0 概述
kafka经验汇总,官网在这里
1 安装
Windows环境需要先安装好WSL和java,看这里,后续的代码都在WSL环境中执行。WSL环境对kafka的支持不太行,看这里
tar -xzf kafka_2.13-3.5.0.tgz
cd kafka_2.13-3.5.0解压源代码
1.1 ZooKeeper版本
bin/zookeeper-server-start.sh config/zookeeper.properties启动Zoo-keeper
bin/kafka-server-start.sh config/server.properties启动server
1.2 Raft版本
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties格式化log目录,仅需执行一次,/tmp/kraft-combined-logs里面同时存放着data和meta的数据
bin/kafka-server-start.sh config/kraft/server.properties启动server。Raft版本更容易管理,性能更好。
1.3 supervisor
[program:kafka]
command=sh bin/kafka-server-start.sh config/kraft/server.properties
directory=/mnt/c/Users/fish/Project/kafka_2.13-3.5.0
autostart=true
autorestart=false
stderr_logfile=/tmp/kafka_stderr.log
stdout_logfile=/tmp/kafka_stdout.log在/etc/supervisor/conf.d/kafka.conf加入以上的配置
sudo service supervisor start
sudo supervisorctl start kafka启动kafka服务
1.4 windows

在Windows中,首先要注意,kafka的所在目录不能太深,否则在CMD中容易报错。
log.dirs=C:/Users/fish/kafka-logs修改..properties目录,设置log.dirs的值
PS C:\Users\fish\kafka_2.13-3.5.0> .\bin\windows\kafka-storage.bat random-uuid
BKceidf7R-6JgDTAvhh7HQ
PS C:\Users\fish\kafka_2.13-3.5.0> .\bin\windows\kafka-storage.bat format -t BKceidf7R-6JgDTAvhh7HQ -c .\config\kraft\server.properties
Formatting C:/Users/fish/kafka-logs with metadata.version 3.5-IV2.格式化生成log目录
PS C:\Users\fish\kafka_2.13-3.5.0> .\bin\windows\kafka-server-start.bat .\config\kraft\server.properties
java.io.UncheckedIOException: Error while writing the Quorum status from the file C:\Users\fish\kafka-logs\__cluster_metadata-0\quorum-state
at org.apache.kafka.raft.FileBasedStateStore.writeElectionStateToFile(FileBasedStateStore.java:155)
at org.apache.kafka.raft.FileBasedStateStore.writeElectionState(FileBasedStateStore.java:128)
at org.apache.kafka.raft.QuorumState.transitionTo(QuorumState.java:477)
at org.apache.kafka.raft.QuorumState.initialize(QuorumState.java:212)
at org.apache.kafka.raft.KafkaRaftClient.initialize(KafkaRaftClient.java:370)
at kafka.raft.KafkaRaftManager.buildRaftClient(RaftManager.scala:248)
at kafka.raft.KafkaRaftManager.<init>(RaftManager.scala:174)
at kafka.server.SharedServer.start(SharedServer.scala:247)使用管理员,或者重启仍然不能解决问题。Windows启动kafka似乎是不行的
1.5 WSL2
windows下不能直接安装启动kafka,WSL在重启kafka的情况下有bug,所以最终的方案剩下WSL2和虚拟机了。
参考资料:
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://172.26.53.35:9092在config/kraft/server.properties中,修改listeners和advertised.listeners的配置,将它改为WSL2中虚拟机的地址
spring.kafka.bootstrap-servers = 172.26.53.35:9092java在连接kafka的时候,也需要连接WSL2中虚拟机的地址。
这个方案的唯一问题在于,WSL2的虚拟机的地址是动态变化的,这样会造成每次重启的话,kafka的IP地址,和Spring的配置文件也需要更改。
而在kafka中使用netsh portproxy似乎也是不行的,看这里
1.6 WSL2 + 域名
我们首先用这里自动将mykafka的域名写入到host文件中。
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://mykafka:9092然后修改config/kraft/server.properties配置
spring.kafka.bootstrap-servers = mykafka:9092最后修改java客户端的配置即可。就这样,我们能完成不变配置下连接本地kafka的方法了。
1.7 docker
使用docker来在Windows上安装是最简单的。我们使用的是,bitnami的kafa镜像
curl -sSL https://raw.githubusercontent.com/bitnami/containers/main/bitnami/kafka/docker-compose.yml > docker-compose.yml先下载docker-compose.yml
KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://[::1]:9092
KAFKA_CFG_LOG_RETENTATION_HOURS=2147483647
KAFKA_CFG_LOG_RETENTATION_BYTES=-1修改docker-compose.yml的配置,将KAFKA_CFG_ADVERTISED_LISTENERS的域名改为[::1]即可
docker-compose up -d启动kafka
spring.kafka.bootstrap-servers = [::1]:9092最后修改java客户端的配置即可。不需要做本地DNS的映射,可靠方便,而且默认的配置就是映射到本地的可持久化数据了。
# Copyright VMware, Inc.
# SPDX-License-Identifier: APACHE-2.0
version: "2"
services:
kafka:
image: docker.io/bitnami/kafka:3.5
restart: always
ports:
- "9092:9092"
volumes:
- 'C:\Users\fish\Util\kafka\data:/bitnami'
environment:
# KRaft settings
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://[::1]:9092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_CFG_LOG_RETENTATION_HOURS=2147483647
- KAFKA_CFG_LOG_RETENTATION_BYTES=-1一个docker_compose的例子
2 快速启动
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092创建一个叫”quickstart-events”的主题
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092描述该主题的情况
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092生产者,交互式向主题写入事件,输入Ctrl-C可以中止
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092消费者,从主题读取事件,输入Ctrl-C可以中止
3 常用操作
3.1 主题配置
bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name --partitions 20 --replication-factor 3topic的配置为:
- –replication-factor,复制因子,每个主题复制多少份。一般设置为2或者3。
- –partitions,分区。分区数量不能少于一个消费者组的消费数量,消费者比分区数量多出来的部分会闲置。
3.2 消费配置
bin/kafka-console-consumer.sh --bootstrap-server --topic quickstart-events --group newGroup localhost:9092消费者的配置为:
- –group,消费者组。不同消费者组可以消费同一个topic的相同消息,同一个消费者组的不同消费者处于负载均衡的状态。
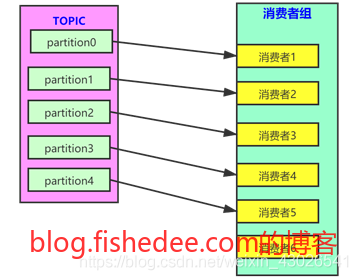
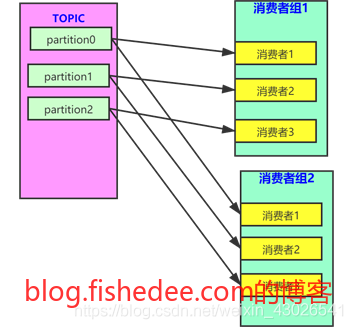
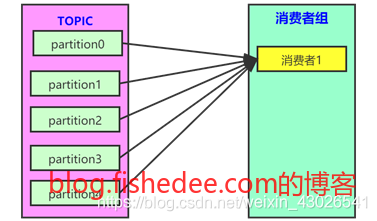
消费者组,消费者,分区之间的关系为:
- 当topic的分片数量小于处在同一消费者组内的消费者数量时,会使得消费者组的至少一个消费者消费不到数据,处于闲置。
- 当topic的分片数量多于同一消费者组内的消费者数量时,某些消费者会消费多个分区的数据。
- 当多个消费者组共同消费一个topic时,消费者组之间互不影响,同一条数据会同时被各个消费者组消费。
3.3 消费者组追踪
bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:9092
test-consumer-group查看有哪些消费者组
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
topic3 0 241019 395308 154289 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic2 1 520678 803288 282610 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic3 1 241018 398817 157799 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic1 0 854144 855809 1665 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic2 0 460537 803290 342753 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic3 2 243655 398812 155157 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4查看某个消费者组的详情。
3.4 调试信息
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-groups查看分组信息
./kafka-topics.sh --describe --topic trade_erp --bootstrap-server localhost:9092查看topic信息
4 可靠消息
4.1 消费端
参考资料:
- kafka-commit-strategies
- 容易被误会的 Kafka 消费者属性 enable.auto.commit
- Spring Kafka消费模式
- can-we-lose-kafka-message-in-case-of-poweroff *does-kafka-lose-message-if-consumer-holds-message-longer-then-auto-commit-interv
消费者commit的有两种方法:
- enable-auto-commit为true,由kafka服务器发起的commit方式
- spring.kafka.consumer.enable-auto-commit为false,由spring-kafka框架发起的客户端commit方式
4.1.1 服务器的commit方式
# 开启自动提交(按周期)已消费offset
spring.kafka.consumer.enable-auto-commit: true
# 自动提交已消费offset时间价格(配置enable-auto-commit=true时使用)
spring.kafka.consumer.auto-commit-interval: 1s这个方法相当好理解,为了提高commit的效率,kafka将会每隔一个固定时间批量commit一批offset的消息。
假设 enable.auto.commit 设置为 true,auto.commit.interval.ms 设置为 3000,试想一下会不会出现这样的问题:poll 方法返回了 500 条数据,需要 5 秒钟才能处理完,假设在第 4 秒的时候应用挂了,offset 是不是在第 3 秒的时候已经被自动提交了,从而导致第 4 秒之后的数据“丢失”了?
不会的!虽然 auto.commit.interval.ms 设置为 3000,但是检查时间间隔是否过了 3 秒是由 poll 方法去触发的,所以只要在记录还没处理完之前我们没有主动去调用 poll 方法,就算时间间隔到了,也不会去自动提交。
For at least once delivery, the consumer reads data from a partition, processes the message, and then commits the offset of the message it has processed. In this case, the consumer could crash between processing the message and committing the offset and when the consumer restarts it will process the message again. This leads to duplicate messages in downstream systems but no data loss.
可以看到,无论是Stackoverflow,还是官网,还是实际应用的测试中,使用周期性自动提交offset的方式都不会导致消息丢失的情况。因为offset提交的方式需要同时满足两个条件,周期时间到期,以及客户端调用了下一次的poll。由于客户端调用了下一次的poll,所以服务器可以安全的认为,上一次的poll的数据都已经全部处理完成了,所以能被ack。
如果在提交offset前,客户端在处理消息的过程中,崩溃了。服务器即使过了周期commit的时间,也不会进行commit操作,因为客户端没有调用下一次的poll接口。这个时候,崩溃的客户端重新上线了,它会拉到一个过期的旧offset,重新拉取消息,也就是说,这种情况只会导致消息重复,不会导致消息丢失。
4.1.2 客户端的commit方式
# 禁用自动提交(按周期)已消费offset
spring.kafka.consumer.enable-auto-commit: false
# listener类型为单条记录single类型(默认为single单条消费模式)
spring.kafka.listener.type: single/batch
# listener类型设置为batch的时候,每次最大拉取记录数
spring.kafka.consumer.max-poll-records=50
# offset提交模式为record
spring.kafka.listener.ack-mode: record/batch/time/count/count_time/manual/manual_immediate.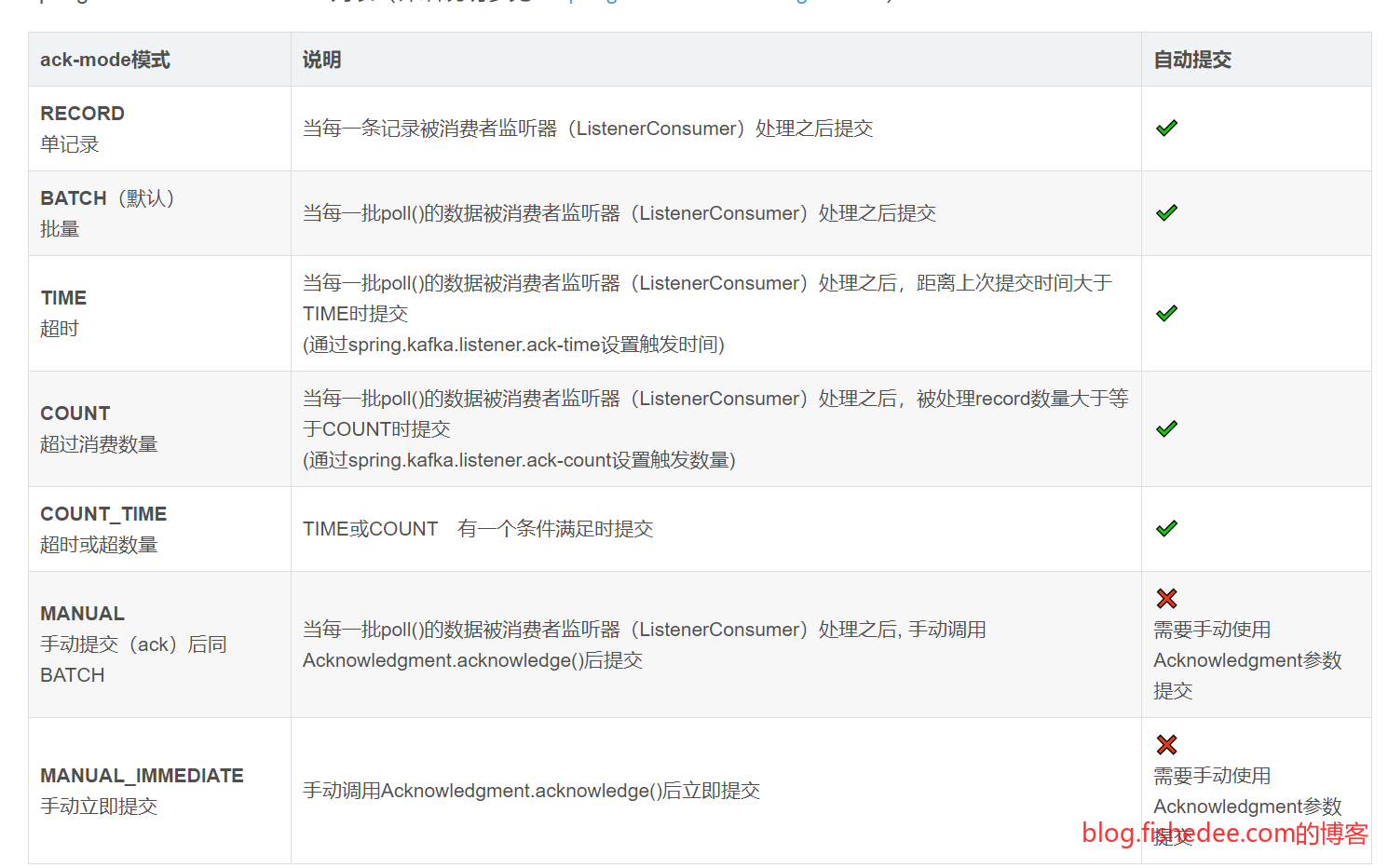
参考资料
使用客户端commit的场景是很少的,包括有:
- 重型消费消息场景,每个消息的处理都需要非常耗费资源,为了尽可能减少重复消息的数量,我们采取在客户端逐条ACK消息的方式。这样逐条ACK消息的吞吐量明显不怎么好,但是避免了大量重复消息的问题,最坏情况下每次宕机重启最多只会多消费1条消息。
- 异步消费消息场景,在用poll拉取消息以后,开启新的线程来消费消息,然后在该消息消费完毕之前,就进行下一次的poll操作。显然,由于消费消息和拉取消息不在一个线程中,自动的周期确认消息就容易导致消息丢失的情况。解决方法是使用MANUAL的方式,来确认消息。
4.2 发送端
参考资料:
4.2.1 ACK配置
由于消费端总是需要处理重复消息的问题,所以,发送端只需要处理发送可靠的问题就可以了,不需要处理消息重复发送的问题。因此,发送端也不需要去做事务消息的处理,放心地堆消息进去kafka就可以了,重复消息的问题是消费端解决的。
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 生产者请求超时时间
spring.kafka.producer.properties.request.timeout.ms=5000
# 重试次数
spring.kafka.producer.retries=0发送端的可靠性关键在于acks的配置,参数有:
- acks=1(默认):当且仅当leader收到消息返回commit确认信号后认为发送成功。如果 leader 宕机,则会丢失数据。producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果 follower 同步成功之前 leader 故障,那么就会丢失数据。
- acks=0:producer发出消息即完成发送,无需等待来自 broker 的确认。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- acks=-1(ALL):发送端需要等待 ISR 列表中所有列表都确认接收数据后才算一次发送完成,可靠性最高,延迟也较大。如果 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,producer 重新发送消息给新 leader 那么会造成数据重复。
Acks=all 就可以代表数据一定不会丢失了吗?当然不是,如果你的 Partition 只有一个副本,也就是一个 Leader,任何 Follower 都没有,因为 ISR 里就一个 Leader,它接收完消息后宕机,也会导致数据丢失。
所以说,这个 Acks=all,必须跟 ISR 列表里至少有 2 个以上的副本配合使用,起码是有一个 Leader 和一个 Follower 才可以
4.2.2 吞吐量和延迟
# 批量大小
# spring.kafka.producer.batch-size=16384
# 提交延时
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
spring.kafka.producer.properties.linger.ms=0producer发送的消息,不是立即发送的时候,是在客户端堆积了一定数量以后才执行发送的。客户端需要满足以下任意一个条件:
- 堆积的消息大小,大于batch-size
- 堆积的消息时间长度,大于linger.ms
显然,这是一个关于吞吐量和延迟取舍的配置,当batch-size和linger.ms越大的时候,吞吐量越大延迟越大。反之,吞吐量很小,延迟也很小。
4.3 Broker端
Broker端保证消息不丢失
- kafka是有限度的保证消息不丢失,这里的限度,是至少一台存储了你消息的的broker。
关注一个leader选举的问题
- kafka中有领导者副本(Leader Replica)和追随者副本(Follower Replica),而follower replica存在的唯一目的就是防止消息丢失,并不参与具体的业务逻辑的交互。只有leader 才参与服务,follower的作用就是充当leader的候补,平时的操作也只有信息同步。ISR也就是这组与leader保持同步的replica集合,我们要保证不丢消息,首先要保证ISR的存活(至少有一个备份存活),那存活的概念是什么呢,不仅需要机器正常,还需要跟上leader的消息进度,当达到一定程度的时候就会认为“非存活”状态。
Broker端的可靠性只需要配置好主题的–replication-factor就可以了。
5 服务器配置
5.1 listeners与advertised.listeners
看这里
两个参数的含义是:
- listeners,当省略域名的时候,表示绑定到所有网卡上。这个配置表达了当前kafka节点侦听的服务器地址和端口。
- advertised.listeners,是kafka作为多节点的时候,客户端如何寻址的问题。
分布式的寻址问题:
- 正常情况下,kafka的客户端可以随意连接任意一个kafka的节点,根据topic和分区,到Zookeeper上寻找对应topic和分区的Leader节点。客户端只能对Leader节点进行写操作,Fllow节点只能做读操作,不能做写操作。
- Zookeeper节点上记录了Leader节点的IP地址和端口,客户端拿到这个IP和端口直接寻址写入就可以了。
- 问题就在于,kafka与客户端可能在一个内网上,也可能不在一个内网上。当它们在一个内网上的话,Zookeeper记录的Leader节点上的内网IP。当它们不在一个内网上的话,Zookeeper记录的Leader节点就应该是外网IP。
- 因此,每个Kafka节点除了需要记录侦听的listener配置项以外,还需要一个advertised.listeners的配置,用来表示客户端寻址到当前节点的时候应该使用什么具体的IP和端口。
- advertised.listeners,不仅用于客户端寻址,还用于Brokers之间的寻址,也用于 Controller的寻址。
5.2 retention
看这里
log.retention.hours = 2147483647
log.retention.bytes = -1默认为7天的日志保留时间,如果设置为log.retention.ms=-1的时候,表示永久保留。以上是推荐的永久保留配置
6 Java配置
6.1 KafkaConsumer
public List<KafkaMessage> getLatestMessage(int messageCount){
Properties consumerProperties = new Properties();
consumerProperties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServers);
consumerProperties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProperties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
consumerProperties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"trade_tenant_admin."+this.localIP);
consumerProperties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"30");
KafkaConsumer<String, String> consumer = null;
try{
consumer = new KafkaConsumer<String, String>(consumerProperties);
//计算offset
TopicPartition partition = new TopicPartition(TenantEventPO.TOPIC, 0);
List<TopicPartition> partitions = Arrays.asList(partition);
Long beginOffset = consumer.beginningOffsets(partitions).get(partition);
Long endOffset = consumer.endOffsets(partitions).get(partition);
long startPosition = endOffset - messageCount;
if( startPosition <= beginOffset ){
startPosition = beginOffset;
}
//设置offset
consumer.assign(partitions);
consumer.seek(partition,startPosition);
//读取message
List<KafkaMessage> result = new ArrayList<>();
long maxPosition = 0;
while(maxPosition < endOffset){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(10));
if( records.isEmpty()){
break;
}
for(ConsumerRecord<String, String> record:records ){
String msg = record.value();
KafkaMessage kafkaMessage = new KafkaMessage()
.setCreateTime(new Date(record.timestamp()))
.setMsg(msg)
.setMsgHash(DigestUtils.md5DigestAsHex(msg.getBytes()))
.setId(record.offset());
result.add(kafkaMessage);
if( maxPosition < record.offset() +1 ){
maxPosition = record.offset()+1;
}
}
}
Collections.reverse(result);
return result;
}finally {
if( consumer != null ){
consumer.close();
}
}
}手动创建KafkaConsumer的方法。另外一种方法是使用consumer.subscribe(topic),这样不需要指定分区。
10 FAQ
10.1 WARN [AdminClient clientId=adminclient-1] Connection to node -1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://114.115.20.100:9092看这里
11.2 Commit cannot be completed
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member.
This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms,
which typically implies that the poll loop is spending too much time message processing.
You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.出现这个问题有几种原因:
- 消息的处理时间太长了,导致两个poll之间的间隔太大,触发了报错。解决方法是要么增大max.poll.interval.ms和session.timeout.ms,要么减少max.poll.records。
- 确实是有消费者增加或掉线了,造成rebalance的触发。这个常见于SpringBoot代码restart的过程中,旧进程的consumer还没下线,新进程consumer上线后,手动触发consumer.commitSync();导致的。这个时候,如果消费者的分区只有一个,那么新进程统一使用assign(topic),或者统一使用subscribe(topic),就能避免这个问题,尽量避免consumer两者混合使用。因为新进程使用assign(topic)的话,会把旧进程的consumer踢下线。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!