range慢得多。
3.3 动态特性
3.3.1 反射
我们尽可能不要使用反射特性,因为他的性能很差。在一个反转数组的例子中,反射的性能大概是手写代码的75倍的慢。当然,在一些非关键业务,或者调用次数有限的动态场景,我们可以使用发射来提高接口的灵活性倒是挺好的。
3.3.2 通用interface
在不使用反射特性时,我们通常会想到用interface{}来做通用类型,能保存任意的类型,同时取出来时golang会做类型校验。要注意这样做对于大部分业务来说,性能依然是很高的。但是,与原生操作相比,除了指针类型放入interface{}不会造成内存分配以外,其他类型(包括int,slice和map)放入interface{}里面都会触发一次内存分配,对于性能要求非常敏感的地方,要慎用interface{}。
3.3.3 函数指针
type MM struct{
Name string
Age int
}
type MMSort struct{
data []MM
}
func (this *MMSort) Less(i int,j int)bool{
return data.Age[i] < data.Age[j]
}
func (this *MMSort) Swap(i int,j int){
temp := data[i]
data[i] = data[j]
data[j] = temp
}
a := []MM{}
sort.Sort(&MMSort{data:a})在标准库中,sort可以对一个任意的数组进行排序操作,但是它却没有使用反射特性,为什么?因为他将类型相关的操作以接口方式抽象出来了,由用户传入接口来实现对任意数组的排序。这样做既实现了一定的灵活性,而且保证了性能没有损失。但是,这样做会污染接口,使用方不方便,每个类型排序时都需要先建立一个新结构体。
3.3.4 模板
很可惜,这个问题用模板是解决不了的。模板充其量只是类型的字符串替换工具而已,它不能对类型进行自省的能力。例如,模板不能读取出结构体有多少个字段,每个字段的名字和类型是什么。所以,在一些需要特别动态的特性,例如是对任意对象进行序列化或反序列化的操作时,即使golang2中的模板出现了,这个问题依然是解决不了。
3.3.5 代码生成
代码生成是一个屌炸天的工具,使用黑魔法的一种,这种黑魔法在C,C++和rust称为宏。它的想法是在编译前通过对源代码进行语法和语义分析,得出需要执行动态操作的地方,然后为这个地方使用宏来生成代码。
type MM struct{
Age int
}
func (this *MM) MarshalJson()([]byte){
age := strconv.Iota(this.Age)
return []byte(`{"age":"`+age+`"}`)
}例如当我们引用easyjson工具时,它就会在编译时为每个结构体生成以上的这一段代码。当调用json.Marshal函数时,json.Marshal函数会首先检查是否有已经有该类型的特定生成代码,有的话直接调用,没有的话就才利用反射工具进行生成。
type MM struct{
Age int
}
a := []MM{}
QuerySort(a,"Age asc").([]MM)同理,我们也可以在编译时提取所有QuerySort的调用地方,分析出所有可能输入的类型是什么,然后自动生成对应的代码。当运行时执行QuerySort函数时就直接根据不同类型跳转到不同的已经生成好的代码上就可以了。
这样做,既保证了需要动态特性的接口依然是简单灵活的,并且性能就像手写的一样快。所以,务必学习好go/parser,go/types下的工具,都是神器。
3.4 黑魔法
3.4.1 pool避免创建内存
package main
import (
"sync"
"testing"
)
var data string
var pool sync.Pool
var pool2 sync.Pool
type testStruct struct {
buffer []byte
}
func init() {
data = "/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd1"
pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
pool2 = sync.Pool{
New: func() interface{} {
return &testStruct{
buffer: make([]byte, 1024, 1024),
}
},
}
}
func doSomething(a []byte) {
}
func handler1(url string) {
temp := ""
for j := 0; j != 10; j++ {
temp += url
}
doSomething([]byte(temp))
}
func BenchmarkAdd1(b *testing.B) {
for i := 0; i != b.N; i++ {
handler1(data)
}
}
func handler2(url string) {
result := make([]byte, len(url)*10, len(url)*10)
temp := result
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
}
doSomething(result)
}
func BenchmarkAdd2(b *testing.B) {
for i := 0; i != b.N; i++ {
handler2(data)
}
}
func handler3(url string) {
buffer := pool.Get().([]byte)
temp := buffer
size := 0
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
size += count
}
doSomething(buffer[0:size])
pool.Put(buffer)
}
func BenchmarkAdd3(b *testing.B) {
for i := 0; i != b.N; i++ {
handler3(data)
}
}
func handler4(url string) {
testStruct := pool2.Get().(*testStruct)
buffer := testStruct.buffer
temp := buffer
size := 0
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
size += count
}
doSomething(buffer[0:size])
pool2.Put(testStruct)
}
func BenchmarkAdd4(b *testing.B) {
for i := 0; i != b.N; i++ {
handler4(data)
}
}我们假设一个场景,每个http请求过来时,将当前url自身复制10次,然后传入doSomething中执行业务。由于http请求可能是并发进来的,我们不能像原来一样,只建立一个byte的slice作为缓冲区处理。因为这样做会导致多个请求竞争同一个byte的slice来处理,会出现竞争冲突的问题。
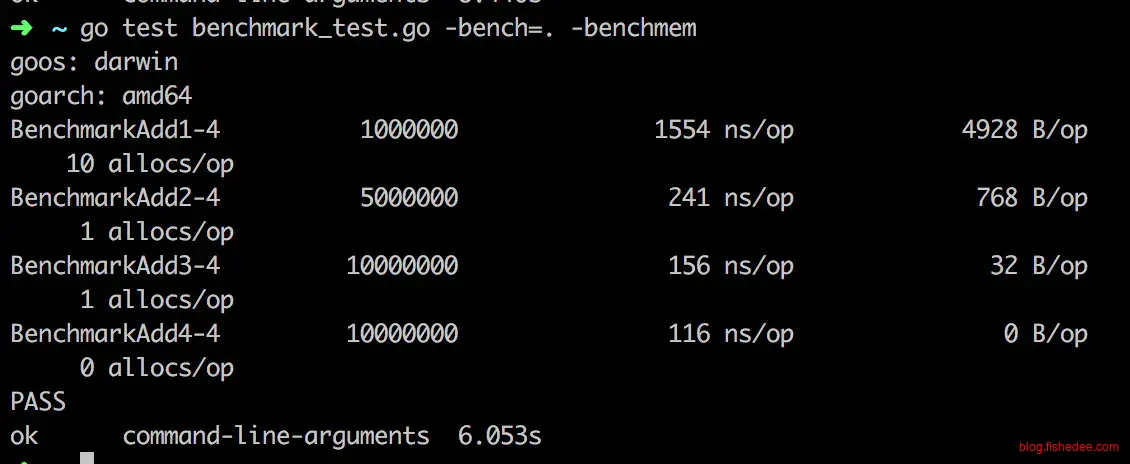
我们解决方法有四个:
- 直接复制,由于没有预先分配内存,所以这种方法特别慢。
- 为每个请求预先分配一次内存,这样就不会出现多个请求竞争同一块缓冲区的问题,而且只分配一次内存,大大提高了性能。
- 使用sync.Pool建立内存池,让所有请求共享同一个内存池,里面有多个缓冲区,直接就能不断复用之前分配过的内存,实现多个请求共用一个缓冲区,而且没有竞争。这个方法可谓是黑魔法,效果很好。但是,每个请求依然有32B的内存分配操作。
- 将sync.Pool返回结构体指针,而不是直接返回slice,这样就能避免32B的内存分配,性能达到最高。
3.4.2 unsafe避免创建内存
package main
import (
"sync"
"testing"
"unsafe"
)
var data string
var pool sync.Pool
var pool2 sync.Pool
type testStruct struct {
buffer []byte
}
func init() {
data = "/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd/asdfasd1"
pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
pool2 = sync.Pool{
New: func() interface{} {
return &testStruct{
buffer: make([]byte, 1024, 1024),
}
},
}
}
func doSomething(a string) {
}
func handler1(url string) {
temp := ""
for j := 0; j != 10; j++ {
temp += url
}
doSomething(temp)
}
func BenchmarkAdd1(b *testing.B) {
for i := 0; i != b.N; i++ {
handler1(data)
}
}
func handler2(url string) {
result := make([]byte, len(url)*10, len(url)*10)
temp := result
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
}
doSomething(string(result))
}
func BenchmarkAdd2(b *testing.B) {
for i := 0; i != b.N; i++ {
handler2(data)
}
}
func handler3(url string) {
buffer := pool.Get().([]byte)
temp := buffer
size := 0
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
size += count
}
doSomething(string(buffer[0:size]))
pool.Put(buffer)
}
func BenchmarkAdd3(b *testing.B) {
for i := 0; i != b.N; i++ {
handler3(data)
}
}
func handler4(url string) {
testStruct := pool2.Get().(*testStruct)
buffer := testStruct.buffer
temp := buffer
size := 0
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
size += count
}
doSomething(string(buffer[0:size]))
pool2.Put(testStruct)
}
func BenchmarkAdd4(b *testing.B) {
for i := 0; i != b.N; i++ {
handler4(data)
}
}
func handler5(url string) {
testStruct := pool2.Get().(*testStruct)
buffer := testStruct.buffer
temp := buffer
size := 0
for j := 0; j != 10; j++ {
count := copy(temp, data)
temp = temp[count:]
size += count
}
result := buffer[0:size]
strUnsafe := *(*string)(unsafe.Pointer(&result))
doSomething(strUnsafe)
pool2.Put(testStruct)
}
func BenchmarkAdd5(b *testing.B) {
for i := 0; i != b.N; i++ {
handler5(data)
}
}依然是原来的场景,但是这一次的doSomething需要的参数不是[]byte,而是string。然后我们全部使用缓冲区的方法Add2,Add3,Add4全部都变慢了,而且每个请求都有分配一个768b的大内存。
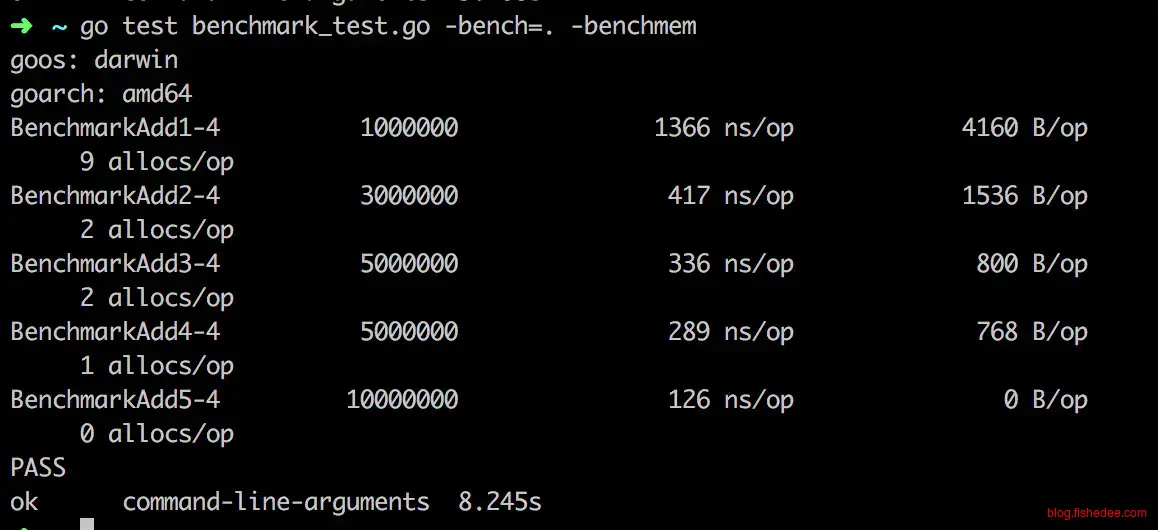
为什么?因为我们的缓冲区是[]byte类型的,不是string类型的。而string类型在golang中设计是immutable的,它不能直接使用[]byte的数据指针来构造自己的数据,因为一旦缓冲区内容变化,string的内容也会跟着变化,导致immutable的语义被违反了。所以,[]byte转string的实现,默认就是copy一次,这就是768b内存分配出现的原因。
不过,黑魔法来了,我们可以使用unsafe操作,强制将[]byte的Data指针设置为string的Data指针,避免了copy行为的出现。这就是Add5的出现,它成功地将时间降低到了126ns,而且是zero allocation。
但是,unsafe就像是黑洞,玩得好就是牛逼,玩得不好就是傻逼。如果doSomething里面的代码将这个string缓存起来,留给以后继续使用,那么当底层的[]byte被pool回收重用后,就会出现奇怪的后果。doSomething会发现传入的string虽然类型是string,但它的值会不受控制地自己变化,并不是immutabe的。
因此,这个方法仅在你知道[]byte的生命周期,也知道doSomething的生命周期时才能使用,最好只在自己的模块中内部使用,不要污染到其他模块中。
4 总结
golang的性能注意点比想象中的多,有很多隐式的操作代价都不自觉地发生,写代码时需要多加留意。最后,切勿过早优化。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!