7 树套树
int getKeyByRank(int rank);
int getRankByKey(int key);
int getKeyByRankInRange(int rank,int key1,int key2);
int getRankByKeyInRange(int key,int key1,int key2);在平衡树和线段树中,我们都能维护一个size字段,实现一个区间的rank查询,但是,这里的区间和rank都是指向key里面的数据了。
int getValueByRankInRange(int rank,int key1,int key2);
int getRankByValueInRange(int value,int key1,int key2);如果我们要求的是在某个[key1,key2]的区间中,value的rank,或者rank对应的value。那么只有一个size字段就无法实现了。这个问题被称为区间第k小值的问题。
\[ count(k)\\ st. data[k] < value ,i<=k<=j \]
对于求区间[i,j]中value这个数值对应的rank时,它的数学形式化为以上表达式
7.1 结构
7.1.1 线段树套有序数组(归并树)
\[ count(k_1)+count(k_2)+...+count(k_m)\\ st. data[k_1] < value ,i<=k_1<=i_2\\ st. data[k_1] < value ,i_2<=k_1<=i_3\\ ...\\ st. data[k_m] < value ,i_m<=k_m<=j\\ \]
归并树的想法是,将这个区间求rank的问题转换为多个子区间中求rank的问题,然后叠加起来。
在一个数组中,我们要查找第k小的数据,我们很直观的做法就是将数组排序,然后取出第k个元素就可以了。在区间查找第k小时,我们很自然的做法是让线段树的每个内部节点维护一个有序数组。
\[ tree[x].data = sort(tree[x.left].data+tree[x.right].data) \]
data域就是一个数组,每一个线段树结点都将左右两个孩子的data域取出来合并,然后排序,组成一个有序数组。
[1 2 3 5 6 7]
[1 2 5] [3 6 7]
[1 5] [2] [6 3] [7]
[1][5] [6][3]对于一个[1 5 2 6 3 7]的数组,它的线段树data域为以上
[1 6]
[1 3] [4 6]
[1 2] [3] [4 5] [6]
[1][2] [4][5]它的线段树left,right域为以上。
int getRankByValueInRange(tree,left,right,value){
if( tree.right < left || tree.left > right ){
//不相交
return 0;
}else if(left <= tree.left && tree.right <= right ){
//相交且完全包含
return getArrayRank(tree.data,value);
}else{
//相交且不完全包含
leftRank = getRankByValueInRange(tree.left,left,right,value);
rightRank = getRankByValueInRange(tree.right,left,right,value);
return leftRank+rightRank;
}
}
int getValueByRankInRange(tree,left,right,rank){
int dataLeft = 0;
int dataRight = size - 1;
while(dataLeft<=dataRight){
int mid = (dataLeft+dataRight)/2;
int rank = getRankByValueInRange(tree,left,right,sort_data[mid]);
if( rank == k ){
return sort_data[mid];
}else if( rank < k){
dataLeft = mid + 1;
}else{
dataRight = mid - 1;
}
}
throw new Exception("invalid rank!");
}那么,我们在getRankByValueInRange就很简单,将整个[left,right]区间划分为多个小的子区间,然后将这些子区间的rank值叠加就是总的rank。那么在查找区间第k小时,我们通过二分的方法,不断用mid来试探它的rank来找到就能得到getValueByRankInRange了。所以这种方法求区间第k小的时间复杂度为\(O(log^3(n))\),而求区间指定数值的rank时间复杂度为\(O(log^2(n))\)。
在建树时,我们可以借用归并排序的思路,在左右子树已经排好序的data域情况下,我们可以用归并方法直接合并两个有序数组成为一个大的有序数组。所以,建树的时间复杂度为\(O(n*log(n))\)。也因为如此,这种数据结构也被称为归并树。
在这里,我们需要仔细的研究一下时间复杂度,在getRankByValueInRange中我们需要将[left,right]区间划分为期望为\(log(n)\)个子区间,然后在每个子区间中执行一次二分查找\(log(n)\),所以,getRankByValueInRange的期望时间复杂度为\(O(log^2(n))\)。而getValueByRankInRange则是对所有的value都进行二分\(O(log(n))\),然后逐个来测试它的rank,所以时间复杂度为\(O(log^3(n))\)。
int getValueByRankInRange(tree,left,right,rank){
vector<Node*> trees = getTree(tree,left,right);
vector<int> treeRank;
temp.resize(trees.size());
int dataLeft = 0;
int dataRight = size - 1;
while(dataLeft<=dataRight){
int mid = (dataLeft+dataRight)/2;
int rank = 0;
for(int i = 0; i != trees.size();i++ ){
treeRank[i] = getArrayRank(trees[i].data,trees[i].searchLeft,trees[i].searchRight,sort_data[mid]);
rank += treeRank[i];
}
if( rank == k ){
return sort_data[mid];
}else if( rank < k){
dataLeft = mid + 1;
k -= rank;
}else{
dataRight = mid - 1;
}
for( int i = 0 ;i != trees.size() ; i ++){
if( rank < k ){
trees[i].searchLeft = treeRank[i]+1;
}else{
trees[i].searchRight = treeRank[i]-1;
}
}
}
throw new Exception("invalid rank!");
}我们可以进一步优化getValueByRankInRange,首先我们每一次测试单个value的rank时,都要将区间划分为多个子区间,我们可以先用getTree将归并树的子区间提前算出来先,以后每一次测试value的rank时就直接复用这些子区间的结果就可以了。另外,每一次测试完一个value后,我们得出的rank,不要扔掉,因为可以根据上一次rank的结果来缩小下一次搜索的范围。所以,经过这样的优化后,getValueByRankInRange的时间复杂度减少到\(O(log^2(n))\)
7.1.2 线段树套中值排名(划分树)
\[ count(k_2)-count(k_1)\\ st. data[k_2] < value ,k_2<=j\\ st. data[k_1] < value ,k_1<i\\ \]
划分树的想法,是将区间求rank的问题转化为前缀区间rank的差值。
\[ tree[x].mid = array[tree[x].left]\\ tree[x].data[k] = count(m)\\ st. array[m] < tree[x].mid,m<=k\\ st. tree[x].left<=k<=tree[x].right \]
线段树结点中,mid域代表这个数组的划分中位数(不一定是中位数,但是中位数的话线段树不会过于偏置),data域是一个数组,每个元素代表mid域在这一点前缀区间rank值。
Node partition(int data,int left,int right){
node = new Node();
node.mid = data[left];
int[] temp = new int[right-left];
int j = right - 1;
int i = left + 1;
while( i <= j ){
while( i <= j && data[i] < node.mid ){
temp[i-left] = 1;
i++;
}
while( i <= j && data[j] >= node.mid ){
temp[j-left] = 0;
j--;
}
if( i <= j ){
temp[i-left] = 0;
temp[j-left] = 1;
swap(data[i],data[j]);
}
}
swap(data[j],data[left]);
node.data = new int[right-left];
node.data[0] = 0;
for( int i = 1 ; i < right - left; i++ ){
node.data[i] = node.data[i-1]+temp[i];
}
return node;
}以上这个伪代码就是用来求一段数组所对应的线段树结点的data域与mid域的。线段树的左右子树结点就是根据划分后的data两边数据不断递归构造出来的。
举一个例子,[1 5 2 6 3 7]的数组,它的划分树结构为:
[1 5 2 6 3 7]
[1 2 3] [5 6 7]
[1 2] [3] [5 6] [7]
[1] [2] [5] [6] 这是线段树构造过程中,各个结点划分所需要的data数组,基本上就是一个快速排序的过程。
[4]
[3] [7]
[2] [3] [6] [7]
[1] [2] [5] [6]这是线段树各个结点的mid域
[1 1 2 2 3 3]
[1 2 2] [1 2 2]
[1 1] [1] [1 1] [0]
[0] [0] [0] [0] 这是线段树各个结点的data域
int getRankByValueInRange(tree,left,right,value){
if( tree == NULL || left > right){
return 0;
}
int mid = tree.mid;
int midRank = tree.data[right] - tree.data[left-1];
int leftTreeCount = tree.data[right];
if( mid == value ){
return rank;
}else if( mid < value ){
return midRank + getRankByValueInRange(tree.right,leftTreeCount,right,value);
}else{
return getRankByValueInRange(tree.left,left,leftTreeCount,value);
}
}
int getValueByRankInRange(tree,left,right,rank){
int mid = tree.mid;
int midRank = tree.data[right] - tree.data[left-1];
int leftTreeCount = tree.data[right];
if( midRank == rank ){
return mid;
}else if( midRank < rank){
return getValueByRankInRange(tree.right,leftTreeCount,right,rank-midRank);
}else{
return getValueByRankInRange(tree.left,left,leftTreeCount,rank);
}
}在计算排名时就是不断递归的过程,用节点中的mid来得到区间中的midRank,然后根据value或rank值来递归到左子树或右子树中。所以这种方法求区间第k小的时间复杂度为\(O(log(n))\),而求区间指定数值的rank时间复杂度为\(O(log(n))\)。相比来说比归并树更快,但要注意建树时要保证mid域尽可能为中位数,这样得到的线段树是最为平衡,效率最高。
在建树的过程中,我们借用了快速排序的想法,不断根据中值划分数组,并将划分后的两个数组来递归建立它的左右子树。所以,这种方法被称为划分树。显然,建树的时间复杂度为\(O(n*log(n))\)
7.1.2 线段树套平衡树
无论是归并树和划分树,它们都是静态区间求第k大的方法,一旦区间中的数据能被修改时,归并树和划分树就会gg。因为线段树中的每个结点都是一个有序数组,当有序数组中的一个数据发生变化时,重建这个有序数组的时间复杂度为\(O(n)\),也就是说修改时重建归并树和划分树的时间复杂度为\(O(n*log(n))\),查询时间依然为\(O(log^2(n))\)(归并树)或\(O(log(n))\)(划分树)。
因此,一个最为直接的想法是,在归并树中,线段树的每个结点从有序数组更改为平衡树,因为平衡树修改一个结点后维持有序的时间复杂度只需要\(O(log(n))\),而不是\(O(n)\)。
\[ tree[x].data = combine(tree[x.left].data+tree[x.right].data) \]
所以,我们实现了一个最简单的动态区间求第k大的方法,线段树套平衡树。线段树的每个结点中的data域都是一棵平衡树,而它的值就是左右两个子树data域的平衡树的合并。建树时我们可以用归并树的方法从下而上的建立有序数组,然后从有序数组中建立平衡树。所以,建树时的时间复杂度为\(O(n*log(n))\)。修改时,我们从修改点开始从叶子结点到根结点,删除原来的value,并插入新的value,所以修改的时间复杂度为\(O(log^2(n))\)。而查询时则和归并树一样,getRankByValueInRange时间复杂度为\(O(log^2(n))\),getValueByRankInRange则是\(O(log^3(n))\)。
注意,这个时候不能使用归并树的getValueByRankInRange的优化算法,因为优化算法要求每一步都能根据上一次的value来缩小这一次value的搜索范围。但是平衡树在搜索完这一次的value后,比这个value小的数据,可能在它的左兄弟子树,也可能在它的左孩子子树。比这个value大的数据,可能在它的右兄弟子树,也有可能在它的右孩子子树。各种情况都不一定,下一次的搜索范围不能简单地归结在一棵树中,所以优化算法用不了(当然用Splay树旋转当前value到根部是可以的,但Splay的常数项实在太大,是一般线段树的5倍,所以用Splay做这个优化反而得不偿失)。
7.1.3 主席树
在线段树套平衡树以后,我们发现内部结点为平衡树时,我们无法实现getValueByRankInRange的优化算法。一个很直接的想法是,能不能用线段树代替内部的平衡树。内部的线段树要做指定value的rank时,这棵线段树就是一棵权值线段树,也就是线段树的值是值域,而不是下标。但是当内部结点是权值线段树,而不是平衡树时,有一个严重的问题。平衡树是按需插入结点的,所以所有平衡树的空间复杂度大概为\(O(2n)\),但是权值线段树是静态的,它的value在开始时就已经全部确定好了,也就是说,每个结点的权值线段树空间复杂度为\(O(n)\),一共有\(O(n)\)个结点,所以,这样做的话,所有权值线段树的空间复杂度大概为\(O(n^2)\)。建树的时间复杂度不可能少于空间复杂度,所以至少为\(O(n^2)\),这明显是不可行的。
当我们仔细考虑这个问题时,发现从叶子结点开始,每棵权值线段树的大部分结点的数值都为0。各个权值线段树之间的结构都是很相似的,我们希望有一个动态的结构,让相似的权值线段树之间共享一部分相同的结点。
每次修改权值线段树时,我们都在原来的权值线段树上修改,如果左子树没有变的话,就沿用左子树的原来的结点,如果右子树没有变的话,就沿用右子树的原来的结点。反之,如果左右子树单独有变的话,我们只需要复制一部分新的结点来存储这个新的数值。这样的话,我们每次修改一个线段树单个叶子结点的时间复杂度为\(O(log(n))\),同时我们又能得到两棵完全不同的线段树。
就这样,我们得到了一个新的线段树结构。每次的修改都能获得一个新的线段树,而不是在原来的线段树上直接修改,也就是说,我们可以在修改的同时随意获取历史版本的数据结构。这种新的结构称为可持久化数据结构,对于权值线段树而言,就是可持久化权值线段树。我们对此有一个简化的名字,主席树。
Node* Inc(Node* tree,int value,int count){
if( tree == NULL ){
return NULL;
}
Node* newTree = new Node();
*newTree = *tree;
newTree->count += count;
Node* leftTree = tree.leftChild;
if( value <= leftTree.right ){
newTree->leftChild = Inc(tree.leftChild,value,count);
}else{
newTree->rightChild = Inc(tree.rightChild,value,count);
}
return newTree;
}这是主席树中自增某个value的count的做法,时间复杂度为\(O(log(n))\)
Node* Combine(Node* leftTree,Node* rightTree){
if( leftTree == NULL || leftTree->count == 0 ){
return rightTree;
}
if( rightTree == NULL || rightTree->count == 0 ){
return leftTree;
}
Node* newTree = new Node();
newTree->count = leftTree->count + rightTree->count;
newTree->left = leftTree->left;
newTree->right = leftTree->right;
newTree->leftChild = Combine(leftTree->leftChild,rightTree->leftChild);
newTree->rightChild = Combine(leftTree->rightChild,rightTree->rightChild);
return newTree;
}这是两个主席树的合并代码,时间复杂度取决于两个主席树有多少的零值点,零值点越多,时间复杂度越低,最低为\(O(log(n))\),零值点越少,时间复杂度越高,最高为\(O(n*log(n))\)。
最后主席树的结点回收可以用引用计数法来实现。
7.1.4 前缀和套主席树
对于静态区间的主席树,我们可以用前缀和套主席树来实现。
Node* BuildTree(Node* preTree,int value){
return Inc(preTree,value,1);
}对每个区间[1,i]建立一棵主席树,共连续建立n棵主席树。由于区间之间只有一个数字的不同,所以建立这n棵主席树的时间复杂度为\(O(n)\)
\[ count(k_2)-count(k_1)\\ st. data[k_2] < value ,k_2<=j\\ st. data[k_1] < value ,k_1<i\\ \]
那么,计算value的rank时,我们可以划分树的想法,转化为两棵主席树之间的差。
int getTreeRank(Node* tree,int value){
Node* leftChild = tree->leftChild;
if( value <= leftChild->right ){
return getTreeRank(leftChild,value);
}else{
return leftChild->count+getTreeRank(tree->rightChild,value);
}
}
int getRankByValueInRange(Node** treeList,int left,int right,int value){
int rightRank = getTreeRank(treeList[right],value);
int leftRank = getTreeRank(treeList[left-1],value);
return rightRank - leftRank;
}所以,getRankByValueInRange的时间复杂度为\(O(log(n))\)。
int getValueByRankInTwoTree(Node* rightTree,Node* leftTree,int rank){
int currentValue = rightTree->rightChild->left;
int currentRank = rightTree->leftChild->count - leftTree->leftChild->count;
if( currentRank == rank ){
return currentValue;
}else if( currentRank < rank ){
return getValueByRankInTwoTree(rightTree->rightChild,leftTree->rightChild,rank-currentRank);
}else{
return getValueByRankInTwoTree(rightTree->leftChild,leftTree->leftChild,rank);
}
}
int getValueByRankInRange(Node** treeList,int left,int right,int rank){
return getValueByRankInTwoTree(treeList[right],treeList[left-1],rank);
}getValueByRankInRange就比较神奇了,它使用的是归并树的优化算法,每次都是对两棵线段树的差值差线段树进行二分查找,所以时间复杂度为\(O(log(n))\)。
就这样,我们用前缀和套主席树实现了静态区间的第k大问题,和划分树一样具有最优的时间复杂度。
7.1.5 线段树套主席树
有了前缀和套主席树,以及线段树套平衡树的基础后,我们很自然地就会想到线段树套主席树。直接使用前缀和套主席树,在遇到动态区间时会有问题,因为修改其中一个位置的元素,会触发[i,n]区间中的所有主席树都需要进行修改,所以,修改的时间复杂度为\(O(k*log(n))\)。
所以,我们用线段树代替前缀和,每个线段中的结点放入一棵主席树,当某个位置修改时,我们沿着叶子结点到根结点更新每一棵主席树就可以了,所以,修改的时间复杂度为\(O(log^2(n))\)
getRankByValueInRange的时间复杂度为\(O(log^2(n))\),getValueByRankInRange使用的是类似前缀和套主席树的方法,只是每次需要将\(log(n)\)个子区间的count数叠加一起而已。所以,getValueByRankInRange的时间复杂度依然为\(O(log^2(n))\)。
最后,特别要提一下是建树的方法。一种简单的方法是开始时假设区间中每个位置的数字都是0,所以线段树中所有的主席树都是指向同一棵全为0值的主席树。然后用modify的方法逐个更新每个位置的数值,所以,总的时间复杂度为\(O(n*log^2(n))\)。
另外一种方法是一开始就将叶子结点都设置好,然后从叶子结点到根部,将左右两个子树的主席树合并为一棵主席树,这里会使用到主席树的合并方法。越靠近叶子结点的主席树合并时所需的时间就越少,因为左右两子树的零值特别多。可以被证明,时间复杂度为\(O(n*log(n))\),比第一种方法要更快。
由于这个方法中间套的是主席树,不是平衡树,所以运行的常数比较小,而且比线段树套平衡树有时间复杂度上的优势。因此这个方法总体上比线段树套平衡树要快得多。
7.1.6 平衡树套主席树
如果区间不仅需要支持修改某个位置,还需要支持插入区间元素,那么外层就不能再用线段树了,而只能使用平衡树。
总体的思路是,外层用的是替罪羊树,内层用的是主席树,当检测到数据严重不平衡时,直接将数据打平然后重建,这样做的话中间会建立较多的主席树,要注意回收空间。
查询,插入,删除和修改的时间复杂度都是\(O(log^2(n))\)。
7.2 用途
7.2.1 第kth数
int getValueByRankInRange(int rank,int key1,int key2);
int getRankByValueInRange(int value,int key1,int key2);就是支持区间中的第kth数了,没什么好说的。
8 高维树
无论是平衡树还是线段树,它们讨论的都是在一维上的点,这些点有着明确的全序关系。但是,对于在二维平面,三维立体等高维空间中,点与点之间没有明确的大小关系,如何对这些点进行索引就是一个问题。
8.1 B树
B树严格的来说,不属于高维树,但它是R树的基础,所以,先介绍它。B树仍然是一维中点的索引结构,只是它每个结点比较大,适合在磁盘中块存取中使用,所以为数据库主要的索引结构。
8.1.1 结构
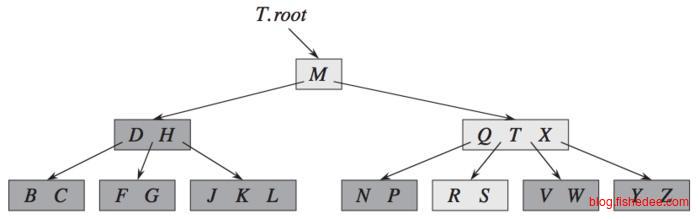
这是一棵典型的B树结构(d为它的度),它的约束为:
- 每个叶子节点具有相同的深度
- 除根节点外,其它节点至少有d-1个关键字
- 每个节点至多包含2d-1个关键字
bool BTreeFind(Node* tree, int key){
int index = binarysearch_lower(tree.data,key);
if( tree.data[index] == key ){
return true;
}else{
return BTreeFind(tree.subtree[index],key);
}
}B树的查找相当简单,首先在当前块中寻找结点,找不到的话找结点当前下的子树就可以了。
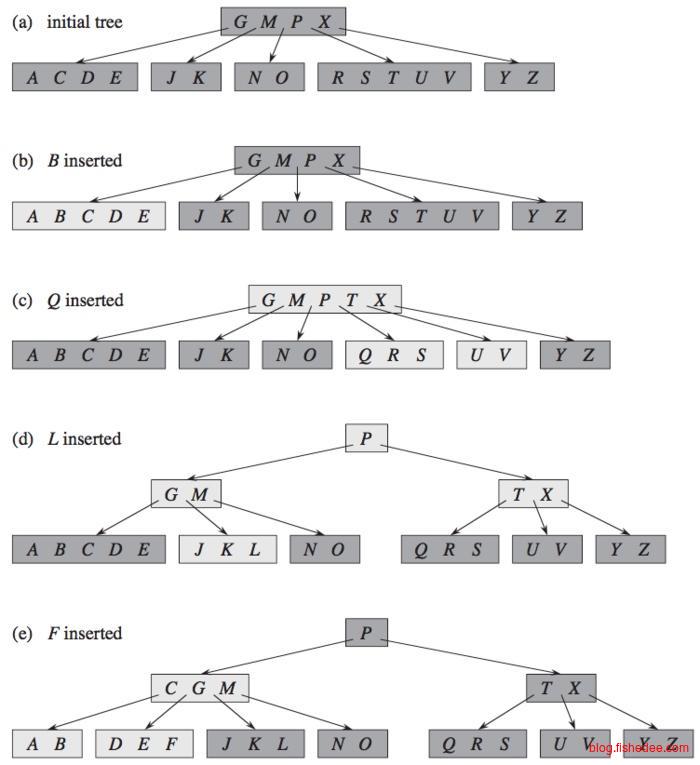
B树的插入有两种方法:
- 自顶向下分裂,从根结点开始搜索到底部结点时,只要遇到的结点如果是满的,就将这个块分裂为两个部分,然后将块的中位数插入到上一层结点去。
- 自底向上分裂,从根结点开始搜索到底部结点时,一直都不分裂,仅在依靠底部结点分裂产生的中位数插入到上一层去,上一层放不下时就继续往上一层分裂,直至根部为止。
两种方法的时间复杂度是一样的,第一种方法是遇到满的就分裂,第二种方法是只有在必要时才分裂。所以第二种方法会造成部分请求的操作时间会长一点(延迟高),但整体的操作时间会少一点(吞吐量大)。对于实际的应用而言,第一种方法会更好,不需要回溯,而且存取块更少。
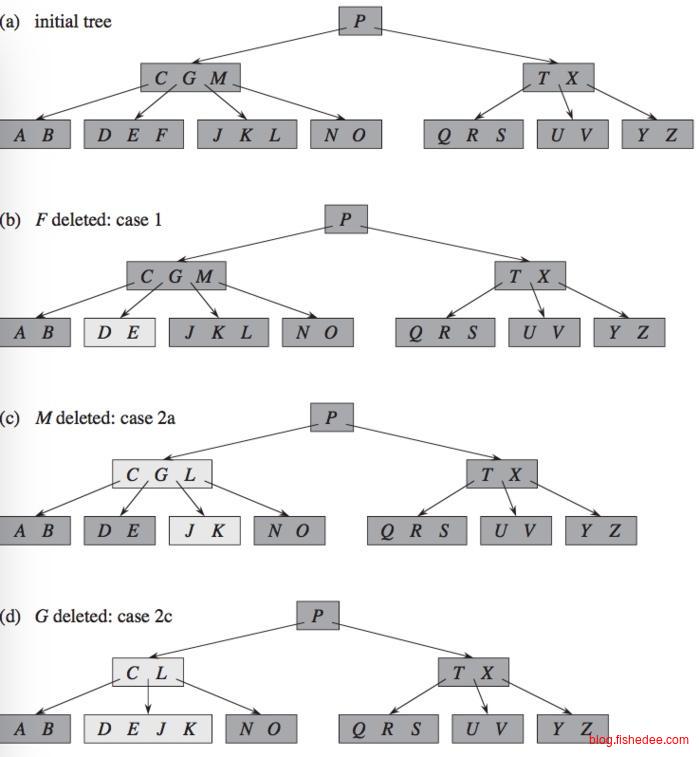
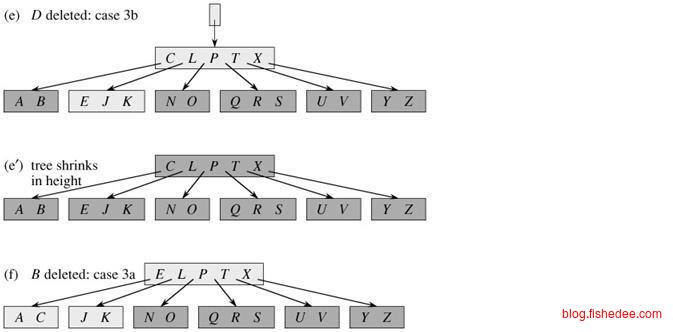
B树的删除有两种方法:
- 自顶向下合并,从根部往下搜索到结点的过程中,只要某个结点块的长度为d-1,就将它的左右兄弟结点(度大于等于d)中接一个元素过来,或者与它的兄弟结点(度等于d-1)合并。在找到结点后,这个结点是内部结点时,就从它的左右孩子借一个结点来代替,这个结点是叶子结点时,将直接删除,如果删除度少于d-1,就和兄弟结点借用或合并。这个过程中,最多只需要回溯一次。
- 自底向上合并,从根部往下搜索到结点的过程中,一直都不合并兄弟块。在找到结点后,这个结点是内部结点时,就从它的左右孩子借一个结点来代替,这个结点是叶子结点时,将直接删除,如果删除度少于d-1,就和兄弟结点借用或合并。当与兄弟结点合并时,又可能导致父亲结点的度少于d-1,需要再次回溯到祖父结点。最坏情况下,这个过程可能需要不断回溯至根结点。
两种方法的时间复杂度是一样的,第一种方法是遇到度为d-1的就合并,第二种方法是只有在必要时才合并。所以第二种方法会造成部分请求的操作时间会长一点(延迟高),但整体的操作时间会少一点(吞吐量大)。对于实际的应用而言,第一种方法会更好,不需要回溯,而且存取块更少。
8.1.2 用途
B树的用途和普通平衡树是一样的,时间复杂度也差不多,不过它是通过内部结点块的数量与度的关系来调整树的高度,不需要平衡树的平衡操作。当然,B树没有平衡操作,也就做不了像Splay树的区间操作了。
8.2 kd树
8.1.1 结构
kd树的结构相当简单,它每次只通过一个维度将数据划分为两半,那么每次划分的维度选择的x轴还是y轴,有两种方法,要么轮着x,y轴来划分,要么每次选方差最大的轴来划分。
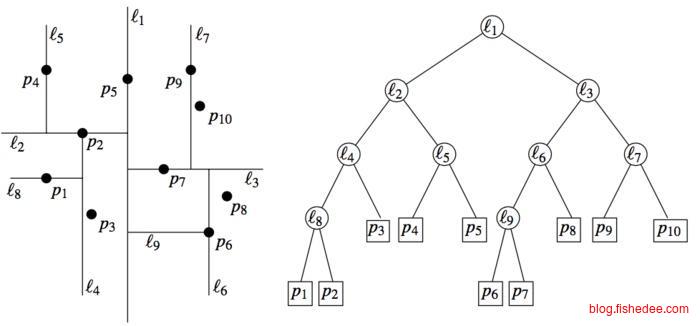
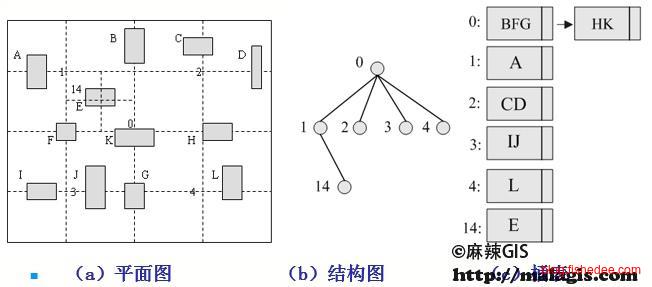
例如,使用轮着划分的方法,划分轴分别是l1,l2,l3,l4,l5,l6,l7,l8,l9。要注意的是,kd树的内部结点中不存储数据。

这是二维数据建树的算法,使用的是轮着x,y轴来划分的方式,算法复杂度为\(O(n*log(n))\)

kd树的查询算法相当简单,输入一个区域,然后返回这个区域中所属的所有点。查询算法为对左子树区域作为交集判断,相交就递归查询左子树区域。同样地,对柚右子树叶进行相同的操作。
kd树的插入操作,不断插入到区域中,如果区域的严重不平衡,那么就借用替罪羊树的想法来打破重建。这样做的话意味着有些插入操作会耗时过长,延迟较高。
kd树的删除操作,由于数据都在叶子结点,删除时直接删除叶子结点,并将另外一个孩子和根结点合并就可以了。同样地,当检测到左右子树严重不平衡时,暴力地打破重建就可以了。
8.1.2 用途
void add(point Point);
void del(point Point);
void build(points Point[]);增删查的操作都可以实现,要注意的是,增删操作对于kd树来说不太适用,可能造成延迟过大。更多常用在静态数据的空间查询问题中。
bool exist(point Point)
Point[] getByRegion(r Region);和平衡树一样,它既可以做单点的查询,也可以做范围的查询,也就是区域查询了。
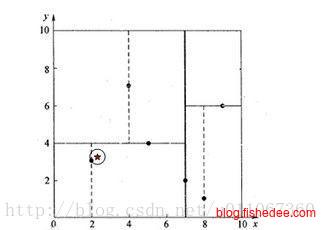
Point[] getKNN(point Point);另外一个在机器学习中常用的做法是,查找某个点的最近k个点,方法是先寻找到这个点最近区域,然后建立了一个这个点为中心,叶子结点为半径的圆。最后不断回溯到根部,只要左右子树中有和这个圆相交的区域,就将这个区域的点作测试,看有没有更加近的点。注意的是,当找到新的近点时,就更新圆的区域。
8.3 四叉树
8.3.1 结构
8.3.1.1 点四叉树
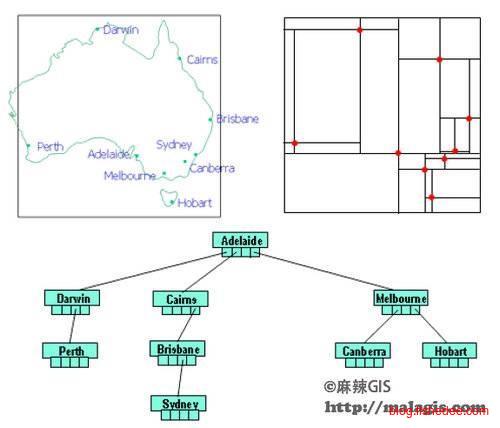
点四叉树和kd树十分相似,依赖于数据本身来进行划分,kd树是按照每个点按照维度划分为两个部分,点四叉树是按照每个点将所有维度划分为四个部分。选择中间点的规则是按照靠近x轴和y轴的中位数的点就可以了。
8.3.1.2 PR四叉树
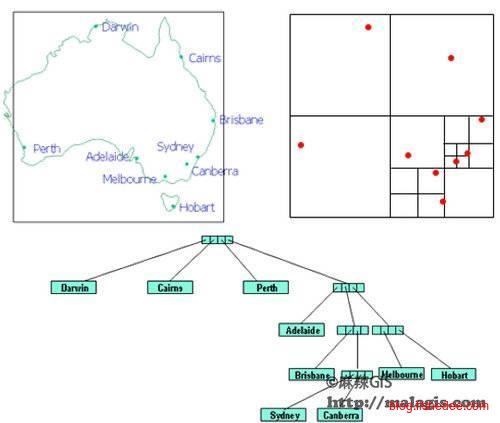
PR四叉树的想法是不再按照数据本身划分区域,而是按照数据的值域来划分区域。就像权值线段树一样,这样做的好处很明显,插入和删除都不需要考虑平衡问题,每个操作的延迟都很低。但要注意,这样的结构需要预先就考虑好值域的范围。
8.3.1.3 MX四叉树
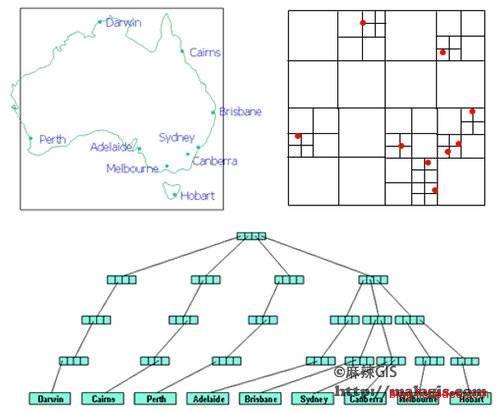
MX四叉树是PR四叉树的进一步扩展,它在建树时不仅需要考虑值域的范围,也需要预先就考虑好树高。所有的结点都是递归到同一层的叶子结点去,会有一个指针将底层的所有叶子结点都串起来。这样做的好处是,插入和删除时的延迟更加低。但是,由于平均的树高比PR四叉树要高,所以MX四叉树的搜索效率不及PR四叉树。
8.3.1.4 CIF四叉树
在空间中,不仅需要存储点,也需要存储子空间。在二维空间中,我们需要存取的就是矩形。CIF四叉树在PR四叉树的基础上加入了存取区域的方法,在每个值域分割的过程中,如果区域与分割线相交,就将其放到内部结点就可以了,否则就单独地放入到叶子节点上。
8.3.2 用途
void add(point Point);
void del(point Point);
bool exist(point Point)
Point[] getByRegion(r Region);
Point[] getKNN(point Point);除了像kd树一样的增删查操作外,效率还比kd树更快,延迟更低。
void addRegion(region Region);
void delRegion(region Region);
bool existRegion(region Region);
Region[] getRegion(region Region);还有区域的增删查操作。
8.4 R树
8.4.1 结构
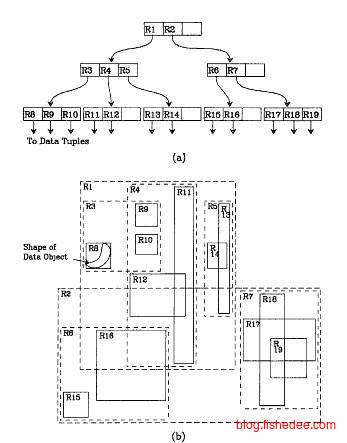
kd树对静态数据的索引是最好的,四叉树对动态数据的索引是最好的,但是空间浪费比较严重。在块存储中,直接使用四叉树作为空间索引是很有问题的,每个块的内容大部分内容都是空的,而且需要读取的块太多。所以,在块存储中,我们希望获得一个每个块的利用率高,块存取次数少,支持插入和删除数据的动态空间索引结构。很自然的,我们从B树扩展到R树解决了这个问题。
首先,不能使用值域来划分区间,这样会造成块的利用率低。然后不能使用旋转来平衡树,因为空间中的区域与点是没有明确的全序关系的。最后不能使用替罪羊树的方法来平衡,因为这样会造成部分操作的延迟太大。
R树的解决办法是让多个子树的区域允许是重叠的,而且和B树不一样的是,R树的内部结点不放数据,只放子树的合并区域,数据都放在R树的叶子结点上了。
所以,R树的查询和B树不太一样的,它读取一个块以后,不能直接用二分搜索定位在哪个子树中。它需要将读取块与每个子树块作相交的测试,需要将多个子树的结果合并返回出去的。所以,R树的查询复杂度并不是\(O(log(n))\),这只是一个期望下的时间复杂度。
另外,R树在插入时,插入的区域与多个子树是相交时,它会选择和子树块合并后增加面积最小的子树来插入。那么,在插入后,可能会面临需要将一个块分裂成两个块的情况。这个时候,R树会选择分裂后两个块的面积之和最小的分割方式,这样的时间复杂度为\(O(n!)\)。另外一种启发式合并策略是,先找出两个分裂结点的代表子树,然后将剩余的子树都分类都这两个代表子树中,这样时间复杂度为\(O(n^2)\)
最后,R树在删除的时候,直接在叶子结点删除即可。那么,在删除后,可能会面临需要将两个块合并成一个块的情况。这个时候比较简单,选择合并后的两个块增加的面积最小就可以了。
具体看这里
8.4.2 用途
跟四叉树的用途是一样的,这里就不多说了。
9 正排与倒排索引
我们之前说的平衡树,和线段树都是针对单个字段的索引操作的,如果需要涉及多个字段的交集和并集的操作,我们还需要在这之上加入正排和倒排索引。例如,在每篇文章有title和content两个字段,我们输入“IT狂人”这个关键词,我们实际上要做的是:
\[ docId\\ st. <it> \in data[docId].content 或 <狂人> \in data[docId].content \\ st. <it> \in data[docId].title 或 <狂人> \in data[docId].title\\ \]
也就是说,我们先将关键词划分为两个term,然后求每个term在content中和在title中的docId的并集,最后再求多个term的交集就可以了。
9.1 倒排索引
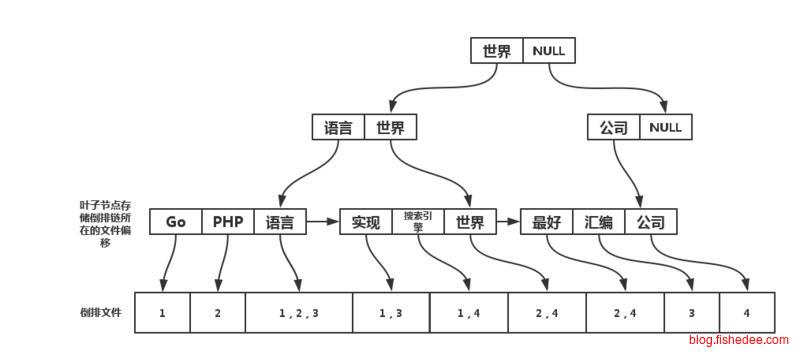
一个简单直接的方法,是将所有的term建立一个搜索树,可以用tire树,B树,哈希等方法。然后每个term对应的value就是term里面的docId。当需要求多个字段的交集和并集时,就先计算每个term后对应字段的docId集合,然后求这几个集合的交集和并集就可以了。为了让多个集合的交集和并集的运行速度更快,我们每个term对应的docId集合都是预先排好序的。这个方法就就叫为倒排索引,索引用的依然是之前说的tire树,B树,哈希等方法,而被索引的值是一个倒排链,是有一个有序的数组。你可以简单的理解为倒排索引就是索引+有序数组的方法。
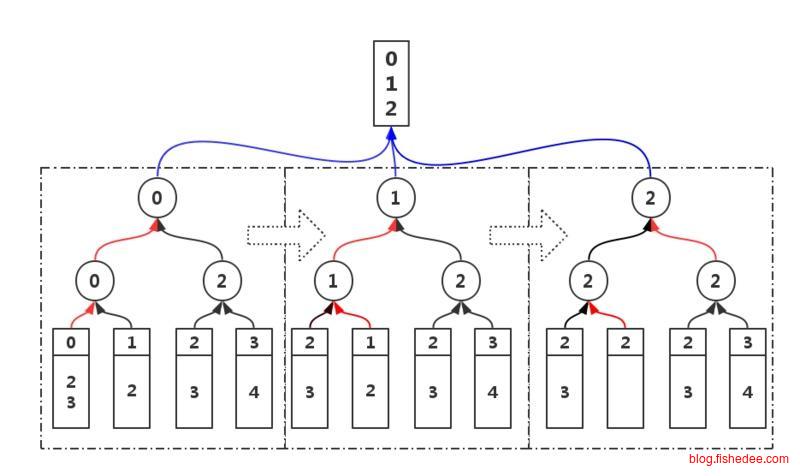
多个有序的docId集合求并集时,将多个倒排链连在一起,然后用赢者树合并就可以了。时间复杂度为\(O(n*log(k))\),其中k是集合的数量,n是集合的所有元素数量。
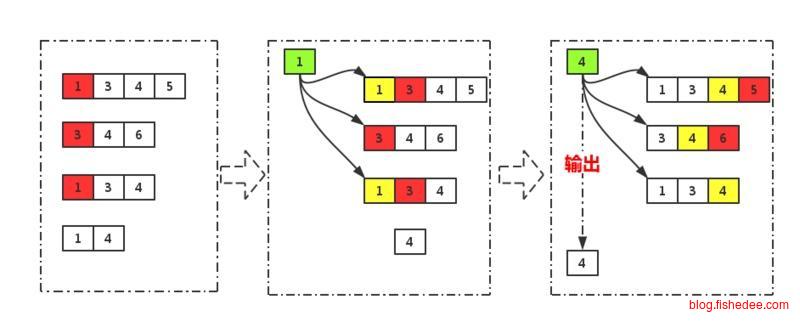
多个有序的docId集合求交集时,很明显,我们也能用赢者树合并的方法,时间复杂度也是为\(O(n*log(k))\)。但是,我们可以做得更快,因为交集不是所有元素都需要的,我们可以根据有序的关系作一个优化:
- 取所有集合中数量最小的那个集合,然后从标称数组中依次取出每个元素,查看元素是不是在其他的每一个倒排链中。
- 查看元素是不是在其他的每一个倒排链中时,只要其中一个倒排链不存在,就能直接忽略后面的倒排链的搜索操作。
- 查找元素是否存在时不需要使用头部比较方法,直接在数组中执行二分搜索就可以了。
- 为了让每次二分查找的范围越来越少,我们引入了哨兵方法。例如,我们在标称数组找到第一个1个元素后,我们查找第二个元素4。由于第二个的元素比第一个元素大,所以他在其他倒排链查找时,可以接着上一次的搜索位置为起始点来搜索,而不是对整条倒排链搜索。
所以,经过这样的优化,求交集的时间复杂度为\(O(N_1*k*logN_k)\),这里的\(n_1\)是标称数组的长度,\(k\)是集合的数量,\(N_k\)是其他倒排链的平均长度。由于\(N_1*k<< N\)在大多数情况下都是成立的,所以这个方法比直接用赢者树求并集的方法要更快。
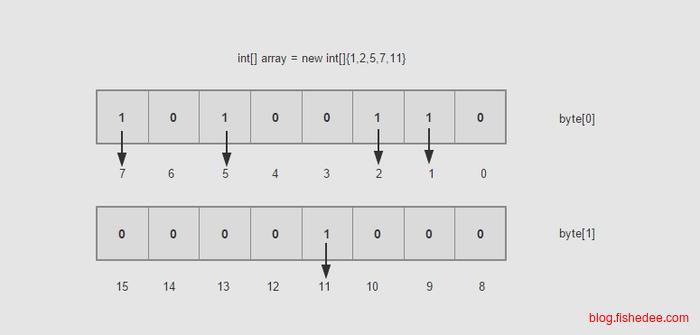
由于倒排链是一个有序数组,进行删除时,速度很慢,时间复杂度为\(O(n)\)。如果倒排链要保持有序,同时速度也很快,我们自然想使用平衡树,但是平衡树在做并集和交集时速度比起有序数组要慢很多。更好的办法是,将数据划分为存量数据和增量数据两部分。然后删除数据时就在bitmap上标记一下,搜索时检查一下bitmap的数据就可以了。
插入数据也是一样,直接插在倒排链时,速度也很慢,更好的办法就是在内存建立一份增量数据,当达到一定程度后,就将这份增量数据保存到磁盘中就可以了。磁盘中的多份增量数据达到一定程度后又合并起来就可以了。
修改数据,就是删除数据然后插入数据而已。
9.2 正排索引
价格正排数组 : [ 5000,1999,3999 ]
品牌正排数组 : [ 锤子,小米,华为 ]正排索引很简单,就是一个大的数组,每个字段建立一个数组。以docId作为key就能在\(O(1)\)时间内查询docId对应字段的数据了。正排索引的主要作用是在字段的过滤操作,例如,过滤价格在某个区间的商品,过滤品牌为指定牌子的商品等等。
9.3 搜索引擎综合
搜索引擎的设计与数据库的设计是不一样的,数据库追求的是ACID属性,它要求修改和查询操作都是原子的,隔离性的,而大部分的查询操作倒是挺简单的,是一个写多读小的目标。搜索引擎刚好就是反过来,它的目标是写小读多,修改的操作简单,而且不要求隔离性和原子性,但是查询操作就是复杂,而且多变的。
基于搜索引擎的这个目标,直接套用B树存储在磁盘上不合理的,因为B树的交集和并集操作很慢,所以采用的是有序数组来实现倒排链。而且在前面的论述中也可以看出,搜索引擎使用的是,用静态结构来存储存量数据,然后使用内存加定时持久化来构造增量数据。查询的时候同时将存量数据和增量数据的结果合并起来就可以了。这样就能实现查询时效率足够高,而且修改操作时时间复杂度也不会太高。
我们总结一下这样做的时间复杂度:
- 查询,并集为\(O(n*log(k))\),交集为\(O(n_1*k*log(n_k))\)
- 插入,\(O(1)\),在内存中直接插入数据,然后达到一定程度后由异步任务刷新到磁盘的索引文件中。
- 删除,\(O(1)\),直接更新磁盘中的bitmap索引就可以了。
- 修改,\(O(1)\)。
除了这些基础的算法和结构中,我们还有一些工程上的优化。
9.3.1 顺序优化
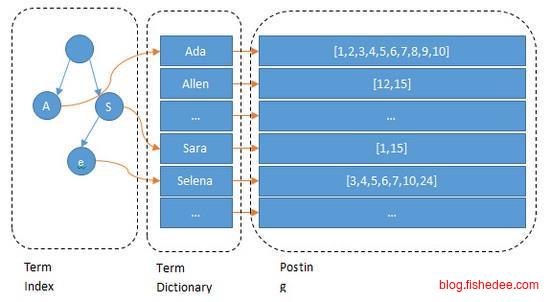
由于倒排链比较大,磁盘中的Term Dictionary的节点是不会直接存放倒排链的,每个节点只会放倒排链的offset和count的信息,然后所有的倒排链都直接放到一个文件中去。这样做的话,Term Dictionary就能占用很小的空间,磁盘的邻近io操作都是接近顺序读取,而不是随机读取的。
9.3.2 结构优化
结构优化有:
- 每个记录都有一个id。而这个id是搜索引擎控制的,全局递增的整数,不是由输入数据所产生,或使用者能指定的。这样做的话,在内存中的倒排链直接也用数组就可以了,不需要用平衡树,直接在尾部添加就是有序的。
- 倒排链使用压缩跳表的方式。由于倒排链都是顺序递增的,相邻元素中改用差值,而不是绝对值能表示,这样每个元素的值更小,能用更紧凑的方式存储。压缩的好处是什么,能大大提高一次io操作中读取到的数据,降低总的io次数。由于元素的值是紧凑表达的,每个占用的空间也不太一样,直接用二分搜索是不行的,这个时候我们可以用skipList。
- 倒排链使用压缩位图索引的方式。位图索引在term数据是密集分布时求交集和并集时速度更快。
9.3.3 内存与磁盘的处理
如何将内存作为磁盘的缓存,实现更快的速度:
- Term Index,由于整个Term Dictionary实在太大,无法整个保存到内存中。所以,我们采用Term Index的方法,将Term Dictionary中的单词以前缀划分为多个类别,然后根据这些类别在内存中建立Tire树就可以了。
- Mmap,读取倒排链和正排索引时,我们可以用mmap的方法读取这个大文件,然后由系统来控制换页,频繁读取的页就一直放在内存中,不频繁的页会自动替换到磁盘中去。
9.3.4 增量与全量的处理
增量与全量的处理,是实现高效的修改和查询的关键:
- 索引与查询分离,由于增量数据会产生索引,如果同一部机器既要做内存的增量数据,又要做内存数据落地时的索引生成,难免会遇到查询与索引一起执行时的卡顿问题。解决方法是,让一些机器只做全量数据查询,另外一些机器只做增量数据存储与索引生成,也就是索引与查询分离。
- 全量索引的时机,全量索引就是将存量索引,增量索引与bitmap表合并起来,成为一份存量索引。这样做的好处查询更快,但是合并时的速度比较慢,不可能经常都这么做。所以全量索引的时机,既要考虑产生新数据的频率,也要考虑生成时的查询繁忙情况。
10 字符串
对于字符串的查找,我们可以用B树,每个结点都放多个字符串,搜索时对字符串进行比较就可以了。但是这样做比较慢,主要原因在于,字符串比较大小的代价比较高。
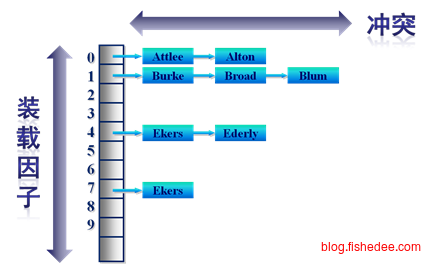
然后我们转为使用哈希索引的办法,将字符串映射到一个数字上,然后根据这个数字哈希到不同的桶上。但是这样的问题在于,经过哈希以后的字符串就失去它们之间的排序关系,无法根据前缀来查找其他字符串了。例如,查找”中华”开始的其他单词。
所以,字符串这一章主要考虑的是针对字符串的这种数据,我们如何设计一个高效的索引,不仅性能好,而且保持了排序的关系。
搜索单词:abcde
单词词库:abd abe abcdef索引结构首先要解决的是,多串查询问题,输入一个单词,问这个单词是否在词库中出现过,如果没出现过的话,与他最靠近的单词是哪个?
搜索句子:abcdefg
单词词库: bck bcd cd de索引结构要解决的另外一个问题,多串匹配问题,在一个句子问他在词库中出现过的单词有哪些,包括重叠和不重叠的。在上面这个问题中,匹配的单词有:bcd,cd和de三个。
10.1 Trie树
10.1.1 结构
10.1.1.1 朴素Trie树
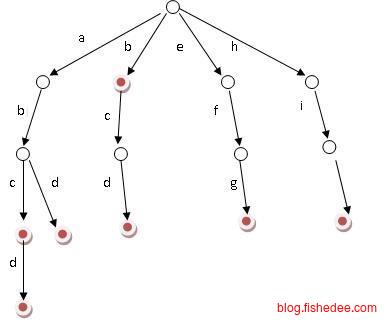
Trie树的想法是按照每个字符串的单个字符来划分每一层,例如,以上是词库b,abc,abd,bcd,abcd,efg,hii所组成的Trie树。
struct Trie{
Trie*[26] next;
bool isWord;
}
bool find(string data){
Trie* state = root;
for( int i = 0 ; i != data.size() ; i++ ){
state = state->next[data[i]-'a']
if( state == NUL ){
return false;
}
}
return state->isWord;
}朴素的Tire树实现中,每个结点都是一个数组,以及一个标志是否为单词的结尾。查找时按照字符逐个转移状态就可以了。时间复杂度与单词库的数量无关,只与输入的单词长度有关,所以时间复杂度为\(O(k)\),k为单词的字符长度。显然,要比B树要快得多,而且还保留了排序的能力。
当字符不仅仅限于英文字母,数字,还包括中文时,我们就要注意了,我们首先建立一个字符到编码的映射,将所有单词中出现的字符放入哈希桶中,用一个自增id来确定它的编码就可以了,所选用的哈希函数可以是utf-8编码或者是gbk编码。
最后,这个方法效率是很高的,问题是占用空间太大,每个结点的next数组绝大部分都是空的,数据是高度稀疏的。空间复杂度为\(O(k*m)\),其中k是结点数量,m是字符数量。所以,这种方法的Trie树建树速度是非常慢的。
10.1.1.2 表格Trie树
由于朴素的Trie树中主要的存储都是数组,所以,我们可以将多个数组合并到一个矩阵里面,竖轴是状态,横轴是编码,每个元素代表当前状态在特定编码下转移到状态。但是,Trie树中还需要一个isWord的字段代表是否为单词结尾,解决办法是,让状态都是正数,用正负号代表是否isWord。
int trie[STATE_NUM][CODE_NUM];
bool find(string data){
int state = 1;
for( int i = 0 ; i != data.size() ; i ++ ){
if( state < 0 ){
state = -state;
}
state = trie[state][data[i]-'a'];
if( state == 0 ){
return false;
}
}
return state < 0 ;
}就是这么简单,空间复杂度和时间复杂度和朴素Trie树是一样的,只是常数要小一点。
10.1.1.3 链表Trie树
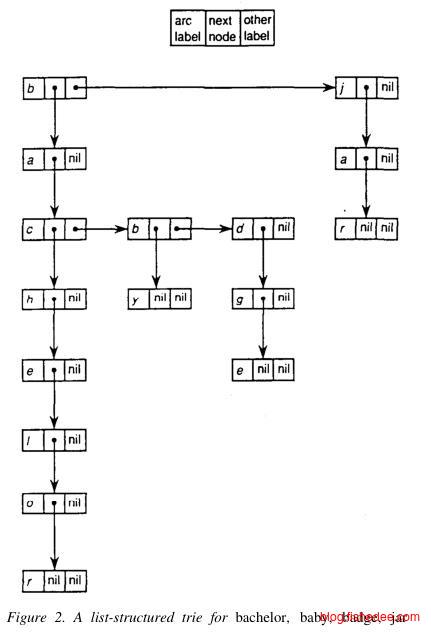
既然每个节点存放的是数组,而且是稀疏数据的,我们很自然的想法就是使用链表来代替这个寻址的数组。
struct TrieInner{
Trie* next;
char data;
}
struct Trie{
list<TrieInner> next;
bool isWord;
}
bool find(string data){
Trie* state = root;
for( int i = 0 ; i != data.size() ; i ++ ){
Trie* nextState = NULL;
for(list::iterator it = state->begin();
it != state->end() ; it++ ){
if( it->data == data[i] ){
nextState = it->next;
break;
}
}
if( nextState == NULL ){
return false;
}
state = nextState;
}
return state->isWord;
}这样的空间复杂度要少很多,基本上就是词库的大小。但是时间复杂度也比较高,最坏情况下的时间复杂度为\(O(m*k)\),k是搜索单词的长度,m是编码的长度(在这个例子中为27)
10.1.1.4 哈希Trie树
struct Trie{
hash<char,TrieInner> next;
bool isWord;
}另外一个很自然的想法,是用hash代替链表Trie树中的链表,这样每个节点计算转移状态时,时间复杂度期望为\(O(1)\),而且空间复杂度也比较低。是一种在空间和时间都达到平衡的结构,而且更新时的速度也很快。
但是,在编码表较小时,hash由于有最小桶数量的限制,所以依然有空间上的浪费,当编码表比较大时,桶的数量太少,冲突太多,又会影响查询上的时间。
10.1.2 用途
各个Trie树的结构均实现了多串查找的问题,但是它们都没有一个能在空间和时间上达到一个最佳的复杂度。
10.2 双数组Tire树
10.2.1 结构
无论是链表和哈希Trie树,它们都是在寻址方式上作出优化,但优化后的结构时间复杂度依然不是太理想,所以我们希望继续沿用下标寻址的方式来执行状态转移。但是,下标转移的方式会导致建立多个有大量空元素的数组。
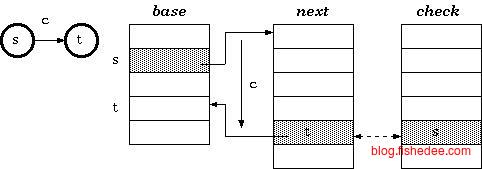
所以,我们的出发点是,将多个状态转移数组复用到一个next数组上。但是,直接复用会有问题,因为同一个位置的元素可能会有冲突。这时候,大神想出了一个方法,每个状态有一个偏移量的数据,也就是base数组,它表示复用数组next的开始位置,也就是不同状态的next数组开始位置是不一样的。这样就解决了,既要复用数组,又要避免同一个编码下会冲突的问题。另外一方面,我们需要一个check数组来确定,这个位置的归属状态是哪个,避免错误转移匹配的问题。所以,这就是三数组Trie树了。
int base[STATE_NUM];//状态数组
int next[CHANGE_NUM];//转移数组
int check[CHANGE_NUM];//检查正确转移数组
bool find(string data){
int state = 1;
for( int i = 0 ; i != data.size() ; i++ ){
if( state < 0 ){
state = -state;
}
int code = data[i]-'a';
int change = base[state]+code;
if( check[change] == state ){
state = next[change];
}else{
return false;
}
}
return state < 0;
}这就是三数组Trie树的时间复杂度真正地和朴素Trie树几乎是一样的,而由于复用了next数组,所以空间复杂度仅仅是链表Trie树的1.5倍左右。达到了空间和时间复杂度最佳平衡点。
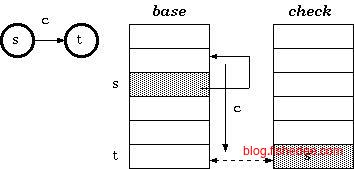
由于每个状态仅有一个字段,就是偏移量base,而next数组又是存状态字段的。一个很自然的想法是,让next数组只存偏移量不就好了,不需要再存什么状态了。这就是双数组Trie树的想法。
int base[CHANGE_NUM];//状态转移数组
int check[CHANGE_NUM];//检查正确转移数组
bool find(string data){
int state = 1;
for( int i = 0 ; i != data.size() ; i++ ){
int code = data[i]-'a';
int change = base[state]+code;
if( abs(check[change]) == state ){
state = change;
}else{
return false;
}
}
return check[state] < 0;
}由于少了一个next数组,空间更少,速度更快。
void insert(int state,int[] code){
int change = base[state];
bool ok = true;
//查找合适的base[state]位置
while( true ){
bool ok = true;
for( int i = 0 ; i != code.size() ;i ++ ){
if( base[change+code[i]] != 0 || check[change+code[i]] != 0 ){
ok = false;
break;
}
}
if( ok == true ){
break;
}
change++;
}
//找到合适的base[state]位置后,将各个code的base默认值设置为和base[state]一样的。
base[state] = change;
for( int i = 0 ; i != code.size() ; i ++ ){
base[change+code[i]] = change;
check[change+code[i]] = state;
}
}值得一说的是,双数组Trie树的构造方式,对于某个状态state,它的默认偏移和父节点是一样的,它有m1,m2,m3,m4的四个转移方式,那么它在base数组会转移到base[state]+m1,base[state]+m2,base[state]+m3,base[state]+m4这四个下标。我们需要检查这四个下标下的base数组和check数组是否都为0。如果都为0,证明没有冲突,可以直接插入。如果其中一个为0,就需要将base[state]+1,然后再测试能不能插入,显然,这是一个启发式寻找的过程。
根据插入的方式,我们可以分两种方法将词库插入到双数组Trie树中
- 逐个插入单词,逐个插入时,如果对应的code转移的base不为0,这代表冲突了,需要将父节点的base整体往后移,并且将已经设置好的其他子节点也一起往后设置。这样的冲突解决比较麻烦,而且空间利用率较低。
- BFS遍历词库的第一个字符,第二个字符等等,遍历第一个字符时,我们已经确定好父节点后有多少个子节点,所以不会出现需要已经设置好的父节点整体往后移的问题,冲突解决更少,空间利用率更高。
10.2.2 用途
双数组Trie树启发式地利用了复用同一个数组,并加入偏移量来解决冲突的问题。这是一个很好的思路,也是解决稀疏矩阵的存储的问题。最后,这个方法不仅时间复杂度上达到最优,而且空间复杂度也不高,序列化速度也很快,是Trie树的最优的实现方法。
另外,Trie树还有前缀和后缀压缩的优化算法,对于长字符串的场景来说,非常有必要。但是对于单词查找这种短字符串的场景来说,就没有什么意义。一般来说,Trie树的查询速度是哈希算法的两倍,而且还保持了前缀匹配查询的能力,实在牛逼。更让人震惊的是,这种方法不需要旋转,就能达到很好的平衡。
10.3 基数树
10.3.1 结构
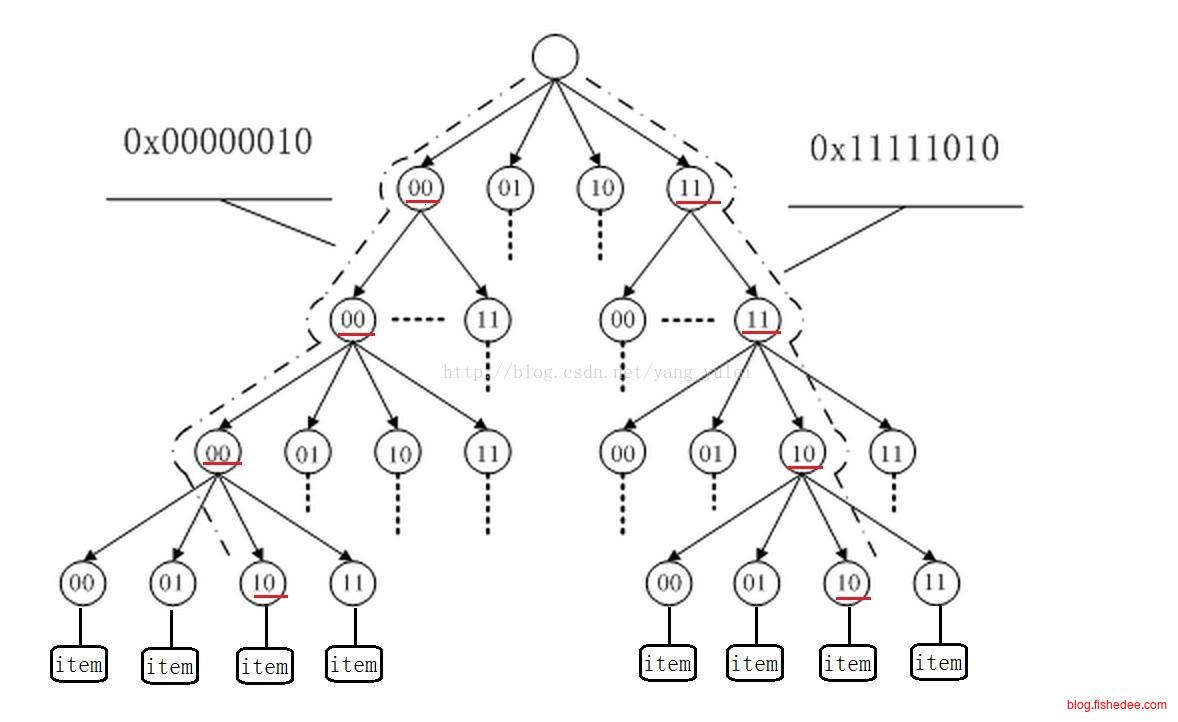
既然我们可以用Trie树对字符串进行索引,为什么不能将数字看成字符串,然后用类似Trie树的方式来索引呢,这就是基数树的想法。数字怎么转换成字符串,方法就是它的二进制串,我们可以将划分每一层的串时,我们可以用一个二进制划分一个字符,也可以用两个二进制划分为一个字符。
由于这种方法涉及到的编码很少,所以我们根本就不需要使用双数组Trie树的方式来压缩,直接用朴素Trie树就能实现很好的空间和时间的平衡。
这种基数树的方式,能实现平衡树的所有功能(当然,没有Splay树的逆天区间统计功能),同时不需要旋转,速度快到炸裂。所以linux内核的内存管理,身份鉴别使用的都是基数树实现。
10.3.2 用途
和平衡树一样的功能,但是只能对key为整数的数据使用。
10.4 AC自动机
10.4.1 结构
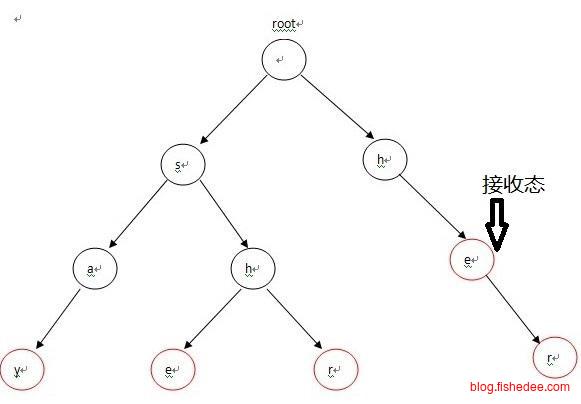
我们为{“say”,“she”,“shr”,“he”,“her”}这几个单词建立一个Trie树,我们就能实现对单词查找的问题了。但是对于句子中查找词库单词的问题,依然没能很好地解决。例如,我们要查找“sdmfhsgnshejfgnihaofhsrnihao”句子中包含的单词就很困难,trie树只能每次移动句子中的一个位置查找单词。解决办法就是将KMP算法扩展到AC自动机上,解决多串匹配的问题。
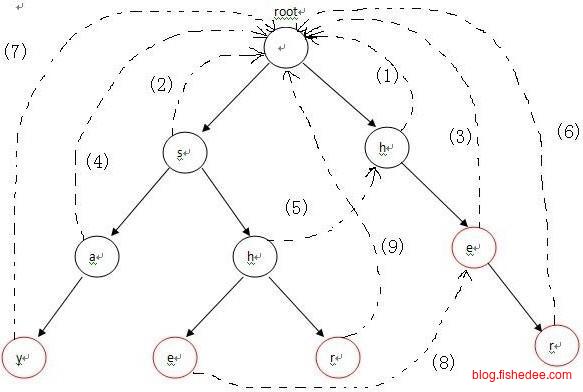
在每个节点上加入fail指针指向最长匹配前缀的其他单词去。为什么要这样做呢?例如,词库为”nihao”,“ham”,“hs”,“hsr”,句子为sdcnihamfhs。在搜索到sdcniha这个位置时,句子匹配到的单词为nihao的前四个字符niha。然后遇上了句子的下一个字符为m,显然,nihao这个单词是匹配失败的。下一次我们要重新到ihamfhs这个位置的头部重新匹配,问题在于,我们在上一次匹配时就已经知道,句子的前半部分就是niha了,下一次匹配的开头肯定是iha的,而iha与任何一个单词前缀都是不匹配的,所以如果重新匹配就会浪费时间。
那么,我们应该选择哪个位置呢,答案是在已经匹配的niha中,找到一个能匹配到词库其他单词最长前缀的单词,也就是ham这个单词就可以了。这大大加快了我们匹配的速度,因为我们充分利用了匹配失败时,已经匹配的前缀信息(niha),然后就能找到最长匹配前缀的其他单词(ham),下一次我们就能直接从m这个位置匹配,而不再需要从头开始匹配了。这个就是KMP算法思路,AC自动机只是将这个想法扩展到多串匹配而已。要实现这个想法,我们只需要在每个节点上加入一个fail指针,当该节点无法匹配时,我们就转移状态就可以了。所以,多串匹配时的时间复杂度为\(O(n)\),n为句子的长度,与词库大小无关!
\[ node[k_1].fail=k_2\\ st. node[k_2].path[1...m]=node[k_1].path[n-m...n]\\ st. max(m) \]
用数学来描述fail指针的值就是,fail指针指向的节点\(k_2\),就是节点\(k_2\)拥有了最长的前缀与当前节点\(k_1\)的后缀是相同的。
\[ node[k_1].root.fail=k_3\\ st. node[k_3].path[1...o]=node[k_1].root.path[n-o...n]\\ st. max(o) \]
而且,对于\(k_1\)的父节点,也有相同性质的fail字段。并且,\(k_1\)的后缀与\(k_1\)父节点的后缀就只差最后一个字符而已,所以,一个很自然的想法,是通过\(k_1\)父节点的fail字段来计算\(k_1\)节点的fail字段。
Node* getFail(Node* node){
//求出父节点parent,以及父节点到当前节点的转移编码code
Node* parent = node.parent;
int code = 0;
for( int i = 0 ; i != parent.next.size() ; i ++ ){
if( parent.next[i] == node ){
code = i;
break;
}
}
//树上动态规划的方法。
Node* target = parent.fail;
while( target != NULL ){
if( target.next[code] != NULL ){
break;
}
target = target.fail;
}
if( target == NULL ){
return root;
}else{
return target.next[code];
}
} 就这样,我们可以构建出一个指定节点的fail指针了。当然,更好的办法是,在父节点生成子节点时,就把子节点的fail指针一并计算好。因为这样的话,子节点就不需要反过来求parent和code了。
vector<Node*> find(string data){
Node* state = root;
vector<Node*> result;
for( int i = 0 ;i != data.size() ; i ++ ){
//查找当前后缀下的最长匹配前缀state。
int code = data[i]-'a';
while(state != NULL){
Node* nextState = state.next[code];
if( nextState != NULL){
state = nextState;
break;
}else{
state = state.fail;
}
}
if( state == NULL ){
//回溯到根节点
state = root;
}else{
//查找当前后缀的所有单词
Node* temp = state;
while( temp != NULL ){
if( temp.isWord == true ){
result.push_back(temp);
}
temp = temp->fail;
}
}
}
return result;
}这就是在句子中找出所有单词的方法,包括重叠位置的单词,这个方法中单词没有去重。注意temp指针的用法是将当前后缀的其他单词全部都搜索出来,当然,一个优化是在建树时就把相同后缀的其他单词都题全计算出来就可以了,这样就不需要temp指针。
10.4.2 用途
AC自动机解决了多串匹配的问题,包括重叠和不重叠,无论词库有多大,时间复杂度竟然保持是线性的,实在很牛逼。另外,可以结合双数组Trie树的想法优化AC自动机,这样就能得到空间和时间复杂度都很完美的AC自动机了。
11 总结
数据结构中的各种各样的结构实在叹为观止,而且比起算法,数据结构在日常使用中碰到的几率更高,更有用。当然,比起种类繁多的算法来看,也是简单不少。
参考资料
- AVL树
- 红黑树
- SBT树
- Treap树
- Splay树
- 替罪羊树
- 线段树
- 树状数组
- ZKW线段树
- 归并树与划分树
- B树
- kd树
- 四叉树
- R树
- VSM模型和倒排索引和Lucue和用Golang写一个搜索引擎 (0x00)
- 小白详解Trie树和双数组Trie树
- AC自动机
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!