0 概述
《PostgresSQL修炼之道》读书笔记,PostgresSQL被称为最先进的开源数据库引擎,抽了时间看了一下。本读书笔记仅记录读书过程中对个人有意义的部分
1 简介
无
2 安装与配置
2.1 Linux安装
sudo apt-get install postgresql安装
export PATH=/usr/local/pgql/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/pgsql/lib:$LD_LIBRARY_PATH加入环境变量,~/.bashrc或者/etc/profile文件中
export PGDATA=/home/osdba/pgdata
initdb初始化数据目录
cd postgres-9.2.3/contrib
make
sudo make install安装contrib工具
2.2 CentOS8安装
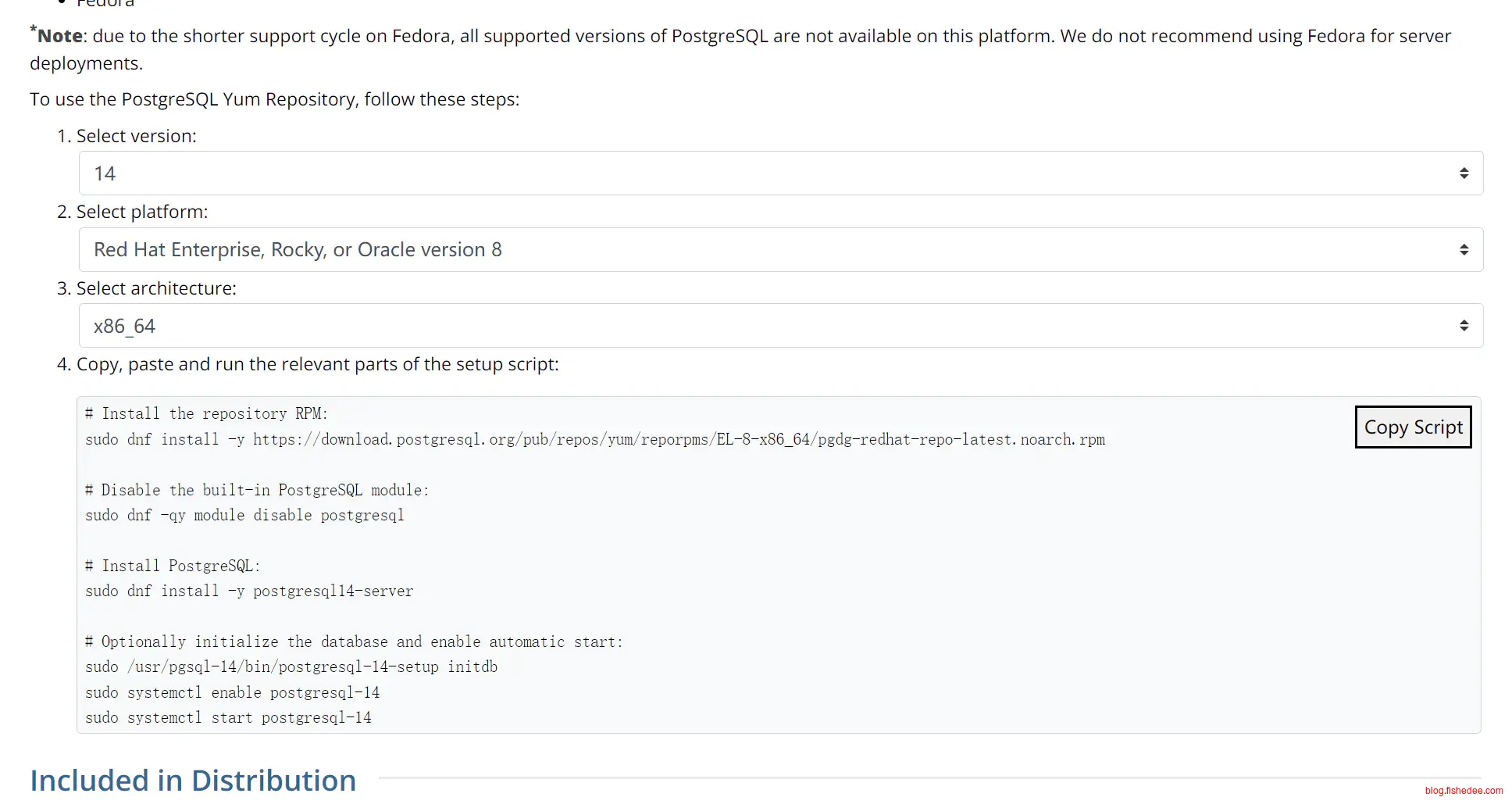
打开这里,输入以上平台,按照命令输入即可。注意的是,postgresql14是客户端,postgresql14-server是服务器端。
# Install the repository RPM:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# Disable the built-in PostgreSQL module:
sudo dnf -qy module disable postgresql
# Install PostgreSQL:
sudo dnf install -y postgresql14-server
# Optionally initialize the database and enable automatic start:
sudo /usr/pgsql-14/bin/postgresql-14-setup initdb
sudo systemctl enable postgresql-14
sudo systemctl start postgresql-14命令如上
2.3 Mac安装
进入postgresapp,根据提示安装。
export PATH=/Applications/Postgres.app/Contents/Versions/latest/bin:$PATH
export PGDATA=/Users/fish/Library/Application Support/Postgres/var-13加入环境变量,不需要初始化数据目录
brew install postgresql@14另外一个方法,就是用brew直接安装
安装完毕以后,目录在/opt/homebrew/share/postgresql@14/
2.4 启动与关闭
pg_ctl start -D $PGDATA
pg_ctl stop -D $PGDATA [-m smart|fast|immediate]启动与关闭postgres服务器
2.5 源码编译
2.5.1 编译
sudo apt-get install libreadline-dev zlib1g-dev安装依赖
$ tar zxf postgresql-X.Y.Z.tar.gz
$ cd postgresql-X.Y.Z
$ ./configure --prefix=/opt/pgsql-X.Y.Z
$ make
$ su
# make install
# exit到这里下载源代码,并执行以上代码进行编译,prefix是编译成功后的安装目录。注意,不要使用root用户安装
$ tar zxf pg_bigm-x.y-YYYYMMDD.tar.gz
$ cd pg_bigm-x.y-YYYYMMDD
$ make USE_PGXS=1 PG_CONFIG=/opt/pgsql-X.Y.Z/bin/pg_config
$ su
# make USE_PGXS=1 PG_CONFIG=/opt/pgsql-X.Y.Z/bin/pg_config install
# exit到这里下载bigm的源代码,并执行以上代码编译
PATH = $PATH:
PGDATA 创建好postgresql的path位置,以及PGDATA的位置。
2.5.2 手动启动
$ initdb -D $PGDATA --locale=C --encoding=UTF8
$ vi $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_bigm'
listen_addresses = '*'
$ vi $PGDATA/pg_hba.conf
host all all 0.0.0.0/0 trust
$ pg_ctl -D $PGDATA start配置postgresql.conf和pg_hba.conf,初始化启动数据库
psql -h localhost postgres
create role postgres with login superuser password '123';创建超级用户postgres,密码为123
2.5.3 Mac开机自启动
参考这里将postgresql在MacOS下设置为自启动。
#!/bin/sh
# PostgreSQL server start script (launched by org.postgresql.postgres.plist)
# edit these as needed:
# directory containing postgres executable:
PGBINDIR=/Users/fishedee/Util/postgresql/bin/
# data directory:
PGDATA=/Users/fishedee/Util/postgresql/data/
# file to receive postmaster's initial log messages:
PGLOGFILE="${PGDATA}/pgstart.log"
# (it's recommendable to enable the Postgres logging_collector feature
# so that PGLOGFILE doesn't grow without bound)
# set umask to ensure PGLOGFILE is not created world-readable
umask 077
# wait for networking to be up (else server may not bind to desired ports)
/usr/sbin/ipconfig waitall
# and launch the server
exec "$PGBINDIR"/postgres -D "$PGDATA" >>"$PGLOGFILE" 2>&1放入文件夹/usr/local/bin/postgres-wrapper.sh,并且加入执行权限
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>org.postgresql.postgres</string>
<key>ProgramArguments</key>
<array>
<string>/bin/sh</string>
<string>/usr/local/bin/postgres-wrapper.sh</string>
</array>
<key>UserName</key>
<string>fishedee</string>
<key>KeepAlive</key>
<true/>
</dict>
</plist>放入文件夹/Library/LaunchDaemons/org.postgres.postgres.plist
sudo launchctl load /Library/LaunchDaemons/org.postgresql.postgres.plist启动即可
2.5.4 Linux开机自启动
[Unit]
Description=PostgreSQL 14 database server
Documentation=man:postgres(1)
Documentation=http://www.postgresql.org/docs/14/static/
After=network.target
[Service]
Type=forking
User=fish
ExecStart=/home/fish/postgresql/bin/pg_ctl start -D /home/fish/postgresql/data -l /home/fish/postgresql/data/pg_start.log
ExecStop=/home/fish/postgresql/bin/pg_ctl stop -D /home/fish/postgresql/data
ExecReload=/home/fish/postgresql/bin/pg_ctl reload -D /home/fish/postgresql/data
TimeoutSec=300
[Install]
WantedBy=multi-user.target将启动脚本放入/etc/systemd/system/postgresql.service
sudo chmod 644 /etc/systemd/system/postgresql.service
sudo systemctl daemon-reload
sudo systemctl enable postgresql.service
sudo systemctl start postgresql.service启动即可
2.6 官方安装
# Import the repository signing key:
sudo apt install curl ca-certificates
sudo install -d /usr/share/postgresql-common/pgdg
sudo curl -o /usr/share/postgresql-common/pgdg/apt.postgresql.org.asc --fail https://www.postgresql.org/media/keys/ACCC4CF8.asc
# Create the repository configuration file:
. /etc/os-release
sudo sh -c "echo 'deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] https://apt.postgresql.org/pub/repos/apt $VERSION_CODENAME-pgdg main' > /etc/apt/sources.list.d/pgdg.list"
# Update the package lists:
sudo apt update
sudo apt install postgresql-18在这里可以看到ubuntu的官方安装方法,只要操作系统适配,就可以用apt-get直接安装了
sudo -u postgres psql -c "ALTER user postgres PASSWORD 'postgres';"安装完毕以后,用这个命令就能直接修改默认postgres密码
3 SQL语言入门
select * from student from no = 1 union select * from student_bak where no = 1;
select * from student from no = 1 union all select * from student_bak where no = 1;union 与 union all 的区别是,union会将结果集中相同的两条记录合并一条,也就是会去重。而union all不会去重
4 psql 工具的使用介绍
4.1 基础
用户在新建数据库时,默认是从模板数据库template1 克隆出来的。
psql -h 192.168.56.11 -p 5432 testdb postgres-h是IP地址,-p是端口,另外两个参数是数据库名,和用户名
| 命令 | 含义 |
|---|---|
| \c xxx | 切换数据库xxx |
| \l | 查看所有数据库 |
| \d [pattern] | 显示匹配关系的信息(表,视图,索引,和序列) |
| \d+ [pattern] | 显示比 |
| \df+ [pattern] | 显示函数 |
| \timing [on\off] | 打开或者关闭SQL已执行时间 |
| \dn | 列出schema |
| \db | 列出表空间 |
| \du | 列出所有角色或用户 |
| \x | 类似mysql中的 |
| \i | 运行外部的sql文件 |
Postgresql对分号很严格,\开头的命令不需要分号结束。其他指令如果没有分号会被看作语句未结束,如果看到分号才算是语句结束。
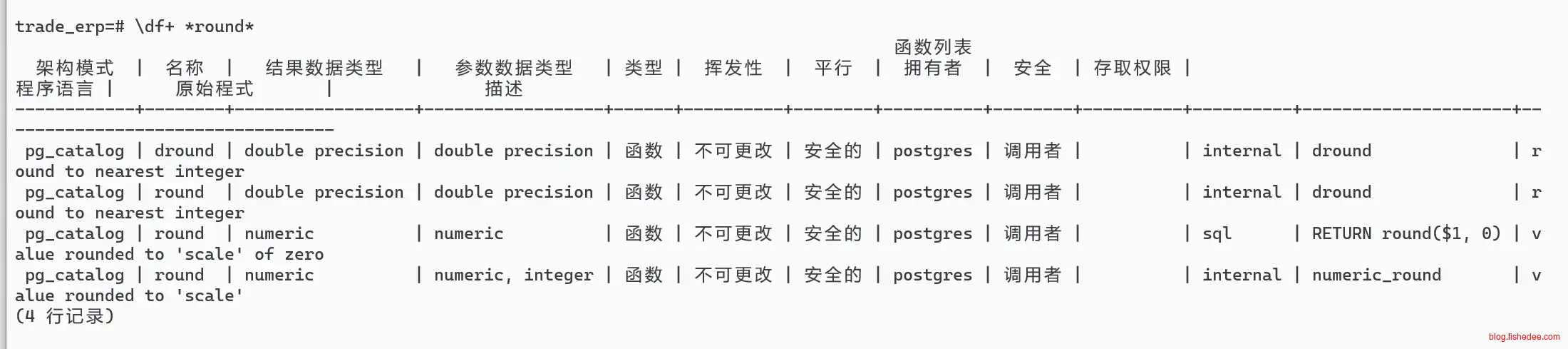
\df+ *round*查询函数
4.2 操作
alter table account add column initial_balance decimal(16,4) not null default '0';添加列
alter table account alter column balance type decimal(18,8);改列的类型
create index item_contact_alias_item_index on item_contact_alias(item_id) ;
alter table employee add constraint employee_number_unique unique(number) deferrable initially deferred ;添加索引和唯一性约束
5 数据类型
5.1 布尔类型
TRUE或者FALSE
5.2 数值类型
| 类型 | 含义 |
|---|---|
| smallint | 2字节整数 |
| int | 4字节整数 |
| bigint | 8字节整数 |
| decimal | 定点数 |
| real | 4字节浮点 |
| double precision | 8字节浮点数 |
| serial | 4字节,自增整数 |
| bigserial | 8字节,自增整数 |
- pg的int都是有符号的,没有无符号的整数
- decimal是不定长度的,最大可以为1000位精度的数字。decimal(18,8)的意思是,小数精度为8位,整数精度为18-8=10位,全精度为18位,所以数字最大不超过10^10.
- 序列serial与bigserial是最大的不同。它是单独的一个变量,可以跨数据表和跨字段使用,可以设置开始值,终止值,甚至步长
5.3 字符串类型
| 类型 | 含义 |
|---|---|
| varchar(n) | 变长,最大1GB |
| char(n) | 定长,不足补空白 |
| text | 变长,无长度限制 |
没有mysql乱七八糟的限制
5.4 二进制类型
| 类型 | 含义 |
|---|---|
| bytea | 二进制,无长度限制 |
select E'\\134'::bytea;注意,bytea是唯一,对于特别的字节,用两个反斜杠+3位八进制来表达
5.5 位串
| 类型 | 含义 |
|---|---|
| bit(n) | 定长,输入的长度必须与n完全相同,否则报错 |
| bit varying(n) | 变长 |
5.6 日期与时间
| 类型 | 含义 |
|---|---|
| timestamp | 日期和时间,8字节 |
| date | 日期,4字节 |
| time | 一日内时间,8字节 |
- pg的时间time和timestamp可以配置为带时间的信息
- time,timestamp都是用双精度来实现的,以2000-01-01午夜作为0值来参考,来表达时间,精度在毫秒级别都是准确的
- 2020-01-01 这个格式是最没有歧义的,避免使用/来表达时间
- CURRENT_TIME,CURRENT_TIMESTAMP,CURRENT_DATE,LOCALTIMESTAMP,now()这些函数都是使用事务开始时刻返回结果的,在同一个事务里面,他们的返回值总是相同的,看第78页的例子。
5.7 枚举
create type week as enum('Sun','Mon','Tues');
create table duty( person text, weekday week);
insert into duty values('张三','Sun');5.8 几何类型
这个可是pg的杀手级功能
| 类型 | 含义 |
|---|---|
| point | 点 |
| lseg | 线段,有限长度 |
| box | 矩形 |
| path | 闭合,或者开放路径 |
| polygon | 多边形 |
| circle | 圆 |
- []表示开放路径,()表示闭合路径。所以矩形和多边型不能用方括号符号
5.9 网络地址类型
| 类型 | 含义 |
|---|---|
| cidr | 网络IP地址,可选择性的掩码 |
| inet | 网络IP地址,必须带掩码 |
| mac | 以太网的mac地址 |
5.10 复合类型
create type person as (
name text,
age integer,
sex boolean
);
create table author(
id int,
person_info person,
book text,
)创建复合类型
insert into author values(1, '("张三",29,TRUE)','张三的自传');
insert into author values(2, ROW("张三",29,TRUE),'张三的自传');
select (person_info).name from author;
update author set person_info = ROW("张三",29,TRUE) where id = 1;
update author set person_info.age = (person_info).age+1 where id = 2;查询,插入和更新复合类型。
注意复合类型的输入解析为,首先sql词法分析器先吃掉外面的一层斜杠,然后里面复合类型解析器再吃掉一层斜杠
5.11 XML类型
无
5.12 JSON类型
postgresSql表达json有两种类型,json类型与jsonb类型,他们的区别为:
- jsonb使用二进制进行保存,json使用文本来保存
- jsonb在保存时会去掉多余的空格,去掉重复的key,重新排序key。而json会原样保存
- json可以直接创建索引,json只能使用函数索引
| 类型 | 含义 |
|---|---|
| string | text |
| number | decimal,注意没有NaN与infinity |
| boolean | boolean |
| null | (none) |
jsonb中的JSON类型与PostgresSQL类型的映射,注意,number不是用int,也不是用double,而是用decimal来保存,精度更高。
| 操作符 | 含义 | 例子 |
|---|---|---|
| -> | 根据key取数组或者object对应的value | ‘{“a”:1,“b”:2}’::json->‘a’ |
| ->> | 根据key取数组或者object对应的value,返回值为文本类型 | ‘{“a”:1,“b”:2}’::json->>‘a’ |
| #> | 根据key[]取数组或者object对应的value | ‘{“a”:{“b”:{“c:3”}}}’::json#>‘{a,b}’ |
| #>> | 根据key[]取数组或者object对应的value,返回值为文本类型 | ‘{“a”:{“b”:{“c:3”}}}’::json#>>‘{a,b}’ |
这些操作符是取value的操作
| 操作符 | 含义 | 例子 |
|---|---|---|
| @> | 包含,包含数组的一部分,或者包含一个object的key与value | jsonb ‘[1,2,3]’ @> jsonb ‘[2,3]’ ; jsonb ‘{“a”:1,“b”:2}’ @> jsonb ‘{“a”:1}’ |
| ? | 包含单个key,数组包含key,或者object的key就是key | jsonb ‘[“1”,“2”,“3”]’ ? ‘2’ ; jsonb ‘{“a”:1,“b”:2}’ @> ‘b’ |
| ?|包含key数组,任一存在 | ||
| ?& | 包含key数组,同时存在 |
这些操作符都是json查找的一部分。@>同时查找key与value,而?只查找key
create index idx_name on table_name using gin(index_col [jsonb_ops])
create index idx_name on table_name using gin(index_col jsonb_path_ops) jsonb类型一般建gin索引,建的时候可以选择jsonb_ops(默认)或者jsonb_path_ops两种方式。他们的区别是:
- jsonb_ops,对于每个key与每个value都单独建一个倒排索引,而jsonb_path_ops则只对value建倒排索引。
- jsonb_ops支持@>与?的索引查找,而jsonb_path_ops只能支持@>的索引查找。
- jsonb_ops的索引项明显要大得多,插入时需要较慢,但是查找时能更快一点,因为可以同时匹配key与value的来获取两个倒排来筛选数据。而json_path_ops只能匹配value来获取倒排链,然后在原始行中逐一筛选数据
create index idx_name on table_name using btree(index_col->'name')另外一种就是使用函数索引,对index_col取特定的key得到的value值来建立索引。这种方法,索引更小,但是要提前考虑好查询时要用到哪些字段。另外,支持btree或者gin,甚至gist索引的方式。
5.13 Range类型
//原始的没有RANGE类型时需要建立的表
create table ipdb1(
ip_begin inet,
ip_end inet,
area text,
sp text
);
//有RANGE类型时能以以下的方式建表
create type inetrange as RANGE(subtype = inet)
create table ipdb2(
ip_range inetrange,
area text,
sp text
);
//从ipdb1中倒入数据到ipdb2中
insert into ipdb2 select ('['|| ip_begin || ',' || ip_end || ']')::inetrange,area,sp from ipdb1;RANGE类型的出现,不仅是为了将含义相同的两个字段合成到了一个字段上,而且是可以建立gist索引来实现双字段范围查询。
create index idx1 on ipdb1(ip_begin);
create index idx2 on ipdb2(ip_end);
select * from ipdb1 where ip_begin <= '115.195.180.105'::inet and '115.195.180.105'::inet <= 'end';例如我们要查询’115.195.180.105’匹配哪个area,就需要用以上的查询。即使加上了索引也快不了哪里去,因为ip_begin与ip_end是建立两个不同的索引。进一步地,就算是建立了复合字段的btree索引也没有用。
create index idx3 on ipdb2 using gist(ip_range);
select * from ipdb2 where ip_range @> '115.195.180.105'::inet建立gist索引以后,gist使用R树的方式建立了空间索引,能大幅加快以上查找的速度
select * from ipdb2 where ip_range && '[115.195.180.105,115.195.180.170]'::inetrange甚至在建立gist索引后,可以查找到某个ip范围段匹配了哪些area
create table ipdb2(
ip_range inetrange,
area text,
sp text,
exclude using gist(ip_range with &&)
);你可以将area之间的ip范围段不能互相重叠作为约束,写到表定义里面。这样插入的时候,就不需要先select后插入了,避免了事务操作。
gist索引可以加速=,&&,@>,<<,&<这类的操作符查找操作
5.14 数组类型
create table testtab04(
id int,
col1 int[],
col2 int[10],
col3 text[][],
col4 text[]
);pg支持数组类型,同时,定义数组类型的数字,与维度,都是没有意义的。col1与col2是一样的类型,col3与col4也是一样的类型。
create table testtab05(
id int,
col1 int[],
);
insert into testtab05 values(1,'{1,2,3}');
insert into testtab05 values(1,ARRAY[1,2,3]);插入时就是单引号和大括号来表达的
//获取指定下标的元素
select id,col1[1] from testtab05;
//获取一个切片的元素
select id,col1[1:2] from testtab05;
//当col1是个二维数组时,1:1代表获取第一行的所有元素
select id,col1[1:1] from testtab05;
//以下两个sql等效
select id,col1[3][1:2] from testtab05;
select id,col1[1:3][1:2] from testtab05;postgresSQL的下标默认是从1开始的,而且支持切片的操作
update testtab09 set col1[2][1] = 1000 where id = 1;支持直接修改某个元素,但不能修改整个切片
ARRAY[1,2,3] @> ARRAY[1,2]
ARRAY[[1,2,3]] @> ARRAY[1,2]执行@>与&&操作时,与元素的排序与维度是没有关系的
5.15 伪类型
函数的入参与出参用的,any,anyelement,anyarray,void等等
5.16 LC_COLLATE和LC_CTYPE
参考资料
5.16.1 作用
- 字符串比较和排序: LC_COLLATE 的值会影响字符串的比较和排序方式。不同的语言和地区有不同的字符排序规则,这在多语言环境中尤为重要。
- 大小写转换: 涉及到大小写的转换,如字符串的大写转小写或小写转大写,也受到 LC_CTYPE 的影响。
- 字符分类和字符集: LC_CTYPE 可以指定字符的分类,例如,哪些字符是字母、数字等。这对于一些字符串处理操作是重要的,尤其是在需要考虑不同语言的情况下。
例如:
- 当LC_COLLATE为”C”的时候,‘黑’ > ‘紫’,按照Unicode编码来排序
- 当LC_COLLATE为”zh_CN.utf8”的时候,‘紫’ > ‘黑’, 按照拼音来排序
- 当LC_CTYPE为”C”的时候,“全角a”是不能转换为英文字母A, uppercase
- 当LC_CTYPE为”zh_CN.utf8”的时候,“全角a”是可以转换为英文字母A, uppercase
5.16.2 数据库级别
LC_COLLATE可以配置在三个地方
- 数据库
- 表
- 本地Sql
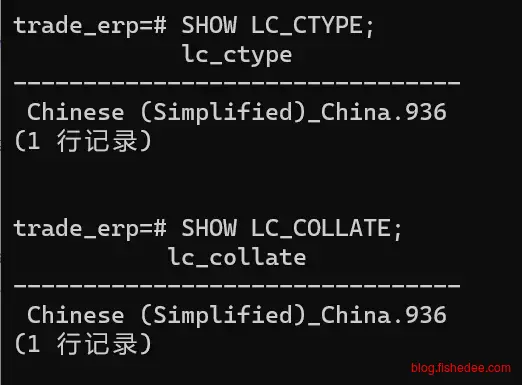
SHOW LC_CTYPE;
show LC_COLLATE;数据库级别的查看LC_COLLATE和LC_CTYPE
5.16.3 表级别
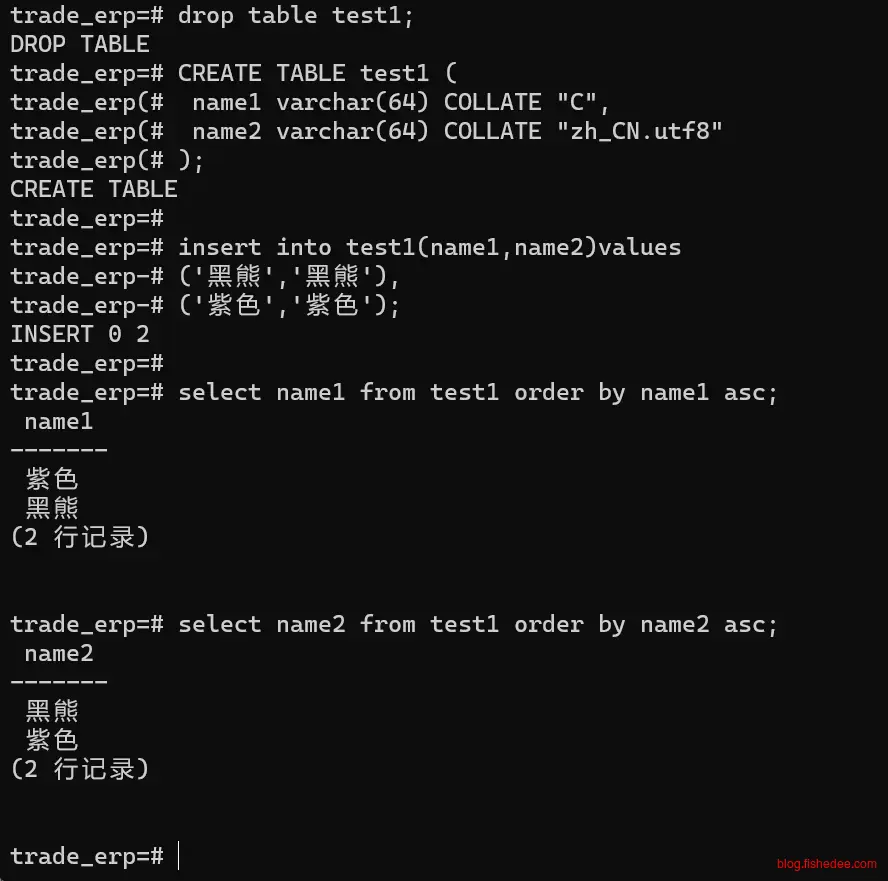
CREATE TABLE test1 (
name1 varchar(64) COLLATE "C",
name2 varchar(64) COLLATE "zh_CN.utf8"
);
insert into test1(name1,name2)values
('黑熊','黑熊'),
('紫色','紫色');
select name1 from test1 order by name1 asc;
select name2 from test1 order by name2 asc;字段级别的COLLATE影响了排序规则,C是按照Unicode编码排序,zh_CN.utf8是按照拼音排序
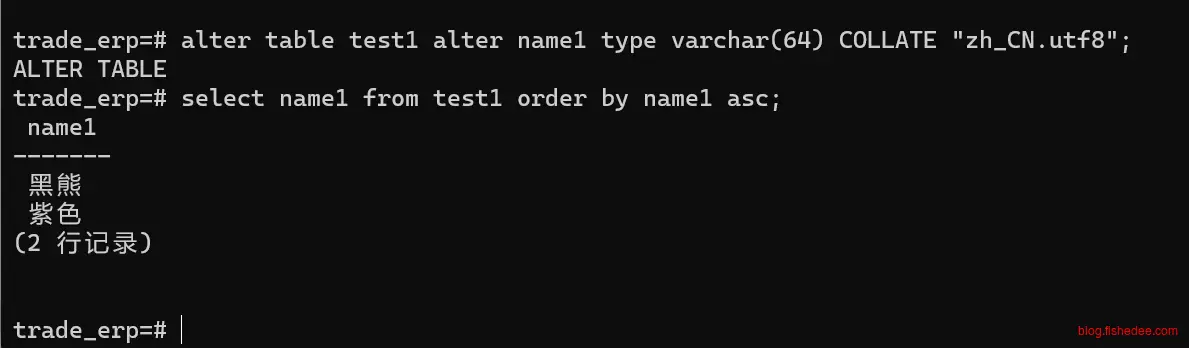
alter table test1 alter name1 type varchar(64) COLLATE "zh_CN.utf8";我们也可以修改具体字段的排序规则,这个修改列collate时,会导致rewrite table,大表请谨慎操作。
5.16.4 SQL级别
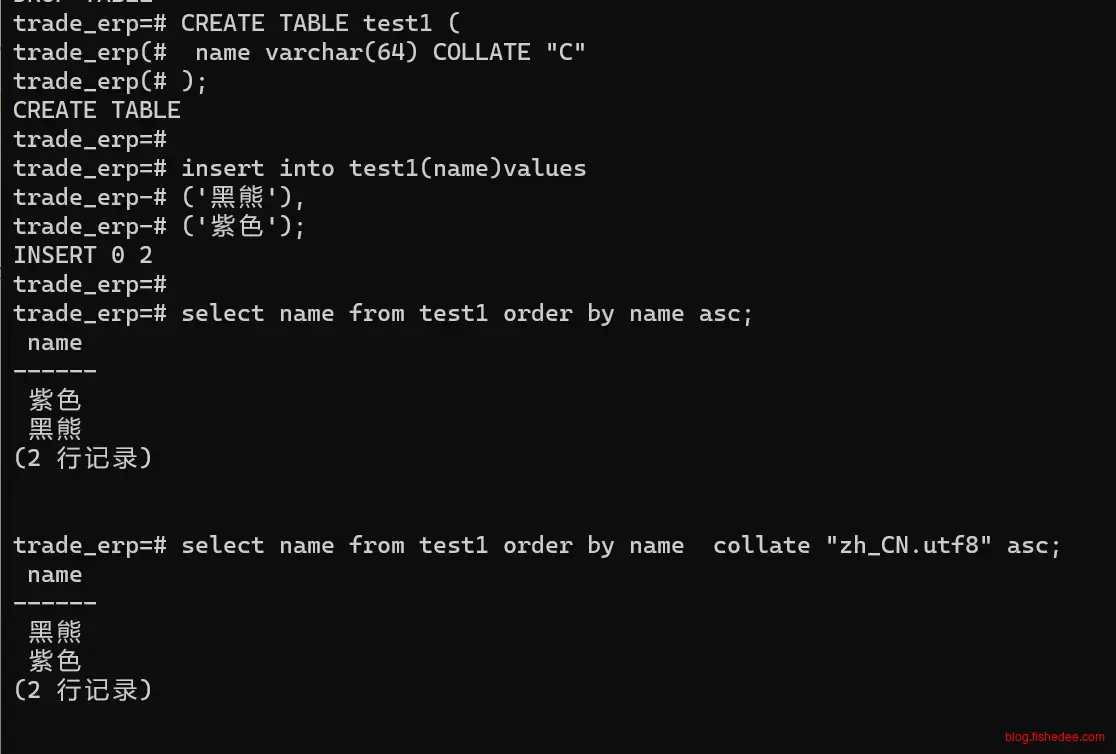
CREATE TABLE test1 (
name varchar(64) COLLATE "C"
);
insert into test1(name)values
('黑熊'),
('紫色');
select name from test1 order by name asc;
select name from test1 order by name collate "zh_CN.utf8" asc;我们也可以在order by的时候指定排序规则。当order by的排序规则和字段的排序规则不同的时候,原有字段的索引就会失效,这个时候,需要创建特定排序规则的.
create index name_zh_cn on test1( name collate "zh_CN.utf8");特定排序规则下的索引
5.16.5 查看现有的排序规则
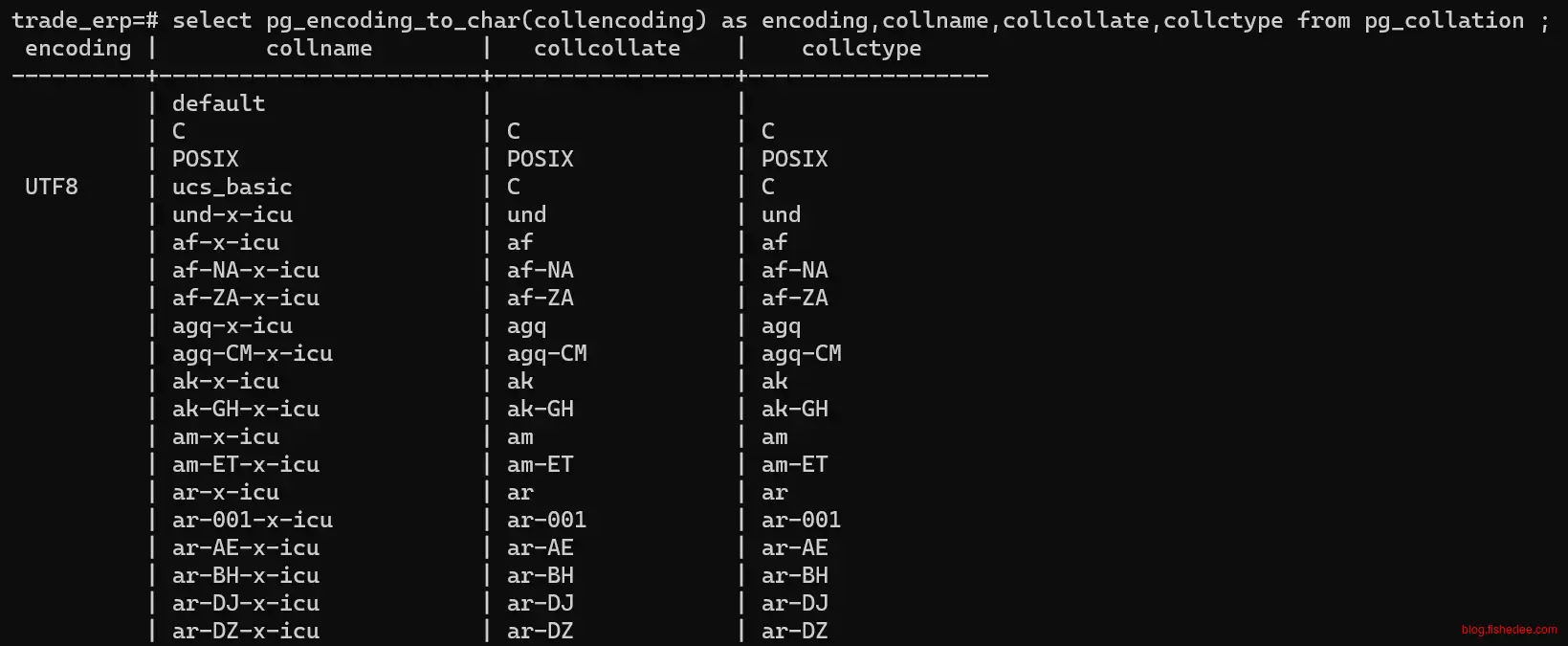
select pg_encoding_to_char(collencoding) as encoding,collname,collcollate,collctype from pg_collation ;要点1:
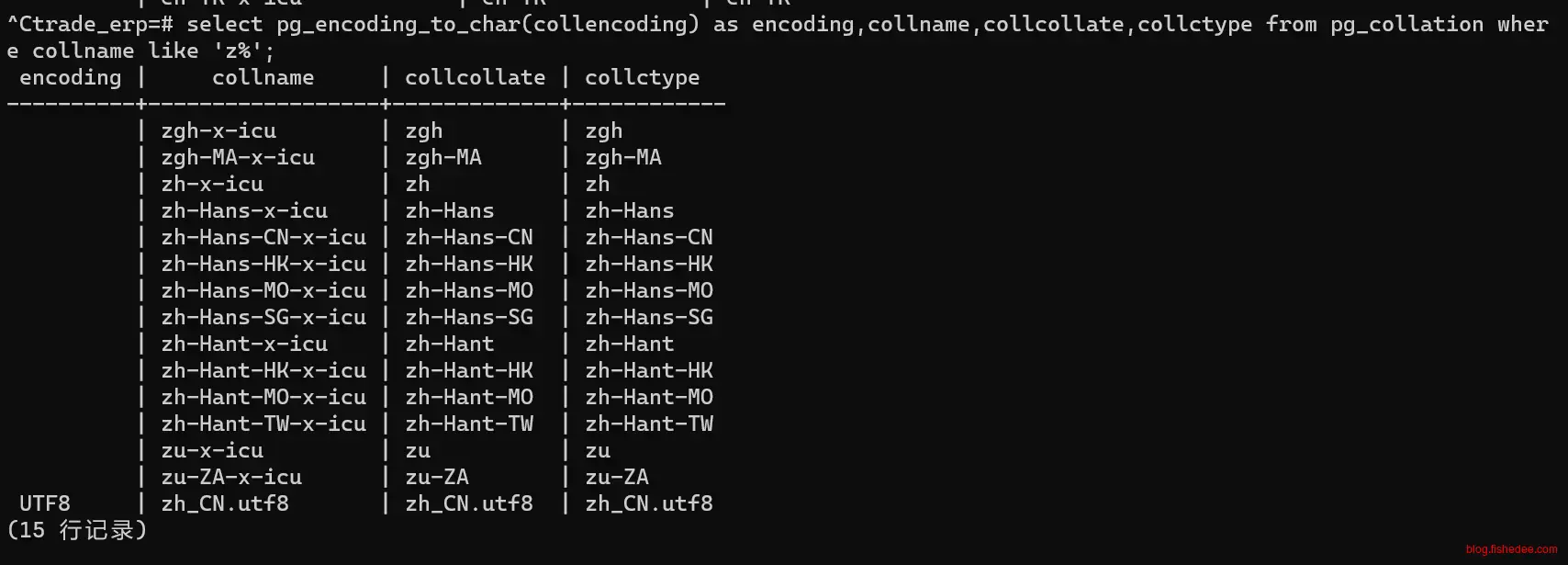
collname,就是我们平时需要填入字段collate的名称,不是用collcollate字段。
例如
我们只能填写select name from test1 order by name collate "zh-x-icu" asc;
不能填写select name from test1 order by name collate "zu" asc;要点2:
- 在Windows系统中,默认是没有zh_CN.utf8的排序规则,只有zh-x-icu的排序规则。
- 在Linux系统中,默认是有zh_CN.utf8的排序规则
5.16.6 添加新的排序规则
CREATE COLLATION name (
[ LOCALE = locale, ]
[ LC_COLLATE = lc_collate, ]
[ LC_CTYPE = lc_ctype ]
)
DROP COLLATION [ IF EXISTS ] name [ CASCADE | RESTRICT ]创建和删除排序规则的语法结构,LOCALE参数是一种设置LC_COLLATE 和LC_CTYPE的快捷方式。如果你指定它,你就不能指定另外的两个参数。
CREATE COLLATION "zh_CN.utf8" (
LC_COLLATE = 'zh_CN.utf8',
LC_CTYPE = 'zh_CN.utf8'
);
CREATE COLLATION pg_catalog."zh_CN.utf8" (
LC_COLLATE = 'zh_CN.utf8',
LC_CTYPE = 'zh_CN.utf8'
);
CREATE COLLATION pg_catalog."zh_CN.utf8" (
LOCALE = 'zh_CN.utf8',
);以上方式都是创建了新的排序规则,这三条SQL都是等价的。排序规则名称为zh_CN.utf8,LC_COLLATE使用操作系统内置的’zh_CN.utf8’,LC_CTYPE使用操作系统内置的’zh_CN.utf8’
#!/bin/sh
INIT_WINDOWS_SQL="CREATE COLLATION pg_catalog.\"zh_CN.utf8\" (LC_COLLATE = 'zh_CN.utf8',LC_CTYPE = 'zh_CN.utf8');"
PGPASSWORD=123 psql -Upostgres -c "${INIT_SCHEMA_SQL}" database 这是一个重要的Windows初始化Postgresql脚本,以保证Windows和Linux下都能使用相同的排序规则zh_CN.utf8,而不需要额外区分
6 逻辑结构管理
6.1 数据库
create database name [[with] option [...]]创建数据库,pg中的数据库与mysql的数据库是不同的。pg中的数据库是客户端连接后就不能改变的,也不能跨多个数据库进行join或者事务操作。pg中的数据库可以看成就是一个单机下的不同实例,而mysql中的数据库总是只有一个命名空间而已。
alter database testdb01 connection limit 10;
alter database testdb02 rename to mydb1;
alter database testdb03 tablespace 'xxxx';
drop database testdb01;可以设置数据库的连接数,表空间(不同的物理位置),名字等信息
6.2 模式
create schema name [AUTHORIZATION username];
drop schema name;创建一个模式,模式就是相当于一个命名空间。默认用户使用的就是public空间。表和索引等对象总是在某个一个schema下面的。
set search_path to name 设置当前默认的Schema
ALTER SCHEMA name1 RENAME TO name2; schema的改名
select distinct(schemaname) from pg_tables;查看当前数据库所有的schema
6.3 表
create table table_name(
col1 data_type1,
col2 data_type2,
);创建一个表
create table table_name2(like table_name);可以以某个表作为模板创建一个新表
6.3.1 存储属性
alter table blog alter content set storage external| 名称 | 含义 |
|---|---|
| PLAIN | 避免压缩或者行外存储 |
| EXTENDED | 允许压缩和行外存储 |
| EXTENAL | 只允许行外存储,不允许压缩 |
| MAIN | 只允许压缩,不允许行外存储 |
pg中的块大小固定为8KB,不允许一个行跨越多个块存储。它的方法就是建立TOAST表,将原来的字段只保存一个指针,然后将实际内容存储在一个TOAST表中。TOAST表有一个唯一标志ID,称为oid。行外存储的字段,会保存以下内容
行字段长度+TOAST表的oid+chunk_id+逻辑长度+实际长度另外,表上有fillfactor和toast.fillfactor的配置,用来指示每个数据块填满多少以后,就不再使用了,余留的位置给与更新数据和删除数据使用。因为pg中使用MVCC架构,删除和修改数据都实际上就是新添加数据,所以更新数据频繁时,最好时能在原来的数据块继续添加行,而不是在新的数据块上添加行,从而避免重建索引的问题。对于更新频繁的表,这个应该配置为40%左右。
6.3.2 临时表
//会话级别的临时表
create temporary table tmp_t1(
id int primary key,
note text,
);
//事务级别的临时表
create temporary table tmp_t1(
id int primary key,
note text,
)on commit delete rows;临时表实际上是在一个临时的schema上创建的表
6.3.3 默认值
//会话级别的临时表
create temporary table tmp_t1(
id int default 15,
id2 int default nextval('id2_serial');
note timestamp default now(),
);pg可以用函数表达式作为默认值,但是不支持更新时的自动用默认值来填充,这个要用触发器来实现
6.3.4 约束
create table books(
book_no integer not null,
price numeric check( price > 0 ),
discounted_price numeric check( discounted_price > 0 ),
check(price > discounted_priced)
);6.3.5 表继承
create table persons(
name text,
age int,
sex boolean
);
create table students(
class_no int
)INHERITS(persons);表继承以后,不仅会继承字段,还会将原始数据都插入到父表里面
//查询所有的persons,包括派生表插入的数据
select * from persons;
//查询基表自身的persons
select * from only persons;6.3.6 表分区
create table sales_detail(
product_id int not null,
price numeric(12,2),
sale_date date not null,
buyer varchar(40),
);
create table sales_detail_y2014m01(
check(sale_date >= DATE '2014-01-01' and sale_date < DATE '2014-02-01')
)INHERITS(sales_detail);
create table sales_detail_y2014m02(
check(sale_date >= DATE '2014-02-01' and sale_date < DATE '2014-03-01')
)INHERITS(sales_detail);分区是通过继承来实现的,这种方案不是很漂亮。对表插入,更新,删除数据是通过触发器来间接实现的,或者通过有“查询改写”的规则来实现
set constarint_exclusion = partition;
select count(*) from sales_detail where sale_date >= DATE '2014-01-01' and sale_date < DATE '2014-02-01';pg在查询的时候,打开了constarint_exclusion开关以后,能自动匹配到指定的分区表中执行,避免对所有的分区表进行查询。
6.4 触发器
create or replace function student_delete_trigger()
return trigger as $$
BEGIN
delete from score where student_no = OLD.student_no;
return OLD;
END;
$$
LANGUAGE plpgsql;
create trigger delete_student_trigger after delete on student for each row execute procedure student_delete_trigger(); 行级触发器和语句触发器的区别是:
- 语句触发器总是会触发,即使修改和删除的行数为0。行级触发器会根据,修改和删除的受影响行数来执行。
- 语句触发器总是会触发1次,行级触发器会触发0次或多次。无论行级触发器是否带有each,它总是根据受影响的行数来决定触发次数。
BEFORE与AFTER触发器就比较直观,就是原始sql执行前后来运行。而INSTEAD OF触发器则只有视图可以用,因为视图不能直接更新的,它是通过改写sql来实现可更新性的视图,所以是没有原始sql执行的场景,只有替换原始sql执行的场景。
6.5 事件触发器
一个系统事件的触发器
6.6 表空间
create dataspace tbs_data location '/data/pgdata';
alter database db01 set tablespace tbs_data;
alter table test_01 set tablespace tbs_data;表空间是指不同的存储目录或不同的文件系统,可以设置数据库,表,索引各自使用不同的表空间
6.7 视图
create table users(
id int,
user_name varchar(40),
password varchar(256),
user_email text
);
create view vm_users as select id,user_name,user_email from users;就是创建视图
6.8 索引
6.8.1 B-Tree
适合等值和范围查询
6.8.2 Hash索引
只能处理简单的等值查询
6.8.3 Gist索引
可以处理@>,&&与<<等操作,它的本质是R树,它的特点是:
- 中间节点不存放数据,存放的是数据的归纳结构。只有叶子节点才存放数据。例如,二维点集的归纳是矩形,一维点集的归纳是线段。
- 中间节点之间的结构可能处于重叠的状态,不是B树那种总是互斥的状态。
- 当中间节点上满溢出时,采用启发式结构分裂成两个节点。分裂算法有很多,一个\(O(n^2)\)的方法为,先取出两个距离最远的两个点,然后把它们作为两个点集的中信,然后将其他节点逐个选择加入到其中一个点集中,选择的方法为,加入后点集的扩大面积最小。
- 当中间节点下空溢出时,采用启发式结构合并成两个节点。合并算法为,将该唯一的节点逐个选择加入其中一个兄弟点集中,选择的方法为,加入后点集的扩大面积最小。
可以看出,R树的合并和分裂算法是最为重要的,决定了树是否平衡的关键。与B树的相同点是,每行只有一个索引项。不会出现像gin索引的,多个索引项指向一个行的情况。
Gist索引可以加速的场景为:
- 空间搜索,指定范围内的点,重叠的线段
- 数组搜索,将数组的每个元素看成是一个点,然后归纳为一个线段
- 全文搜索,将全文分割为分词的数组,然后用数组搜索来实现
6.8.4 SP-Gist索引
SP-Gist的索引与Gist索引类似,唯一的不同是,使用值域来划分树,而不是按照内容自身来划分树。
6.8.5 GIN索引
GIN索引就是倒排索引,将一个字段的内容拆分为多个索引项,然后每个索引项都指向到这一个行中。而且,倒排链中的posting list都是一个bitmap的,非常方便地做and与or等的二进制操作。
Gin索引可以加速的场景为:
- 数组搜索,将每个元素建立一个倒排链
- 全文搜索,将全文分割为分词的数组,然后每个分词建立一个倒排链,但是美中不足的是,posting list只记录了行的位置,没有记录行中字段出现的index。所以,gin索引做倒排索引时总是需要回到原始行中进行recheck操作。这个问题在新的extension,RUM索引中很好地解决了。
6.9 权限操作
GRANT some_privileges on database_object_type object_name to role_name;
GRANT select on ALL TABLES in SCHEMA public TO user1;6.10 事务
6.10.1 ACID
关系数据库中的事务需要满足以下的四个特性:
| 特性 | 含义 | 方法 | 解决 |
|---|---|---|---|
| A原子性 | 事务内部的多个事件要么全部执行,要么全部不执行,如果出现异常或者调电,会自动回滚全部中途修改的操作 | 强调的是写的原子性,不会出现写的中间状态 | 记录执行流程,异常时自动进行回滚事务 |
| C一致性 | 事务完成后,其他事务看到的是事务前或者事务后的数据,不会看到事务中间的结果 | 强调的是读的原子性,不会出现读的中间状态。 | 每一行都有一个事务ID,代表版本号,读取时都会检查该行是已提交的,是已回滚的,还是在中间状态的 |
| I隔离性 | 事务在并发情况下,保证自己读取的相关行不会被其他事务修改或者删除了 | 强调的是并发控制 | 悲观锁,通过表锁,行锁甚至字段锁的方式来协调并发。乐观锁,通过版本号来协调并发 |
| D持久性 | 事务完成之后,必须是持久化的,即使重启或掉电依然保持一致 | 强调的是磁盘落地安全性 | 每个事务提交以后,数据块可以不落地,但是相关数据块的修改信息必须落地到WAL日志上 |
begin;
insert into testtab01 values(1);
create table testtab02(
id int,
name text,
);
commit;pg支持DDL操作也放在单个事务里面,随时可以回滚
6.10.2 MVCC
pg中使用MVCC来实现一致性。每个事务(包括手动事务或者自动事务)在执行前都有一个事务ID1,然后每一行上面都有两个事务ID,分别是插入事务ID和删除事务ID,代表哪个事务对这行修改了。
- 添加行时,行上面记录该行的插入事务ID1。
- 删除行时,并没有物理删除这个行,而是在这个行上面标记已经删除了,删除事务为当前事务ID1。
- 修改行时,并没有物理修改这个行,而是标记原行已经删除了,删除事务为当前事务ID1,然后添加新行,新行的插入事务为当前事务ID1
事务执行流程为:
- 事务开始时,系统分配它一个事务ID2,并且系统记录该事务ID2处于中间状态。
- 事务执行时,不断地对行进行标记事务ID2。
- 事务结束后,系统根据commit或者rollback命令,来设置该事务ID2为已提交状态,还是已回滚状态。
然后其他事务在进行查询时,首先它先向系统获取最新的事务ID3。然后在获取行的时候,要检查两个信息:
- 该行是否已经插入了。检查该行的插入事务ID4小于ID3,并且该行的插入事务ID2是已提交的。
- 该行是否已经删除了。检查该行的插入事务ID4小于ID3,并且该行的插入事务ID2是已提交的。
- 该行对于当前最新事务ID1是否可见,就是要满足两个条件,该行已经插入并且未被删除。
在MVCC的控制下,任何行都是一旦插入就不会被物理删除或者修改的,这不仅保证了事务不会读取到中间状态,而且也让读与写能并发地进行!从语义来看,MVCC的读是总是一种快照读,跟当前写是没有关系的。
6.10.3 事务隔离级别
对于隔离性,有四个不同的隔离级别
| 隔离性 | 翻译 | 含义 |
|---|---|---|
| READ UNCOMMITTED | 读未提交 | 可能会读到未提交的数据,这会破坏一致性的约定 |
| READ COMMITTED | 读已提交 | 总是读最新版本的快照,但是会产生前后读数据不一致的问题 |
| REPEATABLE READ | 重复读 | 总是读一个版本的快照,但是会产生数据过期的问题 |
| SERIALIZABLE | 串行化 | 读最新的快照,而且保证这个版本是不可被其他事务修改。也就是快照读总是等同于当前读 |
pg中默认的隔离级别为,读已提交。而它能支持读已提交,重复读,串行化的三个隔离级别。
不同的隔离级别下会有不同的问题。很显然,串行化中快照读总是等同于当前读是最可靠的,开发者也不需要再额外关心并发问题的。但是,这样做会导致并发量很低。而当我们处于重复读,和读已提交的级别时,当前读就不再总是等于快照读了,每个隔离级别会各自选择了对快照读和当前读的优先权衡。
例如,读已提交,就是总是取出最新的快照读,事务的所有读操作都是及时性地向数据库获取最新的快照,保证读出来的数据是最新提交的,不过时的,但是这样可能会导致之前计算的结果已经失效了,这就是“不可重复读”的问题。重复读,就是只取出一次快照读,事务的所有读操作都是在这个唯一的快照上读出来的,即使这些数据后来已经改动了,依然只读取事务开始时刻的快照数据,但是这样可能会导致事务进行到一半时发现结果已经被其他事务已经修改了,快照读的数据已经失效了,这就是“幻读”的问题。无论是不可重复读,还是幻读的问题,他们的根源依然在于,快照读与当前读不一致造成的。
| 隔离问题 | 含义 | 隔离级别 |
|---|---|---|
| 脏读 | 读取到了另一个未提交事务写入的数据 | 只在“读未提交”级别会出现,但是PG中没有读未提交级别 |
| 不可重复读 | 同一个事务中,前后两次同一个命令读取的数据不一致,因为总是读取最新的数据快照。这在报表输出,和并发执行读取并修改操作时是不可饶恕的 | 只在“读已提交”和“读未提交”的级别中出现 |
| 幻读 | 同一个事务中,前后两次同一个命令读取的数据总是一致的,但是不保证这些数据是最新的,他们可能被其他事务已经修改了 | 在“重复读”,“读已提交”和“读未提交”的级别中出现 |
特别要注意的是,无论是读已提交,还是可重复读级别,都是不会产生脏读问题,也就是不会读到未提交事务的数据。但是,这只是对于其他事务的未提交的数据是无法看到的。对于自己事务未提交的事务是需要被看到的。而且在自己事务的不同位置所能看到的数据快照是不同的。所以,在不同事务的不同位置,它所能看到的数据快照是由两部分组成的,某个事务号下的数据快照,以及当前事务所产生的未提交数据。
另外,如果结合了游标的机制,事务的快照实现就会更加复杂。
begin;
--位置A--
insert into t_user(id,name) values(1,'fish1');
insert into t_user(id,name) values(2,'fish2');
insert into t_user(id,name) values(3,'fish3');
--位置B--
游标 = select * from t_user;
--位置C--
insert into t_user(id,name) values(4,'fish4');
delete from t_user where id = 3;
--位置D--
for 游标数据{
显示出来
}
end游标机制允许获取事务中途时刻的一个数据快照,这是因为游标允许边删除边遍历这种功能。例如,在上面的例子中,游标看到的总是id为(1,2,3)数据,因为游标是在位置B获取的快照。在位置B以后即使对t_user进行任何的修改操作,都不会改变游标所能看到的数据快照。
另外,PG中的可重复读,与Mysql中的可重复读的区别在于:
- PG中的可重复读的for update操作,是没有间隙锁的,没有抵御新插入行,或者其他行update回来的数据的影响,它仅能锁着读出来的那些行,这是一种不充分的上锁方式
- PG每一行中隐含了数据版本号,在事务中update的所有行,当事务commit的时候,会自动检查这些行是否有修改过,它的原始版本号是不是事务开始时的版本号。这明显是乐观锁的一种实现方式,这一机制足以抵御了绝大部分幻读场景产生的问题了。并且这一机制是mysql中没有实现的,mysql中的可重复读必须是手动for update的,并没有任何自动的乐观锁机制的。
6.10.4 表锁
无论是PG还是Mysql,都会有悲观锁的操作,对于修改操作,会自动添加悲观锁。但是对于查询操作,我们需要用for update操作来进行显式的悲观锁上锁操作。但是,在PG中,仅仅在表级别的锁就有8种之多。
| 锁类型 | 名称 | 解释 |
|---|---|---|
| SHARE | 当前读 | 表示现在对表进行读操作,并且读的数据总是最新的,不能被改变的 |
| EXCUSIVE | 当前写 | 表示现在对表进行写操作 |
最开始的时候,就只有表级别的读写锁,两个锁类型。读写不兼容,写写不兼容,但读读是兼容的。
| 锁类型 | 名称 | 解释 |
|---|---|---|
| ROW SHARE | 意向读 | 表示现在对表的某些行有读操作 |
| ROW EXCUSIVE | 意向写 | 表示现在对表的某些行有写操作 |
意向锁的引入过程:
- 后来,因为表锁的粒度太大了,PG引入了行锁,就是以行作为粒度的锁,但两个事务读写不同的行时,他们是互相兼容的,不会堵塞的,这样并发量就大大提高了。
- 但是,并不是所有操作都能转换为行锁,就像给表增加index的操作,就必须使用SHARE的表级锁。当这些表级锁发生的时候,我们就要保证没有对行进行写操作,这就要逐个扫描行来检查是否有行锁,这样的效率明显太低。
- 所以,一个很显然的优化是,当有执行行锁操作时,表锁也要添加一个行锁标记,称为意向锁。ROW SHARE就是有行在执行读操作,ROW EXCUSIVE就是有行在执行写操作,这样就能避免对行扫描来查询是否有行锁的低效率问题。
- ROW SHARE与ROW EXCUSIVE之间是互相兼容的,和自身兼容的,因为它描述的只是表级别的是否有行读写操作而已,它们可能在不同的行之间进行读写,所以能兼容。但是,ROW EXCUSIVE与SHARE不兼容,EXCUSIVE与SHARE,ROW SHARE和ROW EXCUSIVE都不兼容,这是在语义上成立的。
| 锁类型 | 名称 | 解释 |
|---|---|---|
| ACCESS SHARE | 快照读 | 表示现在对表执行最新快照读操作,并且读的数据不保证不会改变 |
| ACCESS EXCUSIVE | 全冲突写 | 是一种语义扩充,某些场景需要一种对所有锁都冲突的锁类型 |
快照锁的引入过程:
- 在对表进行select操作时,依然需要获取SHARE锁,这个时候不能EXCUSLIVE或者ROW EXCUSIVE,就是当前写,与意向写都不行。原因很明显的,因为其他事务在写数据时,你去读取数据可能就会读取到未提交的修改数据,就是会造成脏读。所以,PG引入MVCC,多版本版本并发控制,就是每一行都有一个修改该行的事务号B。查询的时候,获取当前的事务号A去每个行去查询,检查这个行在当前的事务号A下是否可见。这样可以达到,如果该行的事务B未提交时,事务A是看不到它的,就不会看到事务中途的不一致数据,就不会产生脏读。同时,又能达到的效果是,其他事务在修改的时候,select查询可以正常执行,不会产生脏读,并发量大大提高。通过这种方式读数据,称为快照读,读取的是当前数据库的某个事务号下的数据快照,同时读的数据允许被其他事务所修改。
- MVCC是一个非常重要的改进,Mysql的Innodb也是有MVCC的,他们都能实现select操作不会阻塞,不会被update,delete和insert这些操作阻塞。但是,对于Sql Server来说,默认是不打开MVCC(Snapshot),select会被修改操作所堵塞,需要强制指定with(nolock)来避免堵塞,但这样会可能造成脏读。又或者显式指定MVCC,打开Snapshot来指定快照读。
- MVCC可以提高select的并发性,但并不保证select在所有的情况都不堵塞,例如,删除表,修改表结构的时候,你总不能也让select同时也能运行吧。所以,这个时候,你需要用一个锁来与当前的ACCESS SHARE冲突。不能用EXCUSIVE锁,因为EXCUSIVE锁与ACCESS SHARE锁,兼容。因此,定义了一个新的锁,ACCESS EXCUSIVE,全冲突锁,它不是快照写的意思,也是与一种语义上可以与ACCESS SHARE冲突的锁类型。当删除表,修改表结构的时候,就需要获取这种锁。
| 锁类型 | 名称 | 解释 |
|---|---|---|
| SHARE UPDATE EXCLUSIVE | 当前读,但允许意向写,但不允许同类进行,也不允许SHARE读 | 语义的补充,部分场景下需要稍微放松的当前读,允许行写,比起SHARE来说,不堵塞行写,但是全表只能一个在执行。是一种SHARE锁的放松模式 |
| SHARE ROW EXCLUSIVE | 当前读,但不允许同类进行,也不允许SHARE读 | 语义的补充,部分场景需要稍微严格的当前,不仅与SHARE一样不允许行写,并且全表只能有一个在执行。是一种SHARE锁的严格模式 |
这两种锁是语义补充的锁:
- SHARE锁就是当前读,这个还是很好理解的,加了这个锁的时候,就不兼容ROW EXCUSIVE(行写)或者ACCESS EXCUSIVE(表结构写),或者EXCUSIVE(全局写)了。但是,它允许自身并发进行。常用的场景就是,创建索引了,因为索引的数据必须与数据本身是完全同步的,创建索引的过程修改数据是不允许的。
- SHARE UPDATE EXCLUSIVE锁,就是对当前读的放松。例如,PG定时要对表数据的分布就分析,以生成好的查询过程,这个叫ANALYZE。分析的结果可以与数据本身是稍微不同步的,稍微不精确也是允许接受的,毕竟短时间的数据变化不太会影响查询过程的结果。即使结果生成有偏差,最多也是查询过程会选择稍微差一点路径,结果还是对的。所以,这个时候如果SHARE锁,就会堵塞行写的操作,并发量就降低了。因此PG引入SHARE UPDATE EXCLUSIVE锁,当前读的模式,但允许行写,但是全部只能一个在执行,而且不兼容SHARE锁。同理,create index concurrently,vacuum也是需要请求这个锁。
- SHARE ROW EXCLUSIVE锁,就是对当前读的严格。与SHARE锁一样,对不兼容ROW EXCUSIVE(行写)或者ACCESS EXCUSIVE(表结构写),或者EXCUSIVE(全局写)了。同时,也不允许自身并发进行。PG命令没有这样的场景,这是预留的锁模式而已。
6.10.5 表锁场景
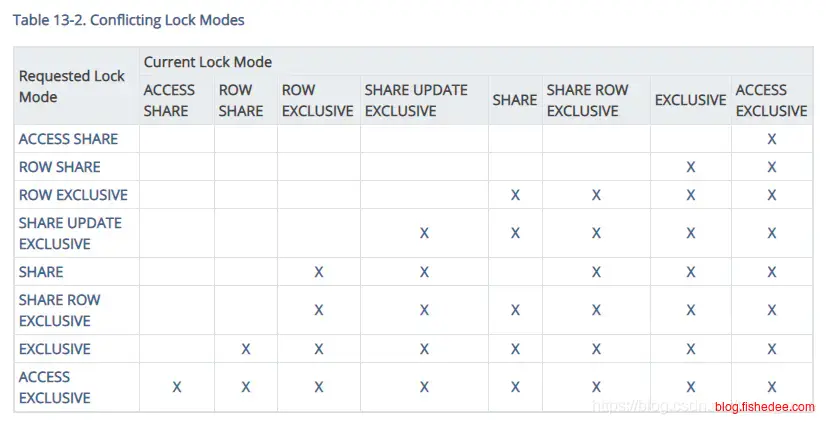
有了对这些表锁的认识后,我们就能得出以上的这张表锁兼容表了
| 锁 | 场景 |
|---|---|
| ACCESS SHARE | 普通的select命令 |
| ROW SHARE | select for update和select for share命令 |
| ROW EXCLUSIVE | update,delete,insert都会加这些锁 |
| SHARE UPDATE EXCLUSIVE | vaccum(不带full),analyze,create index concurrently命令 |
| SHARE | create index(不带concurrently)命令 |
| SHARE ROW EXCLUSIVE | 不会自动请求这种锁 |
| EXCLUSIVE | 不会自动请求这种锁 |
| ACCESS EXCLUSIVE | ALTER TABLE,DROP TABLE,TRUNCATE,REINDEX,CLUSTER,VACCUM FULL会请求这种锁 |
结合锁的用法,我们能看到这些锁的使用场景
lock table name in lockmode [NOWAIT]我们可以手动向某个表加锁
6.10.6 行锁
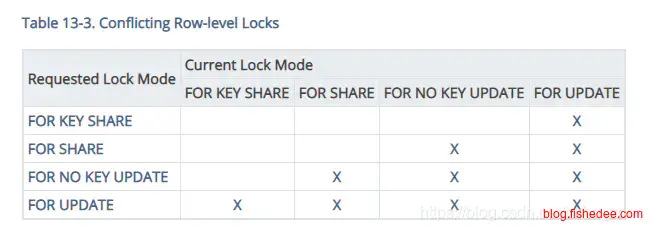
对于PG来说,某一行有四种上锁的模式,他们的相互兼容表如上图。为什么有这么多的行锁类型:
最开始的时候只有for update锁,就是互斥锁,一旦某个事务获取到了这个锁以后,其他事务就只能被堵塞了。update,delete,insert默认都会这些行加这个锁类型,你可以手动用select … for update来加这个锁
select * from t_tenant where tenantId = 10001 for share;
insert into t_user values(tenantId,userId) values (10001,10002);但是这样做的并发量低,因为有些场景我们只是要求对这个行不能被改变,而不是而去修改它。例如,当租户已经激活的情况,才能在该租户下添加新用户。添加新用户的这个sql操作时仅要求租户的激活字段是在事务过程里面保持不变就可以了。如果使用for update对租户上锁,就会使得该租户下其他的添加用户请求都会被堵塞。因此,正确的用法应该用for share锁。这个时候其他事务如果使用for update这一行就会被堵塞,而其他事务如果使用for share这一行就不会等待。所以,for update锁又称为共享锁。
select * from t_depeartment where departmentId = 10001 for key share;
insert into t_employee values(departmentId,employeeId) values (10001,10002);在更加细分的场景下,PG提供了粒度更细的行锁方式,就是for key share以及对应的for no key update。它的意思是,我们仅要求这个行的主键不能被改变,修改这个行的非主键信息是允许的。例如,添加雇员的前提条件是,这个部门是存在的,这个部门名字是否被改变都没有问题,但是,该行被删除,或者update语句修改了主键都是不兼容的。这个时候,并发量进一步加大,因为允许了大部分的update语句,与select for key share语句的并发运行。另外,PG提供了对应的for no key update的锁类型,就是上锁是承诺只为了修改非主键字段,绝不修改主键字段。
| 行锁类型 | 含义 |
|---|---|
| for update | 承诺对该行进行写 |
| for not key update | 承诺只对该行的非主键字段进行写 |
| for share | 承诺只对该行进行当前读 |
| for key share | 承诺只对该行的主键字段进行当前读 |
这就是行锁的类型的四种区别了,绝大部分的场景下,我们就是无脑进行for update操作就可以了。在一些并发要求高的场景,我们就要仔细安排不同的行锁类型。
| 序号 | Blob操作 | Alice操作 |
|---|---|---|
| 1 | begin; | begin; |
| 2 | select * from t_money where userId = 10001 for share; | |
| 3 | select * from t_money where userId = 10002 for share; | |
| 4 | update t_money set money = 50 where userId = 10001; | |
| 5 | update t_money set money = 150 where userId = 10002; |
如果你上的锁的承诺比实际操作不匹配的时候,就可能产生死锁。例如,Blob和Alice的账号都有100元,现在要从Blob转钱到Alice。实际上的Blob和Alice账号的select操作都是为了进行update的,但是使用的是for share锁。就会导致第2和第3步,两个事务都互相兼容,都获得了for share锁。然后第3步Blob的update操作进一步要求获得该行的for update锁,因此等待Alice事务释放for share锁。但是第4步的时候,Alice也请求该行的for update锁,因此需要等待Blob事务释放for share锁。BOOM,死锁发生了。解决的办法是将2步和第3步都改为for update锁就可以了。
| 表锁 | 场景 |
|---|---|
| ROW SHARE | select for update和select for share命令 |
| ROW EXCLUSIVE | update,delete,insert都会加这些锁 |
还记得,我们在上一节讨论表锁的场景时,for update和for share为啥都是ROW SHARE表锁,而update,delete,insert都是ROW EXCLUSIVE锁呢?因为,select…for update操作仅仅是对行进行上行锁而已,并没有真的改变数据,所以是不需要ROW EXCLUSIVE锁,ROW SHARE锁的特点是,兼容SHARE锁。也就是当行使用select…for update操作时,create index的操作(SHARE锁)是允许同时执行的。但当行执行update,delete,insert操作时,create index就真的没法允许同时执行了。
最后,留一个尾巴,PG的行锁是对堆表中的记录进行上锁而已,仅仅是一种记录锁,并没有像Mysql一样根据索引进行上锁,因此它没有间隙锁,也没有next-key锁。因此它没有对新insert的数据上锁,也没有对原有行update回来的匹配行进行上锁,它的for update操作并不是可靠的当前读操作(查询到的结果承诺不被其他事务所修改)。
6.11 约束补充
alter table employee add constraint employee_number_unique unique(number) deferrable initially deferred ;加入唯一性约束,其中deferrable initially deferred就是延迟到事务提交的时候才进行约束检查,默认是每个语句提交的时候就进行约束检查。看这里
create index print_template_scene_id_index on column_constraint(scene_id,position_id) ;创建索引
7 PostgresSQL的核心架构
7.1 进程架构
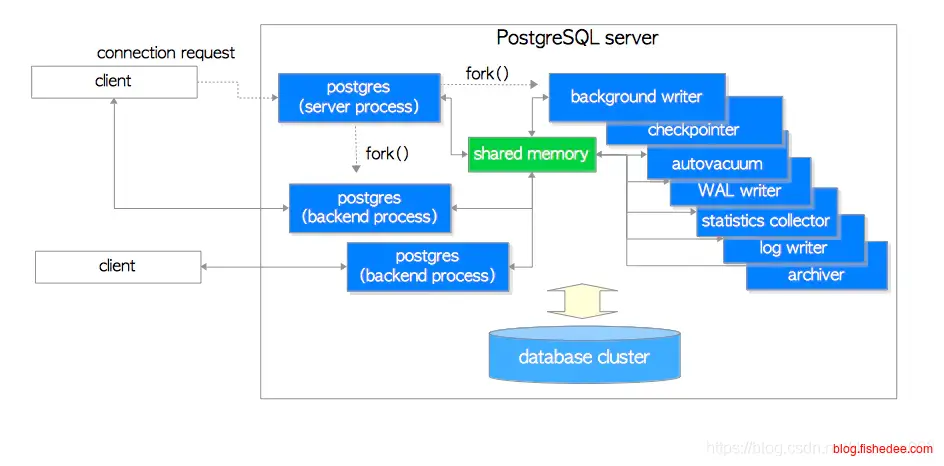
PG是一个多进程架构
- Postmaster主进程,负责接收请求并fork子进程,以及fork辅助进程
- Postgres进程,每个连接一个子进程,跟Mysql的多线程架构是不同的
- SysLogger进程,系统日志进程,系统日志写入到log文件夹
- BgWriter进程,后台写进程,写数据时先写WAL,然后再写共享缓存区的。缓存区的数据定时由BgWriter写入到磁盘中。典型的随机写改为顺序写的方法。
- WalWriter进程,预写式日志,WAL日志会落地到xlog文件夹。
- PgArch进程,归档日志进程,WAL日志是循环使用的,可能会被覆盖。归档日志负责定时将WAL日志归档压缩保存到额外的地方,避免被覆盖。
- AutoVaccuum进程,自动清理进程,PG的删除都不是物理删除,仅仅是一个标记这个行被删除而已。同样的,修改也是标记原来的行被删除,然后再添加新行。所以,PG需要定时清理行,将空间压缩腾出来给新插入的数据。
- PgStat进程,统计数据收集进程,就是定时执行Analyze进程的地方,对表和索引的统计信息能生成更好的查询计划。
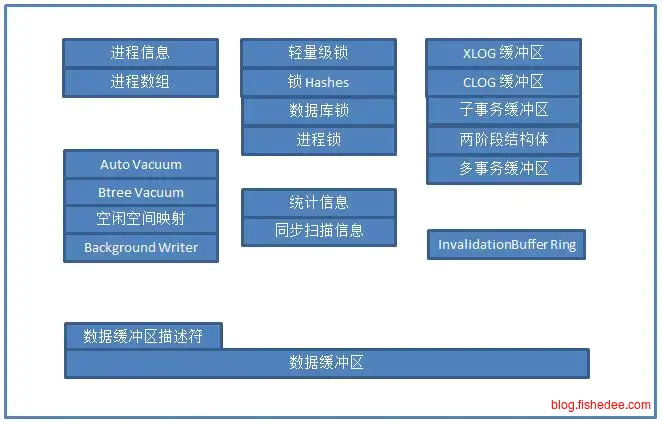
共享内存,就是存储每个进程共享数据的地方。
- 数据缓冲区,磁盘上的块的内存缓存,能避免每次都是进行磁盘读写
- XLOG缓冲区,就是WAL日志,每个事务提交时必须flush到xlog文件
- CLOG缓冲区,就是事务标记,记录每个事务号是已经提交的,未提交的,还是进行中的。这是一个简单的位图实现。
7.2 目录架构
安装目录一般在/usr/local下
- bin,二进制文件
- include,头文件
- lib,动态库文件
- share,配置模板,文档,以及扩展的extension
数据目录,就是$PGDATA环境变量的目录,每个数据库对应一个PGDATA目录
- postgresql.conf,主配置文件
- pg_hba.conf,认证配置文件
- base,默认表空间的目录,存储table,index,fpm,vm等文件的地方
- global,共享系统表的目录
- pg_clog,clog目录
- pg_xlog,WAL日志的目录
- pg_log,系统日志目录
- pg_stat_tmp,统计信息的存储目录
8 服务管理
8.1 内存配置项
- shared_buffers,共享内存缓冲区的数量,一般设置为物理内存的25%。参数为8KB的倍数。
- temp_buffers,每个数据库会话的临时缓冲区最大数目,参数为8KB的倍数。该参数用于临时表的大小。
- work_mem,内部排序操作和Hash表在使用临时磁盘之前可使用的内存数目,参数为1KB的倍数。ORDER BY,DISTINCE和MERGE JOINS都要用到排序操作,Hash则用来Hash Join,和Hash聚集。
- maintenance_work_mem,维护性操作中所能用到的最大内存数,参数为1KB的倍数。维护性操作包括,VACUUM,CREATE INDEX和ALTER TABLE ADD FOREIGN KEY等
8.2 WAL日志的配置项
- wal_level,配置为minimal,最小的信息,仅能恢复崩溃和掉电产生的数据库。配置为archive,会添加归档用的信息。配置为hot_standby,会添加一些备库产生的信息。
- fsync,设置为on,就是写入WAL日志后需要调用flush操作,保证数据都已经落到磁盘中,而不是系统缓冲区中。除非数据库不重要,或者正在做临时的备库重建操作,否则不要设置为off。
- wal_fsync_methd,flush操作的实现,在linux下默认为fdatasync,在windows下默认为fsync_writethrough。
WAL日志先写入到内存的Buffer里面
- wal_buffers,在共享内存区存储WAL日志的缓冲区数目,参数为8KB的倍数。默认为8,即64KB,一般仅需要够一次事务生成的WAL数据即可。
在内存的WAL日志为有两种写入到磁盘的方式,事务commit时写入磁盘,或者定时写入磁盘。
- synchronous_commit,设置为true的时候就是事务commit时写入磁盘,这样能保证每个事务都不会丢失。设置为false的时候,掉电会丢失最近的一部分事务。
- wal_writer_delay,如果事务不commit,则由wal_writer_delay来控制周期间隔多长时间写入到磁盘中,默认为200毫秒。由于一般事务的时间都少于200ms,所以这个数值一般是当synchronous_commit设置为false以后,才有意义。
WAL日志的数据都是,在某个数据块上的insert/delete/update元组的逻辑日志。
- full_page_writes,WAL日志会定期产生检查点,检查点是将脏页数据buffer都全部写入到磁盘,这是为了缩短崩溃时恢复的时间。恢复的时候,只需要从最近的检查点后面重做WAL就可以了。但是,崩溃的时刻可能发生在检查点生成的时刻之间,这个时候,由于磁盘的原子写是4KB,而一个PG的一个逻辑数据块为8KB,就有某个数据块可能出现一半新的,一半旧的情况,恢复的时候就不能完全恢复。因为WAL日志记录的是逻辑操作信息(insert/delete/update),不是二进制操作信息,一个损坏的页面可能已经insert过这个元组了,WAL日志又再次insert元组就会出现重复的问题。解决办法是,检查点之后,某个位置的数据块在修改前,要将整个原始数据块都写入到WAL日志,而后只需要写数据块改动的WAL日志就可以了。恢复的时候先校验该数据块是不是有损坏的,有的话先用原始数据块恢复,再重做WAL日志。full_page_writes参数设置为on,能保证最好的数据安全性,设置为off,有小概率机会无法恢复数据。
8.3 访问控制配置文件
local <dbname> <user> <auth-method> [auth-option]
host <dbname> <user> <ip/masklen> <auth-method> [auth-option]
hostssl <dbname> <user> <ip/masklen> <auth-method> [auth-option]
hostnossl <dbname> <user> <ip/masklen> <auth-method> [auth-option]主要分为两种,local为使用unix套接字时的验证方式,host的为使用TCP/IP连接的验证方式
auth-method主要为:
- trust, 无条件接受连接,常用于与unix套接字结合使用
- reject,无条件拒绝连接
- md5,md5加密的口令
- password,未加密的口令
- ident,使用操作系统的身份认证登录
ip/masklen主要限制了登录用户的来源IP名单
8.4 备份和恢复
#使用特定的账号密码备份远程的数据库
pg_dump -h 192.168.122.1 -Uosba osba > osba.sql
#使用compress格式备份远程的数据库
pg_dump -Fc -h 192.168.122.1 -Uosba osba > osba.dump#使用plain格式恢复数据库到postgres数据库
pg_restore -h 192.168.122.1 -Uosba -d postgres osba.sql
#使用compress格式恢复数据库到postgres数据库
pg_restore -h 192.168.122.1 -Uosba -C -d postgres osba.dump8.5 Windows的备份
env "PGPASSWORD=123" pg_dump -h localhost -d database -U user --schema=schema -f file.sql --encoding UTF-8 --no-owner备份指定database下面指定schema,到file.sql文件
env "PGPASSWORD=123" psql -h localhost -p 5432 -U user -d database -f file.sql从file.sql文件中恢复到database。
INIT_SCHEMA_SQL="drop schema if exists ${SCHEMA} cascade;create schema ${SCHEMA};GRANT ALL ON SCHEMA ${SCHEMA} TO postgres;GRANT ALL ON SCHEMA ${SCHEMA} TO public;"
PGPASSWORD=123 PGCLIENTENCODING=UTF-8 psql --single-transaction --set ON_ERROR_STOP=on -U user -c "${INIT_SCHEMA_SQL}" -d database 直接执行命令,数据库为database
8.6 阿里云备份和恢复
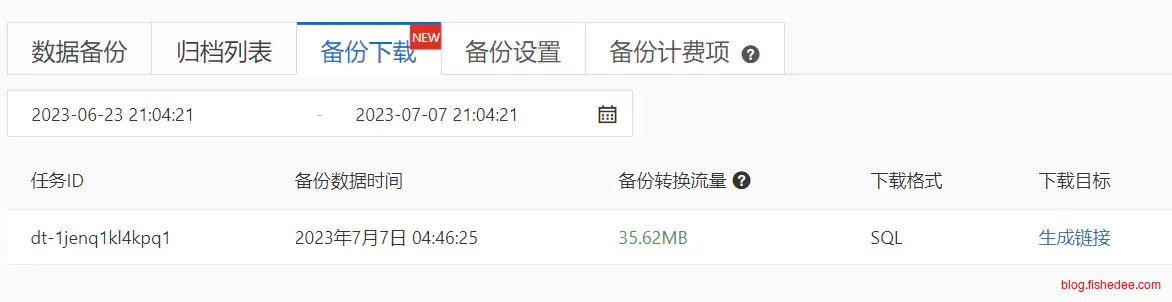
使用阿里云导出sql版本的备份

得到的是绝望的多层嵌套文件夹sql文件
#!/bin/bash
root_directory="data" # 替换为您的根目录路径
output_file="combined.sql" # 替换为输出文件的路径
queue=("$root_directory")
echo "" > "$output_file"
while [ ${#queue[@]} -gt 0 ]; do
current_dir="${queue[0]}"
queue=("${queue[@]:1}")
for file in "$current_dir"/*; do
if [ -f "$file" ] && [[ "$file" == *.sql ]]; then
cat "${file}" >> "$output_file"
echo "" >> "$output_file"
elif [ -d "$file" ]; then
queue+=("$file")
fi
done
done
echo "SQL files merged into $output_file"先用bash,用广度优先算法来添加sql文件,生成文件为combined.sql
CREATE DATABASE xxx;删除create database的语句
CREATE SCHEMA "t10001_0"将if not exists删掉
PGPASSWORD=123 PGCLIENTENCODING=UTF-8 psql --single-transaction --set ON_ERROR_STOP=on -U user -d db -f combined.sql直接导入就可以了,如果导入过程中有异常的话,要检查一下数据表
9 PostgresSQL的执行计划
9.1 查询计划
explain select * from testtab1;
explain (analyze true,costs true, buffers true) select * from testtab1;参数:
- costs,会显示每个计划几点的启动成本和总成本,该值默认为true
- analyze,会实际执行SQL来获得执行计划,显示每一步实际执行的时间
- buffers,会显示关于缓冲区使用信息,必须与analyze一起使用。
9.2 扫描方式
支持的扫描数据的方式:
- 全表扫描,Seq Scan。在堆表中从头到尾逐个扫一遍。
- 索引扫描,Index Scan。在索引查找数据,得到各个行的具体位置ctid,包括了数据块号和数据块中的行号,然后返回到堆表中找到完整的列。
- 净索引扫描,Index Only Scan。在索引中查找数据,并且索引中包含需要的列,就不需要返回到堆表中获取列了,所以叫Index Only Scan。
- 位图扫描,Bitmap Index Scan。在索引中匹配数据以后,得到的不是行的具体位置ctid,而仅仅是行的所在数据块块号。那么,就要先将数据块号写入到内存的位图Bitmap中。由于索引中只得到了数据块号,而没有行号,因此还需要在数据块中进行二次筛选操作,这叫Bitmap Heap Scan。具体操作为根据内存的Bitmap显示的数据块位置来顺序扫描匹配的数据块,并且在每个数据块中扫描该块所有的行来重新Recheck筛选条件来得到实际匹配的行。
- 条件过滤,就是边扫描,边过滤。
9.2.1 位图扫描意义
位图扫描是PG的特色功能,避免了Mysql中的查询回表的随机查询问题。在没有位图扫描的时候,查询是两步的:
- 先用索引匹配到一行数据
- 然后根据这行记录的数据块位置,回到堆表中获取所有列信息。然后回到第1步,查找下一个匹配行。
有了位图扫描以后,查询是分三步的:
- 先用索引匹配到每一行数据,将数据块位置写入到位图中
- 顺序扫描位图的1位置,获取每个数据块的位置
- 依次根据数据块位置,回到堆表中获取整个块,
- 然后扫描该数据块的所有行,重新筛选条件来匹配行。
位图扫描的意义为:
- 先获取所有数据块位置,才去读数据块,避免数据块随机读IO,保证尽量的顺序读。
- 多行数据可能匹配到同一个数据块中,第一种方法会不断来回重读同一个数据块,但位图扫描自带数据块位置去重,避免这种情况
- 位图扫描,允许在多条件查询的场景下,使用多个索引的匹配行的位图信息,来做and或者or。最终生成的位图仅一次回到堆表中查所有列信息就能完成查询,这在Mysql中是无法做到的。
- 但位图扫描的缺点在于,位图中只有数据块块号信息,没有行号信息,相当于丢失了索引的准确匹配行信息。造成还需要额外增多了一次扫描该数据块中的所有行操作的工作,CPU需要不断Recheck所有的行。幸好的是,位图扫描不会造成多余的IO操作,毕竟即使只匹配一行,也需要读一整个块。
- 为什么位图扫描中不存储完整的ctid值,而仅存储块号信息。因为每个数据块的有多少个行是完全不确定的,有些行比较短,一个数据块就能放多点行,有些行比较长,一个数据块只能放很少行。所以ctid无法高效地一一对应转换为一个整数,从而构造这样的位图。可能进一步地,你想用hash表来保存ctid,但这样得出的ctid值不是递增的,回堆表扫描时会产生随机IO的问题,并且hash表不能实现高效的多索引的and与or操作。
9.2.2 位图扫描场景
场景:
- 同时使用多个索引进行and与or操作,每个索引的筛选得出一个bitmap,然后对多个bitmap执行and或者or操作,最后一次性回表recheck。
- 索引不支持index scan。例如gin索引,gin索引就是一个倒排链,每个链的posting list或者posting tree存放了完整的ctid值。但是最终结果总是合并多个倒排链的结果,这不是一件容易的事情,因为ctid的值不是连续的。因此gin索引的方式就是扫描单条倒排链,生成一个bitmap位图,然后将多个位图进行合并。虽然这样做会丢失ctid的行号信息,但是合并速度很快,算法简单可靠。因此,gin索引的返回结果总是一个bitmap index,不支持index scan的。
- 不精确索引,例如brin和boom索引,返回的结果本身就是不精确的,不可能支持index scan,只支持bitmap index scan。
9.3 连接方式
支持的连接数据的方式:
- 嵌套连接,遍历外层表(outer table),然后对于外层表的每一行,寻找内层表(inner table)的对应的每一行。显然,这种方法的时间复杂度为O(mn)。时间复杂度比较高,如果内层表有连接条件的索引,那么时间复杂度能降低到O(m log n)。这种方法仅适用于外层表(又称驱动表)比较小,内层表又有索引的情况下。
- 哈希连接,将两个表中较小的一个完全放入内存中,以连接条件作为key的生成哈希表。然后遍历大表,探测哈希表来生成连接。显然时间复杂度为O(m+n),这样的时间复杂度比较低。如果较小的表不能完全放入内存,PG则会将表划分成多个个分区,来分段连接处理。这种情况下,你应该尽可能配置更大的work_mem数值。
- 合并排序连接,如果两个表都是已经排序的,或者是有排序索引的。那么就只需要做一次,合并操作就可以了。显然时间复杂度为O(m+n)。虽然时间复杂度和哈希连接一样,但这种方法不需要建立哈希表,也不会占用大部分的内存,是最优的连接方式。也要注意,最优方式的前提是,这两个表在连接前都已经排序好了。
Mysql中仅支持嵌套连接的方式,即使Mysql 5.6也仅引入了Block嵌套连接的优化方式,仅优化了磁盘IO,并没有从根本性降低时间复杂度,直到Mysql 8才支持了Hash连接的方式。如果业务有巨大的分析操作,需要很多join的地方,PG会比Mysql好得多。
10 PostgresSQL中的技术内幕
10.1 系统字段
每个表都有几个隐藏的系统字段,即使select * 也不会显示出来的,只会在强制select 指定列名称的时候才会出来。
- oid,默认没有。行对象标识符
- tableoid,继承表的时候才有。包含本行的表的oid。
- xmin,插入该行版本的事务ID。
- xmax,删除此行版本的事务ID。
- cmin,事务内部插入类操作的命令ID。
- cmax,事务内部删除类操作的命令ID。
- ctid,数据块的物理位置。
每个字段都不容易理解:
10.1.1 oid
oid列名的数据类型就是oid,列名和数据名是相同的。oid是可以作为一个表的主键,用四字节的无符号整数来实现。它的特点是,该oid的分配是全局跨表分配的,不是每个表范围内的自增ID。PG将oid作为各种系统表的主键,不建议用户使用oid作为表的主键。
#普通情况下,获取16628的pg_class的名字
select relname from pg_class where oid = 16628;
#可以快捷地直接转换
select 16628::regclass;
#普通情况下,获取名字为t的pg_class的主键oid
select oid from pg_class where relname = 't';
#反过来,也可以可以快捷地直接转换
select 't'::regclass;oid的意义,在于,他可以快捷将整数转换为各个系统表的名称,或者反过来用。它可以将这串数字看成一个唯一标识符,放在不同的环境,可以得出不同的名字。
| oid引用环境 | 表名 | 含义 |
|---|---|---|
| regproc | pg_proc | 函数名字 |
| regprocedure | pg_proc | 带参数类型的函数名字 |
| regoper | pg_operator | 操作符名字 |
| regoperator | pg_operator | 带参数类型的操作符名字 |
| regclass | pg_class | 表名或者索引名 |
| regtype | pg_type | 数据类型名 |
| regconfig | pg_ts_config | 全文检索配置 |
| regdictionary | pg_ts_dict | 全文检索路径 |
10.1.2 tableid
用来区分继承表中,父表的数据来自于哪个子表
10.1.3 ctid
(10,2)ctid就是数据行在所处表内的物理位置,类型为tid。ctid由两部分组成,物理块号,和物理块中的行号。
注意这里和Mysql的不同处理方式,mysql的innodb中的索引存储的是行主键,而PG的索引存放的是物理位置。行的主键是逻辑上的标记,但行的位置是物理上的标记,这会造成仅修改非索引数据都会产生索引修改的问题。因为当修改行的内容的时候,PG会先标记旧行删除,然后再在新数据块添加一行,原索引的ctid就要被迫发生改变,即使修改的不是索引的列数据。这确实是PG的一个设计缺陷,根本原因是PG中仅支持堆表的存储结构产生的。
另外,PG中的多版本并发控制不是用回滚段来实现的,是用原地标记来实现的。需要定时的清理进程vacuum来回收无用的行数据,所以,当vacuum发生时,PG会将相邻的行碎片合并,造成ctid变更,这又会再一次产生索引需要更新的问题。
10.1.4 xmin,xmax,cmin,cmax
xmin和xmax,是标记不同事务对这一行的操作版本。xmin是对这行进行插入操作的事务号,xmax是对这行进行删除操作的事务号。为啥没有修改事务号,因为PG从来不会物理修改数据行,它是通过标记旧行删除,然后添加新行来实现逻辑修改行的。
cmin和cmax,是标记同一个事务中对这一行的操作版本。cmin和cmax的含义,其实和xmin和xmax是一样的,但是它是用来区分同一个事务中的不同命令行所产生的数据版本。具体可以看一下,6.1.3关于游标对同一个事务中的不同命令行的不同数据版本的展示。
10.2 多版本并发控制
10.2.1 实现原理
要实现MVCC,有两种方法:
- 写数据时,把旧数据移动到一个单独的地方,如回滚段中,其他人读数据时,从回滚段把旧数据读出来。如果有多个人在读取该行的多个不同版本,那么回滚段中就会有该行的多个版本数据,各个版本之间用链表连接起来。
- 写数据时,旧数据不删除,而是把新数据插入。每一行相当于都是不变的,行上带有一个版本标志。
PG使用的是第二个方法来实现MVCC,而Oracle和Mysql的Innodb使用的是第一种方法来实现MVCC。
那么,在事务提交或者回滚的时候,会产生什么呢?
- 第一种方法,事务提交时就会在回滚段中查询旧行是否有事务在查询的,没有的话要清掉回滚段的旧行数据。事务回滚时,要将回滚段的数据重新复制到原来的位置。
- 第二种方法,事务提交与回滚时,仅仅需要的是更新clog中该事务号的状态就可以了。但是,对应查询的时候,需要去除掉数据块中已经回滚的行。
因此,我们明显得出这两种方法的优缺点:
- 第一种方法,Oracle和Mysql所用的方法,大事务提交和回滚时需要对回滚段进行操作,耗时更长。另外,大事务会受到回滚段的空间限制,当多个事务运行时,有可能因为回滚段不足导致事务被迫中断。ORA-1555错误。但是,优势在于,数据块里面没有旧数据,查询要扫描的行更少。
- 第二种方法,PG所用的方法,无论多大的事务都不用担心被中断,也没有回滚段空间限制。大事务提交和回滚的速度也很快,因为仅仅需要更改clog中的标志就可以了。但是,缺点在于,数据块里面有旧数据,查询要扫描的额外行多,而且需要定时执行vacuum来清理旧数据。
PG中的事务号有个大坑,每个事务ID仅用32位整数来描述。因为全局数据库,每修改一次操作就得分配一个新的事务ID。32位仅有40亿次操作,根本不够用,就会造成事务ID回卷的问题。一旦事务ID回滚后,判断事务的新老就会出问题。
10.2.2 事务ID回卷
InvalidTransactionId = 0
BootstrapTransactionId = 1
FrozenTransactionId = 2PG的解决方法是事务ID分为两个半段来使用。首先,0,1,2作为预留的事务ID不作分配使用。然后,将\([3,2^{31}]\)称为上半段,\([2^{31},2^{32}-1]\)作为下半段,每半段大概都有20亿个数字了。然后,满足
- 人为规定,在任意时刻,数据块中事务ID中,最旧的和最新的事务ID的年龄差不能超过\(2^{31}\),这是通过启动定时进程,在vacuum中,定期将较旧的事务ID更改为2(刚好就是FrozenTransactionId),更改为旧事务ID为2称为冰冻操作。一般来说,冰冻是有条件的,该元组的年龄与最新的事务ID大于2亿才会执行,如果冰冻的条件太宽,那就会太多的事务要冰冻,定时任务的修改行数多。如果冰冻的条件太严,那么一般定时任务就不会执行冰冻,直到最后就会有太多的冰冻行要执行,拖慢了速度。
- 有了人为规定以后,比较两个事务ID新老的办法是,如果两个事务ID的差值超过20亿,那么新老方向就要调转一下。例如,当两个ID为10亿,和15亿,显然15亿的比较新。当两个ID是15亿和30亿,那么显然30的比较新。当两个ID为3和39亿,那么就是3的比较新。因为他们差值超过了20亿,这仅在回卷的情况才有可能发生的。
冰冻参数的可调参数为:
- vacuum_freeze_min_age,一般情况下,vaccum仅当该数据块的所有行都是可见的时候,才去执行冰冻操作。冰冻时,只有该行的年龄与最新事务的年龄大于vacuum_freeze_min_age时才执行冰冻操作。
- vacuum_freeze_table_age,但是,仅数据块的所有行都是可见条件太严格,因为某些行可能因为回滚,或者事务进行中的操作,不能被可见。因此,仅当该数据块的最旧行年龄与最新事务的年龄大于vacuum_freeze_table_age时会执行更细致的冰冻操作。
- autovacuum_freeze_max_age,最坏的情况下,一直不进行冰冻操作。该数据块的最旧行年龄与最新事务的年龄已经到达20亿的情况下,就强行停表进行vacuum的冰冻操作。
整体来说,将事务ID设置为64位就没这些蛋疼事,PG在这点上的确设计不好。
10.3 物理存储结构
每个数据块包括块头,行指针,行内容的信息。行指针从头部开始逐个放,行内容从尾部开始反过来逐个放,所以空闲位置就在中间。每个数据块的信息是:
- 块头,checksum,空闲空间的开始和结束位置。
- 行指针,32位整数,行内容偏移量,指针标记,行内容长度。
- 行内容,头部信息(oid,ctid,xmin,xmax,cmin,cmax,infomask),以及各个列的列值。
值得注意的是,行内容的头部信息中有一个infomask标记。因为提交和回滚事务时都是记录该事务标记到clog中。查询行数据以后,还要回到clog中查询该行的事务是否可见的。infomask加入了标记,当读取这行以后,并且回到clog中确定该行事务可见后。就只标记这一行为永久可见,这样下一次读取就不需要回到clog中查询了。
10.4 FSM空闲空间管理
插入新行的时候,显然要找到一个数据块能容纳这一行的。如果逐个查找每个数据块来获取哪个有足够空间,显然太慢了。PG的方法是使用多叉赢者树,方法是:
- 首先每个行的最大空间为8KB,直接用数字表达这个空间,需要2位整数。所以,将每行的空闲大小除以32以后下取整,最大值变为255,那么就只需要1位整数就能表达空闲位置了。唯一的代价是,空闲空间在32字节的精度范围内的。例如,空闲为33字节,和34字节,都是用数字1来代替。
- 然后每个表格建立一个对应的fsm文件,fsm文件只有三层。
- 最底层,就是第3层,就是每个数据块对应的空闲容量(字节数/32),每个数据块仅用1个字节来表达。第2层,就是以第3层中的依次以4000个块作为一个整体,这个整体的空闲容量的最大值。第1层,也是,以第2层中的依次以4000个块作为一个整体,这个整体的空闲容量的最大值。以此类推。
- 上层就是计算下一层的4000个块的空闲容量的最大值。那么,3层容量就能表达\(4000^3=640\)亿个数据块的空闲容量了,640亿个数据块就有476TB数据了,这完全足够用了。现在,查询空闲位置就快得多了,仅需要固定查询3次fsm文件块就能得到结果。
10.5 VM可见块管理
之前分析过,获取行数据以后,还需要回到clog中查询事务的可见性,效率不高。虽然后续在行的infomask标记中,记录该行是否有永久可见性,避免了回到clog中查询事务的可见性。但是,我们依然离不开,回到堆表读了行数据,才能知道该行的可见性。那么,即使索引包含了查询的所有列数据时,因为索引数据没有版本号的数据,我们依然需要回到堆表查询该行的可见性问题,效率依然不高。解决方法是:
- PG建立一个vm文件,它记录的是该数据块的所有行是否永久可见,这是一个简单的1和0的标志位。
- 在索引中拉到数据以后,根据ctid的数据块号,到vm文件中查询该数据块的所有行是否永久可见,是的话直接确定行可见,不是的话还需要到堆表做细致的查询。
- vm文件是在vacuum的时候生成的。因为vacuum在回收旧行的时候,也是要查询该数据块是否有不可见的行,因此vacuum可以边做回收,边生成vm文件,一举两得。
10.6 Index Only Scan
Index Only Scan就是仅索引查询的意思了,指查询的列数据可以在索引中直接获得,不需要回到堆表中检查该行的可见性,是在PG 9.3的时候引入的。可明显,不需要回堆表查询,就是因为有vm文件辅助达成的而已。如果该数据块的有部分行是不可见的,依然需要回到堆表中的数据块查询可见性。
另外,vauum执行的时候才会生成vm文件,所以如果没有vm文件的时候,是肯定需要回堆表查询的。
最后,explain中提示的Index Only Scan并没有完全代表就不需要回堆表查询,它只是表达有机会可以完全只用索引查询。回堆查询的真实情况,要看explain analyze的Heap Fetches数值。
10.7 Heap-Only Tuples
HOT技术就是在,因为索引的数据保存的是ctid,数据块行号,而不是表主键。所以,当旧行修改数据时,即使索引需要的key值没有改变,原有的索引也要跟着一起改变,因为数据块行号变了。
为了减少修改索引产生的磁盘操作,PG引入HOT技术,在旧行加入指针,指向同一个数据块中的其他行位置,就能避免修改原有索引的ctid值了。但是,如果同一个数据块已经满了,就无法使用HOT技术了,它只指向同一个数据块的其他行位置,这个时候就依然需要修改索引。HOT技术依赖于表的填充因子fillfactor,fillfactor不能太大,以预留在同一个数据块中的行修改数据。fillfactor太小的话,就会导致空间浪费。
11 PostgresSQL的特色功能
11.1 规则系统
11.1.1 语法
PostgresSQL的规则系统,就是查询改写功能而已。
create view myview as select * from mytab;
#相当于
create table myview (same column list as mytab );
create rule "_RETURN" as on select to myview do instead select * from mytab;视图就是一种查询改写
create rule name as event to table_name [where condition] do [instead | also ] {NOTHING | command | command}- event支持select,insert,update,delete
- also/instead,改写包括替换原来的命令(instead),以及运行原来命令的同时执行新的命令(also)。
- NOTHING/command,新命令可以是什么都不做
11.1.2 权限
视图的权限规则:
- 查询者拥有视图的查询权限
- 视图的属主拥有查询底层表的权限
11.1.3 与触发器区别
- 规则系统不支持COPY FROM,但触发器可以
- 批量行改写的时候,触发器只能逐行改写,规则系统可以直接改写整个语句
11.2 索引
PG的索引是一大特色
11.2.1 表达式索引
create index mytest_lower_note_index on mytest (lower(note));
select * from mytest where lower(note) == 'abc';我们可以建立lower表达式对note列的索引,索引上预存每一行的note列的lower计算结果,查询的时候直接走索引,避免表达式计算产生的全表扫描。注意,查询的时候的表达式要和索引的表达式完全一致,才能走索引。
11.2.2 部分索引
create index order_unbilled_index on orders(order_nr) where billed is not true;支持只对表中的部分行进行的索引。这样做的原因是,大幅减少索引需要的用量,因为不存在,billed已经支付的情况下,order_nr搜索。
11.2.3 Gist与SP-Gist索引
Gist索引是根据自身数据分布来划分的空间,SP-Gist是根据值域来划分的空间,两者都是类似R树的结构,在第6章的时候已经介绍过了
11.3 GIN索引
11.3.1 结构与查询
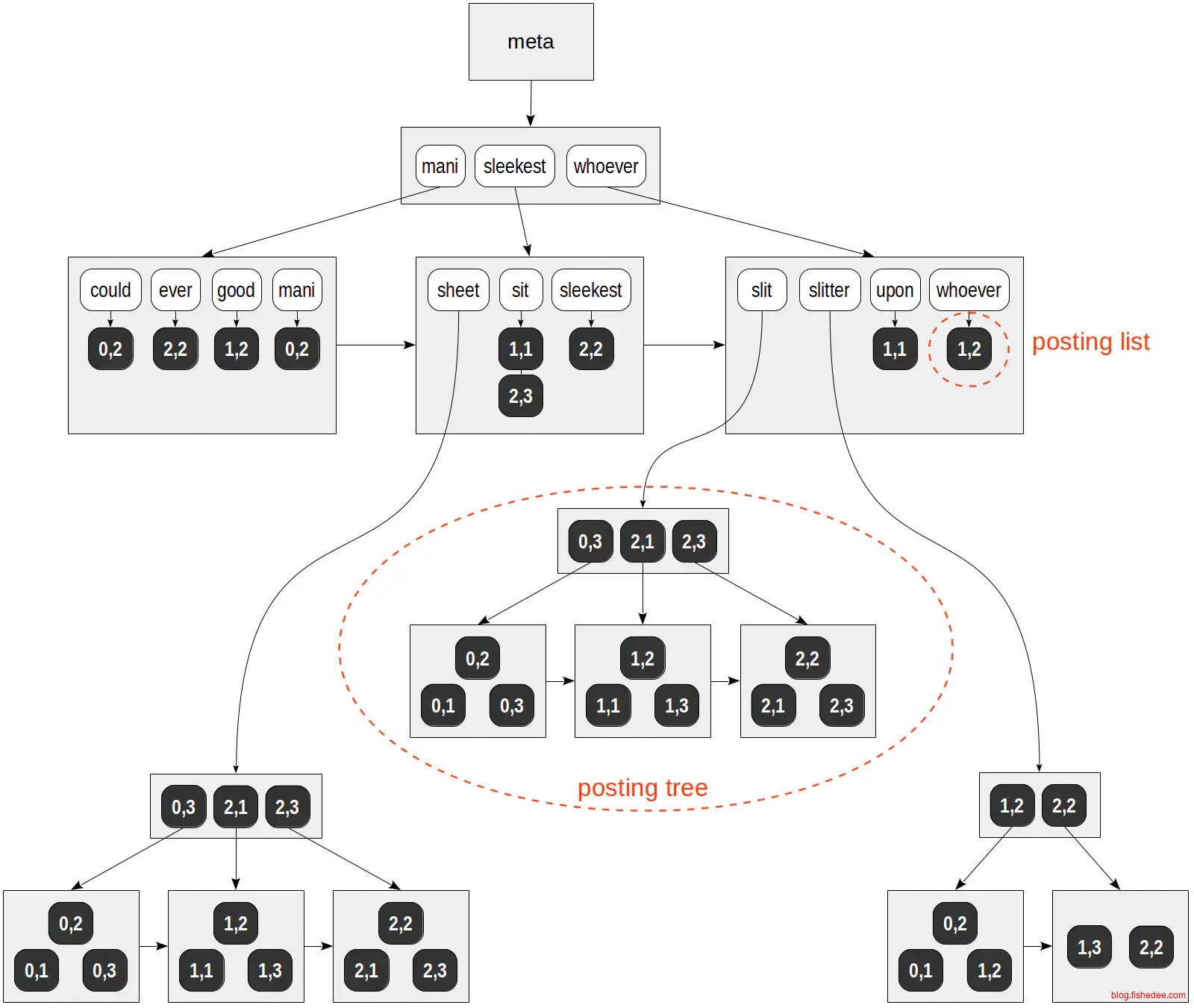
这是一个gin索引用作全文索引的结构图中。
- 每行句子中的单词拆分出来,各个单词都映射到一个ctid中。因此,会出现,某个单词会映射到多个文档上,多个ctid上。
- 单个单词映射多个文档的方式可能为posting list,也可能为posting tree。为什么不全部用posting list,因为要在强一致性的要求下,每次插入删除都要重新维护posting list,重新排序。这样的话性能下降会很快,因此,posting list长度达到一定大小后只能用posting tree来维护。值得注意的是,elasticsearch中放弃了强一致性,以实现高效维护posting list的能力。
- 多个单词之间的查找,依然采用类似B树的方式组织,好处是在gin索引依然能用范围查询。
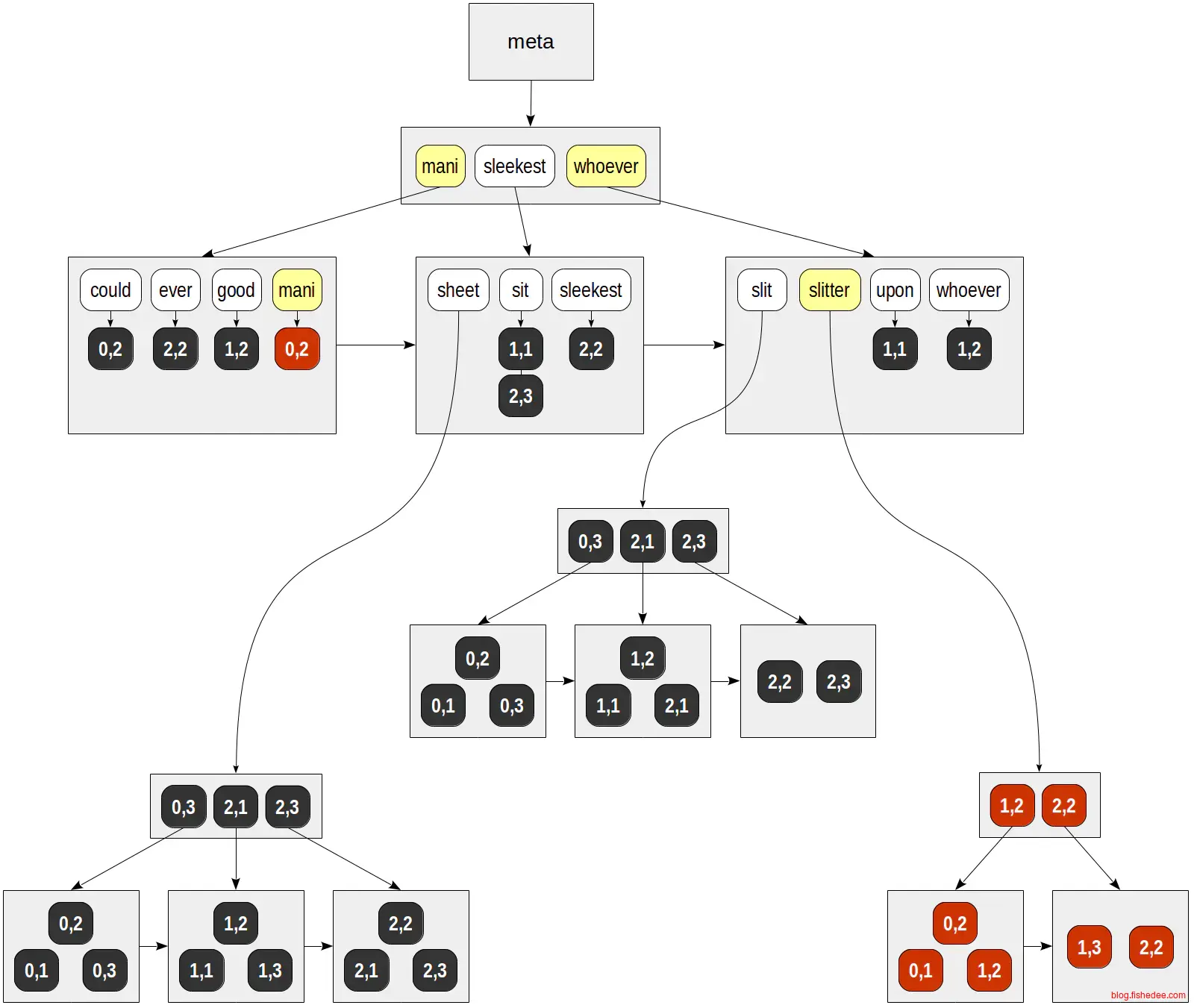
查询的时候,方法:
- 根据查询,拆解为多个单词,然后为每个单词获取它们的posting list或者posting tree。
- 对于每个posting list或者posting tree,生成一个bitmap index scan。
- 根据查询的要求,将多个bitmap index scan合并为一个bitmap
- 根据bitmap在堆表中执行bitmap heap scan的recheck操作得到最终的结果。
11.3.2 场景
根据结构和查询的流程,我们可以推断到gin索引的场景为:
- 适用于多字段多条件的组合查询
- 组合查询的选择性应该是非常好的,就是筛选后的行数应该是很少的
- 字段或者条件是范围查询的可以用,但效果没有btree的好
那么,gin索引做不好的场景是:
- 组合查询的选择性很差,因为bitmap只存储数据块块号,使用gin索引的时候总是会recheck一整个数据块,而不是只检查匹配的行。选择性差的字段会覆盖大部分的行,导致匹配几乎全部的数据块,对所有的数据块进行recheck,甚至比顺序扫描更低效率。顺序扫描不需要构造bitmap,选择性不好的gin索引需要合并很多的posting tree,最终得到一个筛选能力很差的bitmap。
- 对limit,order by和count(*)没有优化能力。合并posting list的方法是逐个生成每个posting tree的bitmap,然后统一的and或者or操作。这意味着无法在计算中途知道有多少个行能完全匹配条件,不能做提前的limit操作。另外,bitmap只有块号信息,没有行号信息,没有实现纯索引上的count操作。order by就更不用说了,gin的倒排链上没有记录额外的信息
fish-# explain (analyze,verbose) select title from t_recipe where title like '%蛋糕%';
------------------------------------------------------
Bitmap Heap Scan on public.t_recipe (cost=783.15..2600.39 rows=84019 width=26) (actual time=14.032..30.502 rows=84000 loops=1)
Output: title
Recheck Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Heap Blocks: exact=767
->; Bitmap Index Scan on t_recipe_title (cost=0.00..762.15 rows=84019 width=0) (actual time=13.912..13.912 rows=84000 loops=1)
Index Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Planning Time: 0.208 ms
Execution Time: 35.155 ms
(8 rows)取count操作的时候,也要建立完整的位图,然后在堆表中count
fish-# explain (analyze,verbose) select * from t_recipe where title like '%蛋糕%' limit 1000;
------------------------------------------------------------
Limit (cost=783.15..804.78 rows=1000 width=30) (actual time=13.195..13.450 rows=1000 loops=1)
Output: contentid, title
->; Bitmap Heap Scan on public.t_recipe (cost=783.15..2600.39 rows=84019 width=30) (actual time=13.194..13.342 rows=1000 loops=1)
Output: contentid, title
Recheck Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Heap Blocks: exact=10
->; Bitmap Index Scan on t_recipe_title (cost=0.00..762.15 rows=84019 width=0) (actual time=13.063..13.064 rows=84000 loops=1)
Index Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Planning Time: 0.148 ms
Execution Time: 13.531 ms取limit操作的时候,也要建立完整的位图,然后在堆表中逐个recheck,然后limit
fish=# explain (analyze,verbose) select * from t_recipe where title like '%蛋糕%' order by contentid asc limit 1000;------------------------------------------------------------------
Limit (cost=7207.06..7209.56 rows=1000 width=30) (actual time=37.443..37.630 rows=1000 loops=1)
Output: contentid, title
->; Sort (cost=7207.06..7417.11 rows=84019 width=30) (actual time=37.442..37.523 rows=1000 loops=1)
Output: contentid, title
Sort Key: t_recipe.contentid
Sort Method: top-N heapsort Memory: 135kB
->; Bitmap Heap Scan on public.t_recipe (cost=783.15..2600.39 rows=84019 width=30) (actual time=13.139..25.023 rows=84000 loops=1)
Output: contentid, title
Recheck Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Heap Blocks: exact=767
->; Bitmap Index Scan on t_recipe_title (cost=0.00..762.15 rows=84019 width=0) (actual time=13.030..13.030 rows=84000 loops=1)
Index Cond: (t_recipe.title ~~ '%蛋糕%'::text)
Planning Time: 0.123 ms
Execution Time: 37.718 ms
(14 rows)取order by操作的时候,也要建立完整的位图,然后在堆表中逐个recheck,然后在内存中做heapSort计算最终结果。
11.3.3 RUM索引
针对gin不擅长的场景,RUN索引针对性提出解决办法:
- posting tree中加入term position信息,就是单词的位置信息。甚至可以人工指定posting tree中加入的额外字段的信息。这意味着在rum索引扫描上就能实现like操作,<->操作等等。额外的字段信息,可以做timestamp排序等操作。
- 合并posting tree不再使用bitmap index scan,而是使用多路归并的方法。类似于合并排序的归并方法,这样就能高效地实现索引扫描上的limit和count操作了。当然,代价是,多路归并不好写,既要考虑合并的顺序,也要考虑匹配的条件是否满足,查询性能肯定也比bitmap合并的慢。
- 由于多路归并必须依赖于排序,所以gin索引中的fast update优化在rum中也无法实现,每次插入或者删除行,都必须要修改现有的多个posting tree。这意味着,插入或者删除的吞吐量下降。
create index rum_idx on t_recipe using rum (title_tsvector rum_tsvector_ops);
drop index rum_idx;创建一个rum索引
create index rum_idx on t_recipe using rum (title_tsvector rum_tsvector_addon_ops,t)WITH (attach = 't', to = 'title_tsvector');
drop index rum_idx;创建一个rum索引,并且人为指定额外的字段信息
select contentid,title from t_recipe where title_tsvector @@ string_to_tsquery('蛋糕') order by t <;=>; '2020-01-01 00:00:00' LIMIT 5;rum索引中,既做order by,也做limit,也做匹配工作的查询
试用过一段时间的rum以后,发现:
- 官方的rum也有很多bug,rum_tsvector_addon_ops操作无法正常使用
- rum受限于强一致性的限制,每次都要修改posting tree,插入性能大幅下降几乎无解
- 相比于gin,适用于order by+limit+term position测试的场景,这个场景的确很常见。
目前来看,对rum索引的前景并不乐观,这个技术路线受到强一致性的限制,很可能就做不下去。
11.3.4 操作符
gin索引默认对数组类型都支持,但是它如何对字符串实现模糊搜索的索引支持,或者对json和普通的int类型进行索引支持呢?关键在于,它可以自定义gin操作符
- extractValue,将需要索引的列值拆分为多个值
- extractQuery,根据where中的列操作符,对目标进行拆分
- compare,比较两个值,根据大小返回负数、0、正数
例如,如果要支持对一个字符串允许like操作的gin索引加速,那么我们可以定义一个gin_unigram操作符
- extractValue,将列的字符串按照每个字符的形式拆分多个字符。这样使得多个字符能对应到这一行上。
- compare,计算字符之间的比较值。这样能在btree中高效查找字符。
- extractQuery,当用户在where操作中执行like操作时,将like的输入拆分为多个字符。这样能在gin索引中按照这些字符进行匹配查找。
最终的匹配结果依然需要在堆表中recheck,进行like操作符的计算。
通过这个机制,我们可以根据插件的形式,增加其他类型的gin索引支持:
- btree_gin,对普通基本类型,int,float,timestamp等这些类型的gin索引支持
- intarray,增强的对int数组类型的gin索引支持
- pg_trgm,对字符串进行模糊匹配的gin索引支持
11.4 B-Tree索引
btree就是一个排序多叉树的实现。值得注意的是,在pg中可以通过添加操作符来自定义不同类型的排序方式。对于字符串来说,默认的排序方式是按照COLLATE字符集进行排序的。我们可以添加text_pattern_ops,varchar_pattern_ops和bpchar_pattern_ops按照ascii的8位字符的规则进行排序。要想让where操作的like xxx%查询能走索引,需要指定为text_pattern_ops排序,而不是使用COLLATE的排序方式
11.5 模糊搜索
11.5.1 前缀或后缀匹配
模糊匹配就是like操作,like操作具体有两种:
- 前缀或者后缀匹配,例如是abcd%,%abcd,默认btree就支持了前缀模糊匹配。后缀匹配的方式可以通过reverse字符串存入btree来实现
- 前后缀模糊的匹配,例如是%abcd%,这种查询时最麻烦的,在mysql中是无法走索引的,但pg的gin索引配合自定义操作符就可以做到走索引。
11.5.2 三元模型
首先,引入字符串的三元模型,就是指对字符串每隔3个字划分为一个单词。例如a64c58字符串,它可以划分为以下的三元单词
- a
- a6
- a64
- 64c
- 4c5
- c58
- 58
- 8
一个长度为6的字符串被划分为8个单词。那么这8个单词就存入到gin索引中,并且都指向到同一行的字符串中。如果我们要用sql语句where word like %4c58%的时候,查询就先将查询句子划分为以下的单词:
- 4c5
- c58
然后到gin索引中查找同时包含这两个单词的是哪个字符串,a64c58和b4c58jd都能满足
另外,如果sql语句是where word like %4c58,那么查询的时候会分割为以下单词:
- 4c5
- c58
- 58
- 8
那么,我们依然能找到字符串为a64c58,但我们匹配不到字符串b4c58jd,因为b4c58jd分割不了单词58和8单词。这也是为什么字符串分割的时候,虽然叫三元语言模型,但头部和尾部都会分割出单字和双字的单词,就是因为要做仅前缀匹配,或仅后缀匹配的模糊匹配。注意,字符串中间是没有分割出单字或者双字的单词。
到最后,我们要认真地思考一下,gin索引这样的匹配结果是精确的吗?例如,where word like %4c58%的查询,是可能被匹配到,“j4c5c58k”这个字符串哦。因为这个字符串的确包含了4c5和c58这两个单词。所以,这样的算法仅仅是一个初步筛选,还需要到原始行里面进行like操作的recheck测试才能得到准确的结果。
11.5.3 二元模型
有了三元模型,我们就有二元,甚至一元模型。例如,对于a64c58字符串,分割为二元模型是这样的:
- a
- a6
- 64
- 4c
- c5
- 58
- 8
一个长度为6的字符串分割为7个单词。显然,一元模型就是分割为6个单词了。
11.5.4 使用场景
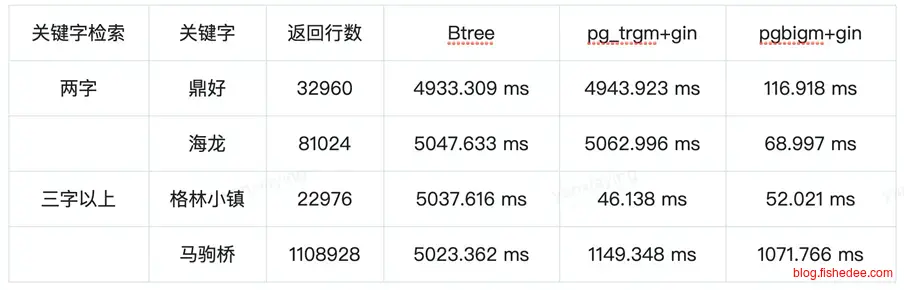
那么,我们究竟选什么模型好呢?
- 三元模型要进行like操作的话,输入的查询操作字符串必须至少为3个字符串的。例如,like %4c%是无法走索引的。同理,二元模型进行like操作的话,输入的查询操作字符串必须至少为2个字符串的。
- 三元模型划分单词是3个字母的,所以最终划分的单词的种类要比二元模型要多得多,查询的时候初筛的精确度就更好,需要recheck的行就越少,查询效率就越高。
- pg_trgm与pg_bigm更多是用在短语匹配上,tsvector更多是用在文章匹配上。
在pg中,三元模型是通过pg_trgm插件提供的,而pg_bigm插件则同时进行一元模型和二元模型的单词划分。所以pg_bigm允许1个字母的模糊查询也能走索引,为了更好地支持任何情况下的短语查询,我们应该使用pg_bigm的插件。
#bigm的操作符
create index idx_title on t_recipe using gin(title gin_bigm_ops);
#trgm的操作符
create index idx_title on t_recipe using gin(title gin_trgm_ops);用法还是比较简单的
11.5.5 trgm的问题
参考资料:
在实践中,我们发现了pg_trgm的两个问题:
- pg_trgm在二字,或者单字匹配的性能很差
- pg_trgm对中文的支持很差,需要在创建database时指定Collate,和ctype。
- pg_trgm对多字符的识别依赖于操作系统的collate实现,在MacOS下无法实现对中文的识别。
db1=# select show_trgm('你好');
show_trgm
-----------
{} show_trgm函数传入中文时,无法有效分割字符
trade_erp=# select count(*) from item;
count
--------
954988
(1 行记录)
trade_erp=# create index on item using gin(name gin_trgm_ops);
CREATE INDEX
trade_erp=# select show_trgm('abc');
show_trgm
-------------------------
{" a"," ab",abc,"bc "}
(1 行记录)
trade_erp=# explain analyse select count(*) from item where name like '%abcd%';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=398.22..398.23 rows=1 width=8) (actual time=0.119..0.119 rows=1 loops=1)
-> Bitmap Heap Scan on item (cost=28.74..397.98 rows=95 width=0) (actual time=0.117..0.117 rows=0 loops=1)
Recheck Cond: ((name)::text ~~ '%abcd%'::text)
Rows Removed by Index Recheck: 12
Heap Blocks: exact=12
-> Bitmap Index Scan on item_name_idx (cost=0.00..28.72 rows=95 width=0) (actual time=0.024..0.024 rows=12 loops=1)
Index Cond: ((name)::text ~~ '%abcd%'::text)
Planning Time: 2.431 ms
Execution Time: 0.145 ms
(9 行记录)
trade_erp=#当正常使用英文字符时,trgm的速度还是可以的,可以看到Bitmap Index Scan on item_name_idx 筛选过后,剩余只有12 rows。
在MacOS下,使用中文字符的话,会演变为Seq筛选
trade_erp=# explain analyse select count(*) from item where name like '%a%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=60226.84..60226.85 rows=1 width=8) (actual time=141.253..144.077 rows=1 loops=1)
-> Gather (cost=60226.62..60226.83 rows=2 width=8) (actual time=140.924..144.072 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=59226.62..59226.63 rows=1 width=8) (actual time=98.737..98.738 rows=1 loops=3)
-> Parallel Seq Scan on item (cost=0.00..59075.90 rows=60290 width=0) (actual time=0.841..97.151 rows=55626 loops=3)
Filter: ((name)::text ~~ '%a%'::text)
Rows Removed by Filter: 262703
Planning Time: 0.103 ms
Execution Time: 144.100 ms
(10 行记录)使用单字筛选的时候,会回退到Seq Scan,无法使用索引
11.5.6 bigm的安装和使用
参考资料:
bigm的麻烦在于,需要自己编译postgresql代码
$ tar zxf postgresql-X.Y.Z.tar.gz
$ cd postgresql-X.Y.Z
$ ./configure --prefix=/opt/pgsql-X.Y.Z
$ make
$ su
# make install
# exit到这里下载源代码,并执行以上代码进行编译,prefix是编译成功后的安装目录
$ tar zxf pg_bigm-x.y-YYYYMMDD.tar.gz
$ cd pg_bigm-x.y-YYYYMMDD
$ make USE_PGXS=1 PG_CONFIG=/opt/pgsql-X.Y.Z/bin/pg_config
$ su
# make USE_PGXS=1 PG_CONFIG=/opt/pgsql-X.Y.Z/bin/pg_config install
# exit到这里下载bigm的源代码,并执行以上代码编译
PATH = $PATH:
PGDATA 创建好postgresql的path位置,以及PGDATA的位置
$ initdb -D $PGDATA --locale=C --encoding=UTF8
$ vi $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_bigm'
$ pg_ctl -D $PGDATA start初始化并启动数据库,后续可以参考[这里]将postgresql在MacOS下设置为自启动。
trade_erp=# select count(*) from item;
count
--------
979722
(1 row)
trade_erp=# select show_bigm('abc');
show_bigm
-------------------
{" a",ab,bc,"c "}
(1 row)
trade_erp=# select show_bigm('你好');
show_bigm
--------------------
{你好,"好 "," 你"}
(1 row)
trade_erp=# explain analyse select count(*) from item where name like '%a%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=32363.49..32363.50 rows=1 width=8) (actual time=47.504..47.985 rows=1 loops=1)
-> Gather (cost=32363.28..32363.49 rows=2 width=8) (actual time=47.430..47.981 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=31363.28..31363.29 rows=1 width=8) (actual time=42.814..42.815 rows=1 loops=3)
-> Parallel Bitmap Heap Scan on item (cost=1788.05..31167.57 rows=78282 width=0) (actual time=32.221..40.410 rows=62927 loops=3)
Recheck Cond: ((name)::text ~~ '%a%'::text)
Heap Blocks: exact=5692
-> Bitmap Index Scan on idx_item_name_filter (cost=0.00..1741.08 rows=187877 width=0) (actual time=33.019..33.019 rows=188782 loops=1)
Index Cond: ((name)::text ~~ '%a%'::text)
Planning Time: 0.172 ms
Execution Time: 48.037 ms
(12 rows)
trade_erp=# explain analyse select count(*) from item where name like '%abc%'; QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=404.96..404.97 rows=1 width=8) (actual time=0.145..0.145 rows=1 loops=1)
-> Bitmap Heap Scan on item (cost=28.76..404.71 rows=98 width=0) (actual time=0.124..0.137 rows=10 loops=1)
Recheck Cond: ((name)::text ~~ '%abc%'::text)
Heap Blocks: exact=6
-> Bitmap Index Scan on idx_item_name_filter (cost=0.00..28.73 rows=98 width=0) (actual time=0.111..0.111 rows=10 loops=1)
Index Cond: ((name)::text ~~ '%abc%'::text)
Planning Time: 0.185 ms
Execution Time: 0.201 ms
(8 rows)
trade_erp=# explain analyse select count(*) from item where name like '%甲基%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=31529.45..31529.46 rows=1 width=8) (actual time=55.812..55.814 rows=1 loops=1)
-> Bitmap Heap Scan on item (cost=1200.24..31208.08 rows=128547 width=0) (actual time=31.264..47.284 rows=181030 loops=1)
Recheck Cond: ((name)::text ~~ '%甲基%'::text)
Heap Blocks: exact=21322
-> Bitmap Index Scan on idx_item_name_filter (cost=0.00..1168.11 rows=128547 width=0) (actual time=27.612..27.613 rows=181030 loops=1)
Index Cond: ((name)::text ~~ '%甲基%'::text)
Planning Time: 0.207 ms
Execution Time: 55.920 ms
(8 rows)可以看到,中文,英文,单字双字全部都是支持的
11.6 全文搜索
11.6.1 英文语境
但是,模糊搜索并没有完全满足实际的问题。例如,我们有句子Mary fought against the dogs alone。我们希望用户在查询fight dog的关键词的时候能找到这个句子。显然,仅用like是无法解决这个问题的。因为:
- fought是fight的过去式,dogs是dog的复数形式,句子中甚至找不到一样的单词
- 在句子中dogs与fought是分开的,不是连续的两个单词。即使用like %fought dogs%是无法找到这个句子的。
pg中使用tsvector和tsquery两个数据类型来解决全文检索的问题。tsvector就是将句子中的单词划分出来,并且进行归一化。tsquery就是将用户输入的单词归一化,并且,允许用户以and或者or的逻辑组合不同的单词条件进行检索。例如,句子”Mary fought against the dogs alone”会转换为tsvector的时候,会划分为以下的单词:
- ‘Mary’:1
- ‘fight’:2
- ‘against’:3
- ‘the’:4
- ‘dog’:5
- ‘alone’:6
在划分的时候,tsvector中的每个单词都会归一化为原始的形式,并且会记录它在句子中出现的位置。那么tsquery对”fight dog”这个搜索语,会划分为以下的条件
- ‘fight’ & ‘dog’
显然,这个条件就是寻找句子中,同时包含这两个单词的句子
# 按照english的配置对句子分词和归一化
select to_tsvector('english','Mary fought against the dogs alone');
# 按照english的配置对query句子拆分,两个单词同时存在
select to_tsquery('english','fight & dog');
# 按照english的配置对query句子拆分,两个单词任意存在
select to_tsquery('english','fight | dog');
# 按照english的配置对query句子拆分,两个单词相邻存在
select to_tsquery('english','fight <;->; dog');
#默认使用&连接
select plainto_tsquery('english','fight dog');
#默认使用<;->;连接
select phraseto_tsquery('english','fight dog');
# 检查句子和查询条件的匹配性
select to_tsvector('english','Mary fought against the dogs alone') @@ to_tsquery('english','fight&dog');tsvector与tsquery是内建的类型,我们可以通过to_tsvector对不同语境的句子划分单词,和归一化,统一转换到tsvector类型。同理,to_tsquery也是将查询条件划分,同时指定不同单词的条件,甚至是优先级
11.6.2 中文语境
中文的全文检索与英文有所不同:
- 中文句子没有以空格分开的单词,需要自己找出单词的边界
- 单词不需要归一化
- 单词可以由多个单词组成,例如,“清华大学”就是一个单词,但是“清华”和“单词”也可以看成两个单词。我们希望“清华大学和北京大学是国内最好的两所大学”这个句子,搜索“清华大学”或“清华”都应该能被匹配到。
select to_tsvector('zhparser','保障房资金压力')由于有了tsvector的帮助,我们仅仅需要提供一个中文的分词配置就能支持到中文的全文检索,它就是zhparser。但是,第三个问题怎么解决呢?
解决方法就是,对单词进一步进行分割。例如“清华大学和北京大学是两所大学”这个句子,普通分割方式为:
- 清华大学
- 和
- 北京大学
- 两
- 所
- 大学
对短语中的单词进一步分割,得到新的分割方式为:
- 清华大学
- 和
- 北京大学
- 两
- 所
- 大学
- 清华
- 北京
这样,我们搜索“清华大学”或者“清华”单词都能匹配到这个句子了。这个思路就是允许分词是冗余的,以支持不同的检索场景。zhparser支持以下的配置,实现不同粒度的复合单词。
- zhparser.multi_short,单词中的短单词进行分割
- zhparser.multi_duality,任意二字都组成单词
- zhparser.multi_zmain,重要单字
- zhparser.multi_zall,全部单字
常见的场景下的配置:
- 对象是标题或者名字,那么就以单字作为分词
- 对象是文章,普通分词,再加上multi_short就可以了
- 对象是聊天记录,普通分词,加multi_short,加multi_duality,加multi_zall,保证单字和双字,以及任意的单词都能查找得到。你可以试试微信的聊天记录全文检索,就是用的这种方式。
11.6.3 索引
#建立gin上面的函数索引
CREATE INDEX pgweb_idx ON pgweb USING GIN(to_tsvector('zhparser', body));
#建立物理列上的索引,并且加入触发器自动更新
ALTER TABLE pgweb ADD COLUMN textsearchable_index_col tsvector;
UPDATE pgweb SET textsearchable_index_col = to_tsvector('zhparser', body);
CREATE INDEX textsearch_idx ON pgweb USING GIN(textsearchable_index_col);
#将body列(或者多列组合)进行zhparser分词后存入textsearchable_index_col列中
CREATE TRIGGER tsvectorupdate
BEFORE UPDATE OR INSERT ON pgweb
FOR EACH ROW EXECUTE PROCEDURE tsvector_update_trigger('textsearchable_index_col', 'zhparser', 'body');在gin上建立全文索引有两种方法:
- 函数索引,查询慢一点,因为gin返回的都是bitmap index scan,不是具体的行。所以在索引匹配以后,还要到原始的行里面进行一次recheck,重新分词后匹配。注意,查询的时候,where条件要与函数形式完全一样才能走索引。好处是,不需要考虑更新问题。
- 物化列索引,插入或更新的时候用触发器更新,在原始行recheck的时候不需要重新分词,查询速度要快一点
最后,开发也可以选择第三种办法,自己在程序进行分词,绕过to_tsvector,直接生成tsvector存入到数据库中,这样是最灵活的,可以支持各种不同的检索场景,并且用不同的分词程序。
11.7 FDW
fdw是管理外部数据的扩展标准,可以在pg中以sql的形式操作Oracle,MySql,MongoDB等各种数据源
11.7.1 安装mysql_fdw
ln -s /usr/local/mysql/lib/libmysqlclient.dylib /usr/lib/libmysqlclient.dylib将mysqlclient的库放入/usr/lib下面
git clone https://github.com/EnterpriseDB/mysql_fdw.git
make USE_PGXS=1
make USE_PGXS=1 install编译后即可完成安装
11.7.2 读写外部mysql_fdw
CREATE EXTENSION mysql_fdw;
CREATE SERVER mysql_server
FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host '127.0.0.1', port '3306');
CREATE USER MAPPING FOR fish
SERVER mysql_server
OPTIONS (username 'root', password '1');
CREATE FOREIGN TABLE t_user(
userId int,
name varchar(32),
age int,
money numeric(14,2),
loginTime timestamp,
createTime timestamp,
modifyTime timestamp
)
SERVER mysql_server
OPTIONS (dbname 'Test', table_name 't_user');
insert into t_user(name,age,money,loginTime,createTime,modifyTime) values('fish',11,'12.0',now(),now(),now());
select * from t_user;
explain select * from t_user;将mysql的Test数据库下的t_user表,映射到本地的t_user表。
#全表映射
CREATE EXTENSION mysql_fdw;
CREATE SERVER mysql_server
FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host '127.0.0.1', port '3306');
CREATE USER MAPPING FOR postgres
SERVER mysql_server
OPTIONS (username 'root', password '1');
create schema mysql_yinghao;
import FOREIGN SCHEMA Yinghao from server mysql_server into mysql_yinghao;
#逐个复制远程表到本地表
create table t_user (like mysql_yinghao.t_user);
insert into t_user select * from mysql_yinghao.t_user;将mysql的整个数据库Yinghao映射到本地的Schema的mysql_yinghao上,之后就能简单地用mysql_yinghao.xxx来引用外部表。同时用create table like操作将远程表数据复制到本地表,操作相当方便可靠
12 优化
12.1 操作系统优化
blockdev --getra /dev/sdf
blockdev --settra 4096 /dev/sdf调整块设备的预读扇区,默认为256个扇区,即128KB。可以调整为4096个扇区,即2MB。这样能加快全表扫描的速度
#查看虚拟内存的置换比例
cat /proc/sys/vm/swappiness
#打开文件,修改置换比例为0,即尽可能使用物理内存,不用swap空间
vim /etc/sysctl.conf
vm.swappiness = 0
#生效
sysctl -p设置虚拟内存的置换比例
# 查看物理和Swap空间的大小
free -m
# malloc的分配大小策略
vm.overcommit_memory = 2
vm.overcommit_ratio = N设置malloc分配内存的时候,不允许进行Overcommit,大小为Swap空间大小+overcommit_ratio%*物理内存大小。
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10文件系统的脏页达到系统内存的dirty_background_ratio百分比时触发异步写入磁盘,达到dirty_ratio百分比时不得不同步写入磁盘。一般来说,内存越大,数值就要越少,避免批量磁盘,导致进程堵塞。
12.2 监控信息
| 表名 | 作用 |
|---|---|
| pg_stat_activity | 正在运行的连接信息 |
| pg_stat_database | 数据库级别的行和扫描信息 |
| pg_stat_user_tables | 用户表级别的行和扫描信息 |
| pg_stat_user_indexes | 用户索引级别的行和扫描信息 |
| pg_statio_user_tables | 用户表级别的缓冲区信息 |
| pg_statio_user_indexes | 用户索引级别的缓冲区信息 |
12.3 数据库配置优化
内存配置优化:
- shared_buffer,共享缓冲区大小,推荐为内存的1/4,不超过1/2。
- temp_buffers,进程内的临时表大小,10MB就足够了
- work_mem,进程内的单独内存,用于排序和hash操作,不需要太大,10MB就足够了
- maintence_work_mem,进程内的单独内存,用于索引和vacuum等的维护操作,不需要太大,10MB就足够了
页表大小:
cat /proc/meminfo | grep PageTables正常情况是几十MB的,如果达到1GB以上就正面有问题了。因为shared_buffers设置比较大时,各个进程要有一个页表映射到shared_buffers,shared_buffers过大,页表就会相应占用过大的物理内存。解决办法是将页面从每4KB需要8字节指针,改为每2MB需要8字节指针,这样分配页表粒度更大,但页表自身内存更小。
# 可以设置为on,但是大页启动失败时,pg启动也会失败
huge_pages = try
# 设置操作系统的大页内存
vim /etc/sysctl.conf
vm.nr_hugpages = 10240
sysctl -p
cat /proc/sys/vm/nr_hugpages设置大页表的方式
13 RLS
代码在这里
参考资料:
13.1 创建表
drop schema public cascade;
create schema public;
drop user t1;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO public;
set search_path to public;
create table config(
id bigint not null,
name varchar(64) not null,
value varchar(64) not null,
primary key(id)
);
insert into config(id,name,value)values
(1,'maxOperator','13'),
(2,'maxDiskSpace','1GB');
create table operator(
id bigint not null,
tenant_id bigint not null,
name varchar(64) not null,
primary key(id)
);
alter table operator add constraint name_unique unique(name,tenant_id) deferrable initially deferred ;
insert into operator(id,tenant_id,name)values
(1,10001,'fish'),
(2,10001,'fish2'),
(3,10002,'fish'),
(4,10002,'fish2');创建表比较简单
13.2 行级策略配置
/*user表启用row level*/
alter table operator enable row level security;
/*DROP POLICY policy_name ON table_name;*/
CREATE POLICY tenant_isolation_policy ON operator
for all
USING (tenant_id = current_setting('app.tenant_id')::int);
ALTER TABLE operator ALTER COLUMN tenant_id SET DEFAULT current_setting('app.tenant_id')::int;
/*查看policy*/
SELECT * FROM pg_policies;
/* create user*/
create user t1 with password '123';
GRANT ALL ON SCHEMA public TO t1;
GRANT ALL on ALL TABLES in SCHEMA public to t1;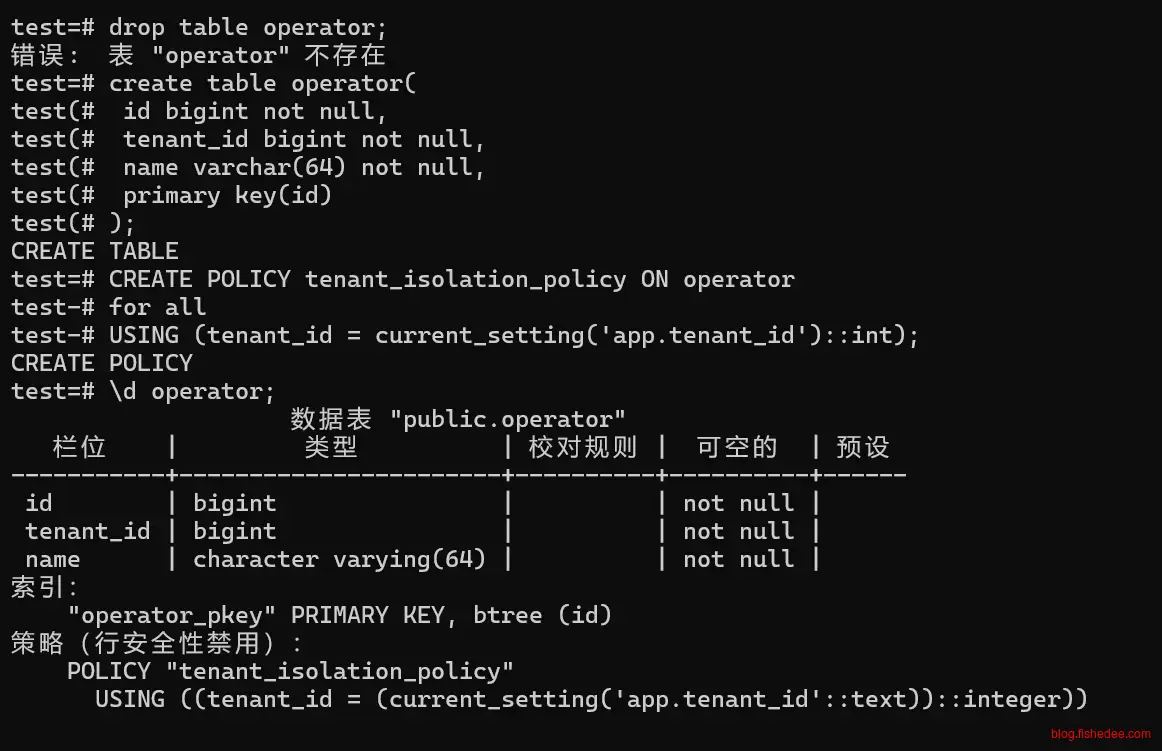
打开行级策略需要三点:
- 表要打开row level security,没打开的时候able会显示”行安全性禁用”
- 表要增加POLICY,指定筛选用tenant_id和配置匹配
- 表的tenant_id字段设置默认值,这样在增删改查数据的时候都不需要传入tenant_id。
最后,重要的一点:
- 超级用户, owner用户, bypassrls用户都无法使用RLS权限筛选,需要使用普通的用户来做RLS筛选
13.3 测试
/*测试*/
SET app.tenant_id = 10001;
show app.tenant_id;
select * from operator;
insert into operator(id,name)values
(6,'fish6');
/*dupliate name fish*/
insert into operator(id,name)values
(7,'fish');
update operator set name = 'fish22' where id = 2;
delete from operator where id = 1;
select * from operator;
select * from config;
update config set value = '10GB' where name = 'maxDiskSpace';
/*测试2*/
SET app.tenant_id = 10002;
/*can not delete data of other tenant*/
delete from operator where id = 2;
/*can not update data of other tenant*/
update operator set name = 'fish222' where id = 2;
/*can add date with the same name of other tenant*/
insert into operator(id,name)values
(8,'fish6');
select * from operator;
select * from config;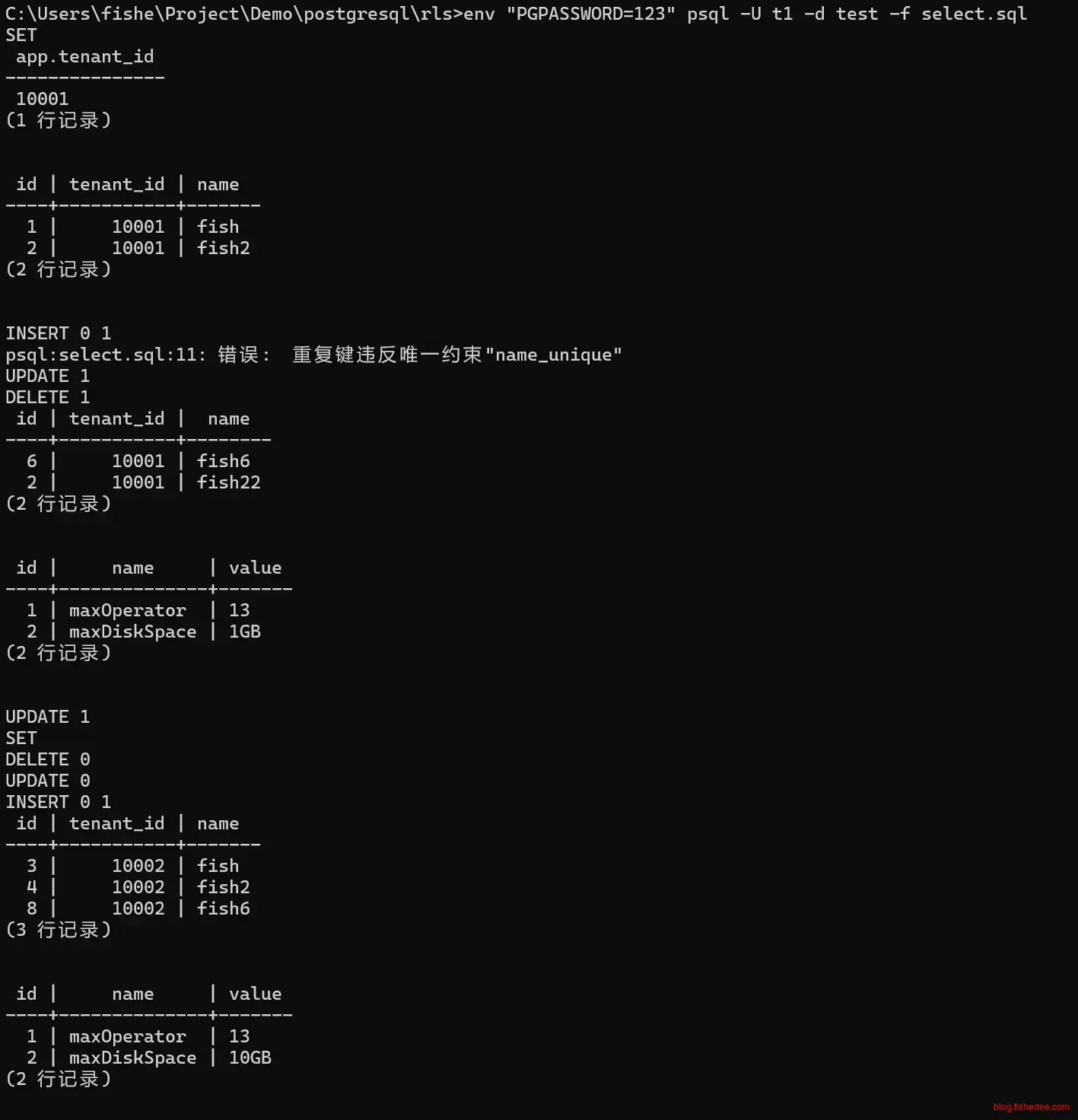
可以看到轻松地实现了根据不同用户来进行RLS筛选
14 分区
表分区相当重要,特别在单表行数很多的情况下,Pg 11以后提供了声明式分区的方法,分区维护变得简单多了
参考资料:
14.1 测试
drop schema public cascade;
create schema public;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO public;
set search_path to public;
/*https://zhuanlan.zhihu.com/p/690917866*/
create table student(
id bigint not null,
tenant_id integer not null,
name varchar(100) not null,
/*must have id and partition id*/
primary key(tenant_id,id)
) partition by range(tenant_id);
CREATE TABLE student_10 PARTITION OF student
FOR VALUES FROM (0) TO (10);
CREATE TABLE student_20 PARTITION OF student
FOR VALUES FROM (10) TO (20);
/*default partition*/
CREATE TABLE student_default PARTITION OF student default;
CREATE INDEX ON student (name);
insert into student(id,tenant_id,name)values
(1,1,'fish1'),
(2,1,'fish2'),
(3,2,'fish3'),
(4,2,'fish4'),
(5,11,'fish5'),
(6,11,'fish6'),
(7,12,'fish7'),
(8,12,'fish8'),
(9,103,'fish9'),
(10,103,'fish10');
select * from student;
select * from student_10;
select * from student_20;
select * from student_default;
/* add column*/
alter table student add column age integer not null default 0;
CREATE UNIQUE INDEX student_name ON student(tenant_id,name);
/* duplicate name*/
insert into student(id,tenant_id,name,age)values
(7,1,'fish1',10);
/* global index */
create index student_name2 on student(name);
/* change to only 2 partition*/
ALTER TABLE student DETACH PARTITION student_10;
ALTER TABLE student DETACH PARTITION student_20;
CREATE TABLE student_1 PARTITION OF student
FOR VALUES FROM (0) TO (2);
CREATE TABLE student_2 PARTITION OF student
FOR VALUES FROM (2) TO (20);
INSERT INTO student SELECT * FROM student_10;
INSERT INTO student SELECT * FROM student_20;
drop table student_10;
drop table student_20;
select * from student;
\d+ student;
/*https://zhuanlan.zhihu.com/p/117275290*/
/*https://developer.aliyun.com/article/590356*/
show enable_partition_pruning ;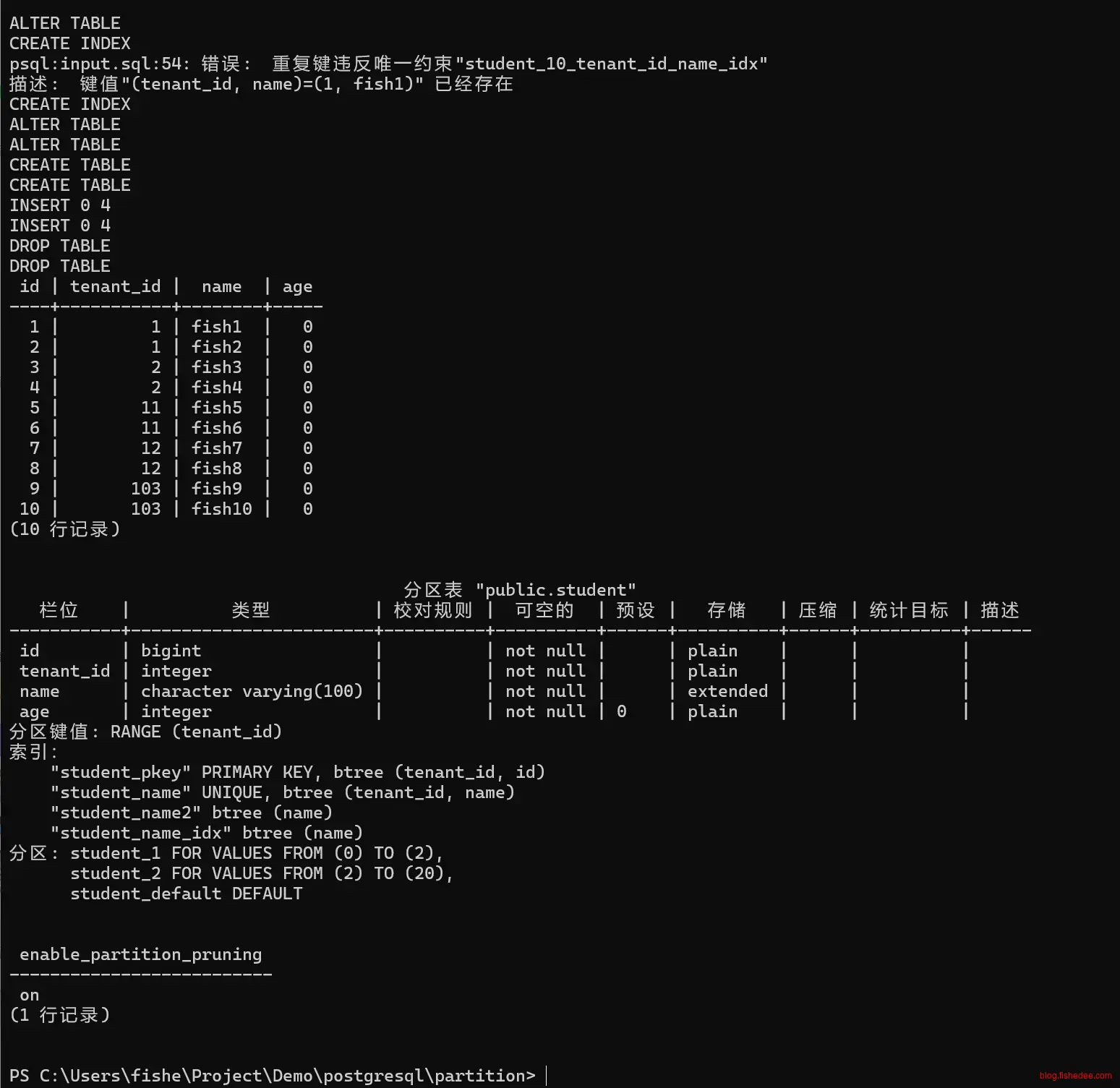
要点:
- 创建表使用partition by range(tenant_id),注意,主键必须要包含分区键
- 单独创建每个分区和默认分区,CREATE TABLE student_10 PARTITION OF student FOR VALUES FROM (0) TO (10);
- alter table DETACH/ATTACH来维护分区
14.2 分区索引
drop schema public cascade;
create schema public;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO public;
set search_path to public;
CREATE TABLE student (
id BIGINT NOT NULL,
tenant_id INTEGER NOT NULL,
age integer not null,
name VARCHAR(100) NOT NULL,
money integer not null,
PRIMARY KEY (tenant_id, id)
) PARTITION BY HASH (tenant_id);
CREATE OR REPLACE FUNCTION create_tenant_partitions(p_table_name TEXT, hash_count INTEGER)
RETURNS VOID AS $$
DECLARE
v_partition_name TEXT;
v_sql TEXT;
BEGIN
FOR i IN 0..(hash_count-1) LOOP
v_partition_name := format('%s_%s', p_table_name, i);
v_sql := format('CREATE TABLE %s PARTITION OF %s FOR VALUES WITH (MODULUS %s, REMAINDER %s);',
v_partition_name,
p_table_name,
hash_count,
i);
EXECUTE v_sql;
END LOOP;
END;
$$ LANGUAGE plpgsql;
select create_tenant_partitions('student',10);
INSERT INTO student (id, tenant_id,age,money, name)
SELECT
g.id,
(g.id % 1001) AS tenant_id, -- 确保 tenant_id 在 0 到 1000 之间
g.id % 120,
g.id % 1000,
'Student' || (g.id % 1000) AS name -- 随机生成名字
FROM generate_series(1, 100000) AS g(id);创建初始数据
-- 情况1:
-- 分区索引,有分区键。没有global关键字,每个分区上都有一个对应的索引匹配
create index student_age on student(tenant_id,age) ;
-- 无分区键的时候,会对每个子表进行seq筛选
explain select * from student where age = 10;
-- 有分区键的时候,直接走单个索引,student_7_tenant_id_age_idx
explain select * from student where age = 10 and tenant_id = 20;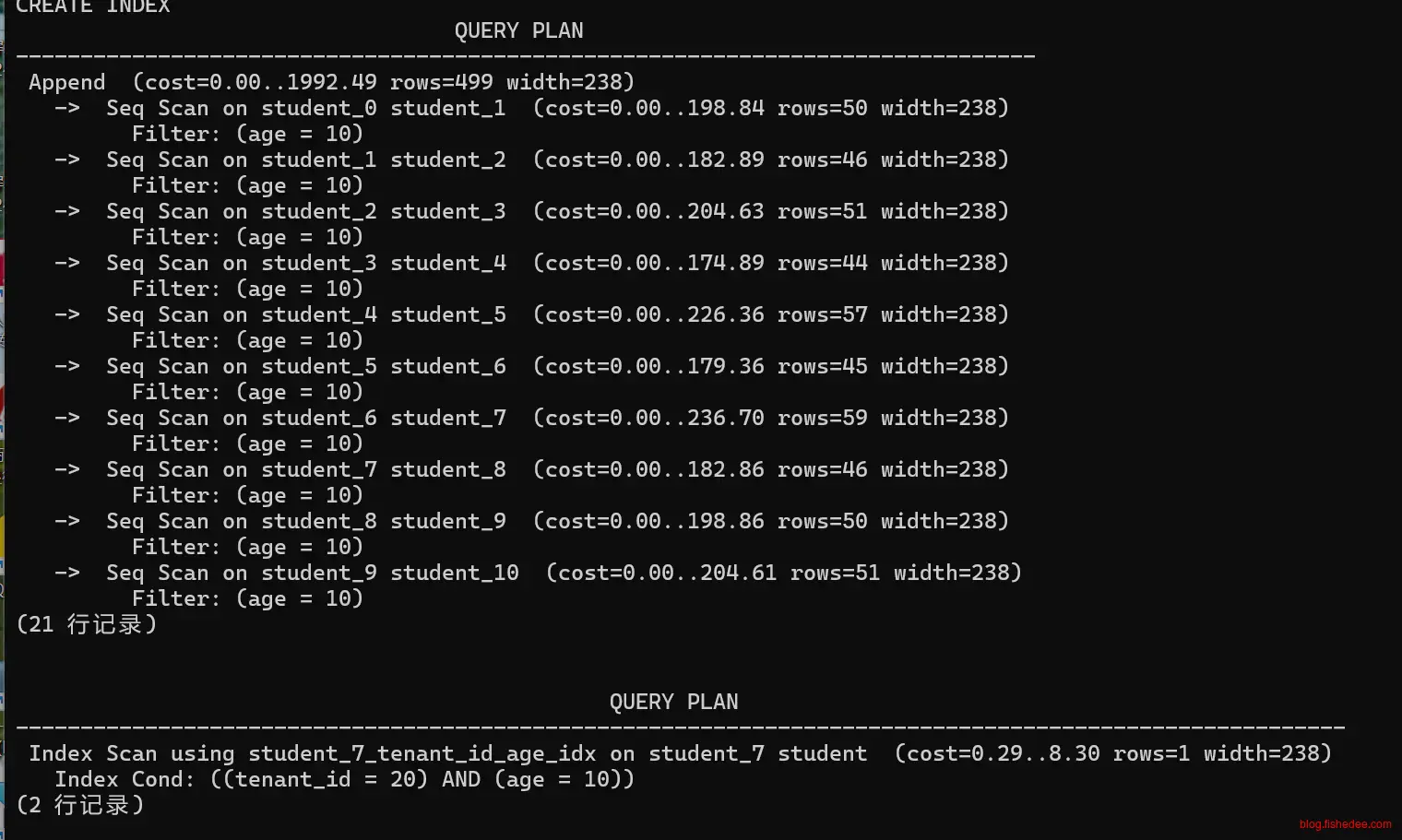
Postgresql的分区索引,有分区键的时候,每个分区上都有一个对应的索引匹配。
-- 情况2:
-- 分区索引,没有分区键,没有global关键字,每个分区上都有一个对应的索引匹配
create index student_money on student(money) ;
-- 无分区键的时候,会对所有的索引进行Bitmap Index Scan
explain select * from student where money = 20;
-- 有分区键的时候,直接走单个索引,student_7_money_idx
explain select * from student where money = 30 and tenant_id = 20;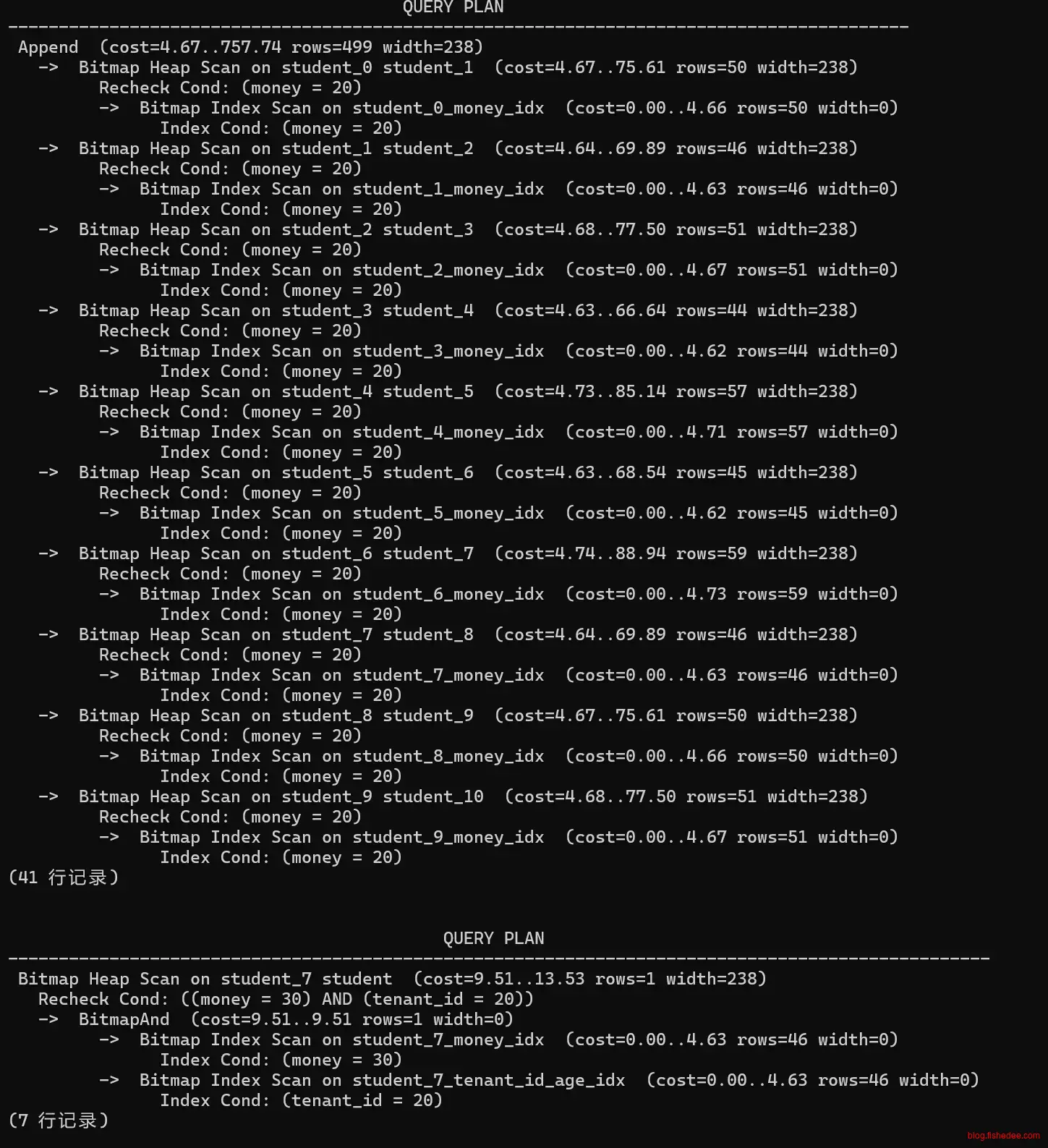
Postgresql的分区索引,没有分区键的时候,每个分区上依然有一个对应的索引匹配。
-- 情况3:
-- Postgresql上不支持使用global index,索引都是与每个表对应的。以下操作会报错
-- 错误: unique constraint on partitioned table must include all partitioning columns
-- 描述: 表"student"上的约束UNIQUE缺少列"tenant_id",该列是分区键的一部分.
create unique index student_name on student(name);PostgreSql 16上依然没有提供全局索引,所以创建跨多个分区的unique index的时候会失败
14.3 全局索引
PostgreSql 16上依然没有提供全局索引,所以创建跨多个分区的unique index的时候会失败。我们可以采用trigger + 新表来模拟全局索引。
drop schema public cascade;
create schema public;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO public;
set search_path to public;
CREATE TABLE student (
id BIGINT NOT NULL,
tenant_id INTEGER NOT NULL,
name VARCHAR(100) NOT NULL,
PRIMARY KEY (tenant_id, id)
) PARTITION BY HASH (tenant_id);
CREATE OR REPLACE FUNCTION create_tenant_partitions(p_table_name TEXT, hash_count INTEGER)
RETURNS VOID AS $$
DECLARE
v_partition_name TEXT;
v_sql TEXT;
BEGIN
FOR i IN 0..(hash_count-1) LOOP
v_partition_name := format('%s_%s', p_table_name, i);
v_sql := format('CREATE TABLE %s PARTITION OF %s FOR VALUES WITH (MODULUS %s, REMAINDER %s);',
v_partition_name,
p_table_name,
hash_count,
i);
EXECUTE v_sql;
END LOOP;
END;
$$ LANGUAGE plpgsql;
select create_tenant_partitions('student',10);
-- 情况4:
-- 使用trigger来模拟实现global index
create table student_name(
id BIGINT not null,
name VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
);
ALTER TABLE student_name add constraint student_name_unique unique(name) DEFERRABLE INITIALLY DEFERRED;
create or replace function student_unique_name()
returns trigger as $$
declare
rows smallint;
begin
-- del old data
if tg_op in ('DELETE', 'UPDATE') then
delete from student_name
where id = old.id and name=old.name ;
get diagnostics rows = row_count;
if rows != 1 then
raise '% affected % rows (expected: 1)',tg_op, rows;
end if;
end if;
-- add new data
if tg_op in ('INSERT', 'UPDATE') then
insert into student_name (id,name)
values (new.id, new.name);
get diagnostics rows = row_count;
if rows != 1 then
raise '% affected % rows (expected: 1)',tg_op, rows;
end if;
end if;
return new;
end;
$$ language plpgsql;
create trigger student_unique_name
after delete or insert or update of id, name
on student for each row
execute function student_unique_name();
-- 初始数据
begin transaction;
delete from student_name;
insert into student_name select id, name from student;
end;
-- 测试数据
begin transaction;
insert into student(id,tenant_id,name)values
(1,10001,'fish'),
(2,10002,'cat'),
(3,10003,'dog');
select * from student_name;
update student set name = 'cat2' where id = 2;
update student set name = 'fish1',id = 4 where id = 1;
delete from student where id = 3;
select * from student_name;
end;
-- 测试冲突
begin transaction;
delete from student;
insert into student(id,tenant_id,name)values
(1,10001,'fish'),
(2,10002,'cat'),
(3,10003,'dog');
update student set name = 'fish' where id = 2;
select 'try commit!';
end;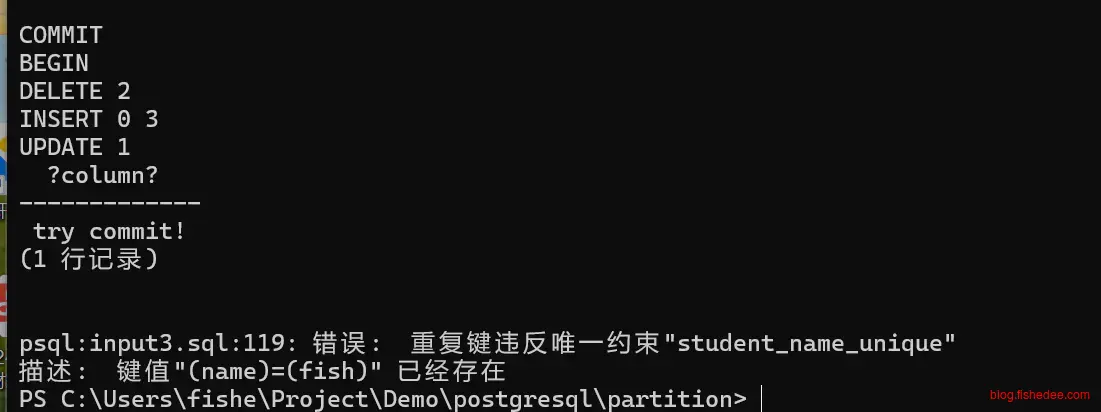
commit的时候进行unique index校验,总体代码比较简单
14.4 参数优化
set show enable_partition_pruning = on;
show enable_partition_pruning ;
开启enable_partition_pruning以后,select/update/insert/delete都只会在单独的分区表上执行。explain可以看到subplans removed。
set show enable_partition_pruning = off;
show enable_partition_pruning ;
没有开启enable_partition_pruning的时候,它会在逐个分区上执行sql,显然性能要差很多了
15 Saas多租户选型
参考资料:
- Implementing managed PostgreSQL for multi-tenant SaaS applications on AWS
- 大分区表高并发性能提升100倍?阿里云 RDS PostgreSQL 12 解读
15.1 选型
Postgresql下有三种Saas多租户的数据隔离实现方式:
- RLS + 单表,所有租户都放在单表下,使用RLS来隔离
- RLS + 分区表,每个表划分多个分区,每个分区下存放多个租户,这样能同时兼顾性能和隔离性。
- Schema,使用Schema来完全隔离租户,每个租户都是单独的Schema,单独的表。这样的隔离性较好,但是表的数量会多很多。
15.2 SQL性能
15.2.1 背景
cc=> select count(*) from unified_order_item;
count
--------
122933
(1 行记录)
trade_erp=# select count(*) from unified_order_item;
count
--------
169981
(1 行记录)测试租户的unified_order_item共122933行,所有租户合起来共169981行。
- RLS + 单表会将所有租户都放在一个表中
- RLS + 分区,将测试租户放入单独的分区中,其他的租户放入default分区,一共只有2个分区。
- Schema,测试租户单独一个Schema,其他租户都有自己独立的Schema
explain analyse select uorder_item.id as "id" , uorder.id as "orderId" , uorder.number as "orderNumber" , uorder.parent_source_order_info as "parentSourceOrderInfo" , uorder.undone_execute_amount as "orderUndoneExecuteAmount" , uorder.has_stock_execute as "orderHasStockExecute" , uorder.contact_id as "orderContactId" , uorder.in_store_id as "orderInStoreId" , uorder.out_store_id as "orderOutStoreId" , uorder.manage_employee_id as "orderManageEmployeeId" , uorder_item.order_date as "orderDate" , uorder.total_amount as "orderTotalAmount" , uorder.total as "orderTotal" , uorder.remark as "orderRemark" , uorder.summary_remark as "orderSummaryRemark" , uorder.draw_employee_id as "orderDrawEmployeeId" , uorder.draw_time as "orderDrawTime" , uorder.entry_account_employee_id as "orderEntryAccountEmployeeId" , uorder.entry_account_time as "orderEntryAccountTime" , uorder.attachment_count as "attachmentCount" , uorder.attachment_size as "attachmentSize" , uorder.type as "orderType" , uorder.custom_field1 as "orderCustomField1" , uorder.custom_field2 as "orderCustomField2" , uorder.custom_field3 as "orderCustomField3" , uorder.custom_field4 as "orderCustomField4" , uorder.custom_field5 as "orderCustomField5" , uorder.custom_field6 as "orderCustomField6" , uorder.custom_field7 as "orderCustomField7" , uorder.custom_field8 as "orderCustomField8" , uorder_item.order_state as "orderState" , uorder_item.order_red_state as "orderRedState" , uorder_item.item_id as "itemId" , item.number as "itemNumber" , item.name as "itemName" , item.image1 as "image1" , uorder_item.unit_id as "unitId" , uorder_item.store_id as "itemStoreId" , uorder_item.amount as "amount" , uorder_item.done_execute_amount as "doneExecuteAmount" , uorder_item.undone_execute_amount as "undoneExecuteAmount" , item.common_unit_name as "commonUnitName" , round(uorder_item.basic_amount*uorder_item.order_direction/item.common_unit_convert,2) as "commonAmount" , uorder_item.basic_amount as "basicAmount" , uorder_item.cost_price as "costPrice" , uorder_item.price as "price" , uorder_item.discount_price as "discountPrice" , uorder_item.pre_tax_price as "preTaxPrice" , uorder_item.tax as "tax" , uorder_item.total*uorder_item.order_direction as "total" , uorder_item.pre_tax_total*uorder_item.order_direction as "preTaxTotal" , uorder_item.discount_total*uorder_item.order_direction as "discountTotal" , uorder_item.cost_total*uorder_item.order_direction as "costTotal" , uorder_item.profit_total as "profitTotal" , uorder_item.profit_rate as "profitRate" , uorder_item.remark as "remark" , uorder_item.custom_field1 as "customField1" , uorder_item.custom_field2 as "customField2" , uorder_item.custom_field3 as "customField3" , uorder_item.custom_field4 as "customField4" , uorder_item.custom_field5 as "customField5" , uorder_item.custom_field6 as "customField6" , uorder_item.custom_field7 as "customField7" , uorder_item.custom_field8 as "customField8" , uorder_item.stock_location as "stockLocation" , uorder_item.items_order as "itemsOrder" from unified_order_item as uorder_item left join unified_order as uorder on uorder_item.order_id = uorder.id left join item on uorder_item.item_id = item.id where uorder_item.order_date >;= '2024-05-01' and uorder_item.order_date <;= '2024-05-31' and uorder_item.order_type in ('SALES_OUT','SALES_RETURN') and uorder_item.order_state = 'ENTRY_ACCOUNT' and uorder_item.order_red_state = 'NORMAL' and uorder_item.order_stock_type = uorder.item_stock_type and uorder_item.basic_amount != 0 order by uorder_item.order_date asc ,uorder.id asc ,uorder_item.items_order asc limit 50 offset 0;第一条sql是测试数据分页,测试条件比较多,而且是三个表一起join。
explain analyse select count(*) as "count" , count(distinct uorder.id) as "orderCount" , count(distinct uorder.id) filter (where (uorder.type = 'SALES_RETURN' or uorder.type = 'PURCHASE_RETURN') and uorder.state != 'DRAFT') as "returnOrderCount" , count(distinct uorder.id) filter (where (uorder.type != 'SALES_RETURN' and uorder.type != 'PURCHASE_RETURN') and uorder.state != 'DRAFT') as "normalOrderCount" , count(distinct uorder.id) filter (where uorder.state = 'DRAFT') as "draftOrderCount" , coalesce(sum(uorder_item.amount),0) as "amount" , coalesce(sum(uorder_item.done_execute_amount),0) as "doneExecuteAmount" , coalesce(sum(uorder_item.undone_execute_amount),0) as "undoneExecuteAmount" , coalesce(sum(uorder_item.basic_amount*uorder_item.order_direction/item.common_unit_convert),0) as "commonAmount" , coalesce(sum(uorder_item.total*uorder_item.order_direction),0) as "total" , coalesce(sum(uorder_item.pre_tax_total*uorder_item.order_direction),0) as "preTaxTotal" , coalesce(sum(uorder_item.discount_total*uorder_item.order_direction),0) as "discountTotal" , coalesce(sum(uorder_item.fee_total*uorder_item.order_direction),0) as "feeTotal" , coalesce(sum(uorder_item.cost_total*uorder_item.order_direction),0) as "costTotal" , coalesce(sum(uorder_item.profit_total),0) as "profitTotal" from unified_order_item as uorder_item left join unified_order as uorder on uorder_item.order_id = uorder.id left join item on uorder_item.item_id = item.id where uorder_item.order_date >;= '2024-05-01' and uorder_item.order_date <;= '2024-05-31' and uorder_item.order_type in ('SALES_OUT','SALES_RETURN') and uorder_item.order_state = 'ENTRY_ACCOUNT' and uorder_item.order_red_state = 'NORMAL' and uorder_item.order_stock_type = uorder.item_stock_type and uorder_item.basic_amount != 0;第一条sql是测试数据聚合,测试条件比较多,而且是三个表一起join。
15.2.2 RLS + 单表
Limit (cost=44.86..2231.09 rows=50 width=567) (actual time=0.813..0.817 rows=50 loops=1)
->; Incremental Sort (cost=44.86..12856.21 rows=293 width=567) (actual time=0.813..0.814 rows=50 loops=1)
Sort Key: uorder_item.order_date, uorder.id, uorder_item.items_order
Presorted Key: uorder_item.order_date
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 58kB Peak Memory: 58kB
Pre-sorted Groups: 1 Sort Method: quicksort Average Memory: 70kB Peak Memory: 70kB
->; Nested Loop Left Join (cost=1.02..12843.03 rows=293 width=567) (actual time=0.055..0.522 rows=90 loops=1)
->; Nested Loop (cost=0.73..12489.13 rows=293 width=396) (actual time=0.043..0.283 rows=90 loops=1)
->; Index Scan using unified_order_item_tenant_id_order_date_idx on unified_order_item uorder_item (cost=0.30..6409.22 rows=1014 width=135) (actual time=0.033..0.105 rows=90 loops=1)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date))
Filter: (((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text) AND (basic_amount <;>; '0'::numeric))
Rows Removed by Filter: 49
->; Index Scan using unified_order_pkey1 on unified_order uorder (cost=0.42..5.99 rows=1 width=269) (actual time=0.001..0.001 rows=1 loops=90)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.order_id))
Filter: (uorder_item.order_stock_type = item_stock_type)
->; Index Scan using item_pkey1 on item (cost=0.29..1.18 rows=1 width=45) (actual time=0.001..0.001 rows=1 loops=90)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.item_id))
Planning Time: 0.454 ms
Execution Time: 0.902 ms
(19 行记录)第一条SQL仅0.902 ms,很奇怪,快得不像是对的。可能是使用了Incremental Sort。
Aggregate (cost=29.78..29.79 rows=1 width=360) (actual time=13.647..13.648 rows=1 loops=1)
->; Nested Loop Left Join (cost=1.14..29.67 rows=1 width=258) (actual time=0.045..11.714 rows=1710 loops=1)
->; Nested Loop (cost=0.85..21.35 rows=1 width=257) (actual time=0.039..9.677 rows=1710 loops=1)
->; Index Scan using unified_order_item_tenant_id_order_type_order_state_order_r_idx on unified_order_item uorder_item (cost=0.43..12.89 rows=1 width=232) (actual time=0.029..6.663 rows=1710 loops=1)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND ((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
Filter: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date) AND (basic_amount <;>; '0'::numeric))
Rows Removed by Filter: 25109
->; Index Scan using unified_order_pkey1 on unified_order uorder (cost=0.42..8.45 rows=1 width=33) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.order_id))
Filter: (uorder_item.order_stock_type = item_stock_type)
->; Index Scan using item_pkey1 on item (cost=0.29..8.31 rows=1 width=9) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.item_id))
Planning Time: 0.335 ms
Execution Time: 13.747 ms
(14 行记录)第二条SQL是13.747 ms,速度也是可以的。
15.2.3 RLS + 分区表
Limit (cost=79.28..79.28 rows=1 width=11696) (actual time=15.279..15.283 rows=50 loops=1)
->; Sort (cost=79.28..79.28 rows=1 width=11696) (actual time=15.278..15.280 rows=50 loops=1)
Sort Key: uorder_item.order_date, uorder.id, uorder_item.items_order
Sort Method: top-N heapsort Memory: 58kB
->; Nested Loop Left Join (cost=1.01..79.27 rows=1 width=11696) (actual time=0.039..14.139 rows=1710 loops=1)
->; Nested Loop (cost=0.72..62.59 rows=1 width=11042) (actual time=0.029..10.342 rows=1710 loops=1)
->; Append (cost=0.42..21.23 rows=2 width=5444) (actual time=0.021..7.164 rows=1710 loops=1)
Subplans Removed: 1
->; Index Scan using unified_order_item_10001_tenant_id_order_type_order_state_o_idx on unified_order_item_10001 uorder_item_1 (cost=0.42..12.89 rows=1 width=5444) (actual time=0.021..7.097 rows=1710 loops=1)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND ((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
Filter: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date) AND (basic_amount <;>; '0'::numeric))
Rows Removed by Filter: 25109
->; Append (cost=0.30..20.66 rows=2 width=5606) (actual time=0.001..0.002 rows=1 loops=1710)
Subplans Removed: 1
->; Index Scan using unified_order_10001_pkey on unified_order_10001 uorder_1 (cost=0.30..8.32 rows=1 width=5606) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.order_id)) Filter: (uorder_item.order_stock_type = item_stock_type)
->; Append (cost=0.29..16.63 rows=2 width=610) (actual time=0.001..0.001 rows=1 loops=1710)
Subplans Removed: 1
->; Index Scan using item_10001_pkey on item_10001 item_1 (cost=0.29..8.31 rows=1 width=610) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.item_id))
Planning Time: 0.775 ms
Execution Time: 15.376 ms
(23 行记录)第一条SQL是15.376 ms,速度较慢,没有Incremental Sort,多了Subplans Removed
Aggregate (cost=79.35..79.36 rows=1 width=360) (actual time=34.359..34.360 rows=1 loops=1)
->; Nested Loop Left Join (cost=1.01..79.24 rows=1 width=540) (actual time=0.137..32.492 rows=1710 loops=1)
->; Nested Loop (cost=0.72..62.59 rows=1 width=522) (actual time=0.103..29.439 rows=1710 loops=1)
->; Append (cost=0.42..21.23 rows=2 width=232) (actual time=0.078..25.695 rows=1710 loops=1)
Subplans Removed: 1
->; Index Scan using unified_order_item_10001_tenant_id_order_type_order_state_o_idx on unified_order_item_10001 uorder_item_1 (cost=0.42..12.89 rows=1 width=232) (actual time=0.078..25.609 rows=1710 loops=1)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND ((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
Filter: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date) AND (basic_amount <;>; '0'::numeric))
Rows Removed by Filter: 25109
->; Append (cost=0.30..20.66 rows=2 width=298) (actual time=0.002..0.002 rows=1 loops=1710)
Subplans Removed: 1
->; Index Scan using unified_order_10001_pkey on unified_order_10001 uorder_1 (cost=0.30..8.32 rows=1 width=298) (actual time=0.002..0.002 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.order_id))
Filter: (uorder_item.order_stock_type = item_stock_type)
->; Append (cost=0.29..16.63 rows=2 width=26) (actual time=0.002..0.002 rows=1 loops=1710)
Subplans Removed: 1
->; Index Scan using item_10001_pkey on item_10001 item_1 (cost=0.29..8.31 rows=1 width=26) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: ((tenant_id = (current_setting('app.tenant_id'::text))::integer) AND (id = uorder_item.item_id))
Planning Time: 1.489 ms
Execution Time: 34.503 ms
(20 行记录)第二条SQL是34.503 ms,速度较慢,没有Incremental Sort,多了Subplans Removed
15.2.4 Schema
Limit (cost=4370.31..4370.44 rows=50 width=572) (actual time=7.404..7.408 rows=50 loops=1)
->; Sort (cost=4370.31..4370.58 rows=105 width=572) (actual time=7.403..7.405 rows=50 loops=1)
Sort Key: uorder_item.order_date, uorder.id, uorder_item.items_order
Sort Method: top-N heapsort Memory: 58kB
->; Nested Loop Left Join (cost=296.46..4366.83 rows=105 width=572) (actual time=0.934..6.342 rows=1710 loops=1)
->; Nested Loop (cost=296.18..4235.80 rows=105 width=396) (actual time=0.922..3.823 rows=1710 loops=1)
->; Bitmap Heap Scan on unified_order_item uorder_item (cost=295.89..1743.16 rows=452 width=133) (actual time=0.912..1.344 rows=1710 loops=1)
Recheck Cond: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date) AND ((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
Filter: (basic_amount <;>; '0'::numeric)
Heap Blocks: exact=378
->; BitmapAnd (cost=295.89..295.89 rows=471 width=0) (actual time=0.888..0.889 rows=0 loops=1)
->; Bitmap Index Scan on unified_order_item_order_date_idx (cost=0.00..55.90 rows=3961 width=0) (actual time=0.100..0.100 rows=3900 loops=1)
Index Cond: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date))
->; Bitmap Index Scan on unified_order_item_order_type_order_state_order_red_state_idx (cost=0.00..239.51 rows=14614 width=0) (actual time=0.736..0.736 rows=26819 loops=1)
Index Cond: (((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
->; Index Scan using unified_order_pkey on unified_order uorder (cost=0.29..5.50 rows=1 width=271) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: (id = uorder_item.order_id)
Filter: (uorder_item.order_stock_type = item_stock_type)
->; Index Scan using item_pkey on item (cost=0.28..1.22 rows=1 width=49) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: (id = uorder_item.item_id)
Planning Time: 0.425 ms
Execution Time: 7.494 ms第一条SQL是7.494 ms,速度较快,没有tenant_id过滤
Aggregate (cost=4346.71..4346.72 rows=1 width=360) (actual time=6.480..6.482 rows=1 loops=1)
->; Nested Loop Left Join (cost=296.47..4337.50 rows=105 width=87) (actual time=0.934..4.695 rows=1710 loops=1)
->; Nested Loop (cost=296.19..4209.62 rows=105 width=86) (actual time=0.928..3.289 rows=1710 loops=1)
->; Bitmap Heap Scan on unified_order_item uorder_item (cost=295.89..1743.16 rows=452 width=61) (actual time=0.916..1.381 rows=1710 loops=1)
Recheck Cond: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date) AND ((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
Filter: (basic_amount <;>; '0'::numeric)
Heap Blocks: exact=378
->; BitmapAnd (cost=295.89..295.89 rows=471 width=0) (actual time=0.892..0.893 rows=0 loops=1)
->; Bitmap Index Scan on unified_order_item_order_date_idx (cost=0.00..55.90 rows=3961 width=0) (actual time=0.099..0.099 rows=3900 loops=1)
Index Cond: ((order_date >;= '2024-05-01'::date) AND (order_date <;= '2024-05-31'::date))
->; Bitmap Index Scan on unified_order_item_order_type_order_state_order_red_state_idx (cost=0.00..239.51 rows=14614 width=0) (actual time=0.747..0.747 rows=26819 loops=1)
Index Cond: (((order_type)::text = ANY ('{SALES_OUT,SALES_RETURN}'::text[])) AND ((order_state)::text = 'ENTRY_ACCOUNT'::text) AND ((order_red_state)::text = 'NORMAL'::text))
->; Memoize (cost=0.30..5.51 rows=1 width=33) (actual time=0.001..0.001 rows=1 loops=1710)
Cache Key: uorder_item.order_id, uorder_item.order_stock_type
Cache Mode: logical
Hits: 1137 Misses: 573 Evictions: 0 Overflows: 0 Memory Usage: 74kB
->; Index Scan using unified_order_pkey on unified_order uorder (cost=0.29..5.50 rows=1 width=33) (actual time=0.001..0.001 rows=1 loops=573)
Index Cond: (id = uorder_item.order_id)
Filter: (uorder_item.order_stock_type = item_stock_type)
->; Index Scan using item_pkey on item (cost=0.28..1.22 rows=1 width=9) (actual time=0.001..0.001 rows=1 loops=1710)
Index Cond: (id = uorder_item.item_id)
Planning Time: 0.411 ms
Execution Time: 6.615 ms
(23 行记录)第二条SQL是6.615 ms,速度较快,没有tenant_id过滤
15.2.4 小结
| 索引 | 场景 | 选型 | 时间 |
|---|---|---|---|
| 有索引 | 分页 | RLS+单表 | 0.902 ms |
| RLS+分区 | 15.376 ms | ||
| Schema | 7.494 ms | ||
| 有索引 | 聚合 | RLS+单表 | 13.747 ms |
| RLS+分区 | 34.503 ms | ||
| Schema | 6.615 ms | ||
| 无索引 | 分页 | RLS+单表 | 43.970 ms |
| RLS+分区 | 38.012 ms | ||
| Schema | 33.984 ms | ||
| 无索引 | 聚合 | RLS+单表 | 46.420 ms |
| RLS+分区 | 39.210 ms | ||
| Schema | 33.055 ms |
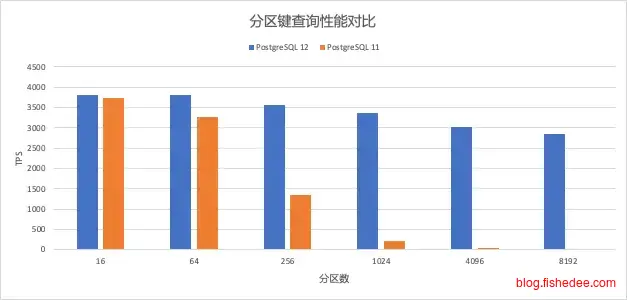
可以看到
- 无论是有索引,还是无索引的情况,Schema的性能综合都是最好的。
- 无索引的情况下,RLS+分区 比 RLS+单表性能要好,因为扫表的行要少得多。
- 有索引的情况下,RLS+单表 比 RLS+分区性能要好,因为不需要分区剪枝。在当前实验中,只有2个分区,现实情况下,超过256个分区以后,性能大概还要继续下降30%左右。
15.3 接口性能
以下是多个选型下,实测性能差距
com.fishedee.trade_erp.report.api.OrderReportController::queryByOrder 耗时:276(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItem 耗时:107(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItemPivot 耗时:76(ms)RLS + 单表的性能较差
com.fishedee.trade_erp.report.api.OrderReportController::queryByOrder 耗时:89(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItem 耗时:185(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItemPivot 耗时:53(ms)RLS + 分区的性能要好一点
com.fishedee.trade_erp.report.api.OrderReportController::queryByOrder 耗时:13(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItem 耗时:35(ms)
com.fishedee.trade_erp.report.api.OrderItemReportController::queryByItemPivot 耗时:29(ms)Schema的性能最好
20 总结
总的来说,PG的特点为:
- 完善丰富的数据类型,json,range,array类型
- 先进的索引,gin,gist,甚至是未来的rum
- 先进的查询优化器,多种多样的执行计划,bitmap index scan,topN sort,hash join,index sorted join
- 先进的插件机制,操作符,索引,表结构,数据类型都可以通过插件来扩展
- 比较复杂的维护,堆表结构造成的写放大问题,事务号是32位的回卷问题,mvcc没有回滚段需要定期清理过期数据,多进程架构需要单独的进程池
参考资料:
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!