1 概述
这可能是我遇到最麻烦的bug
2 现象
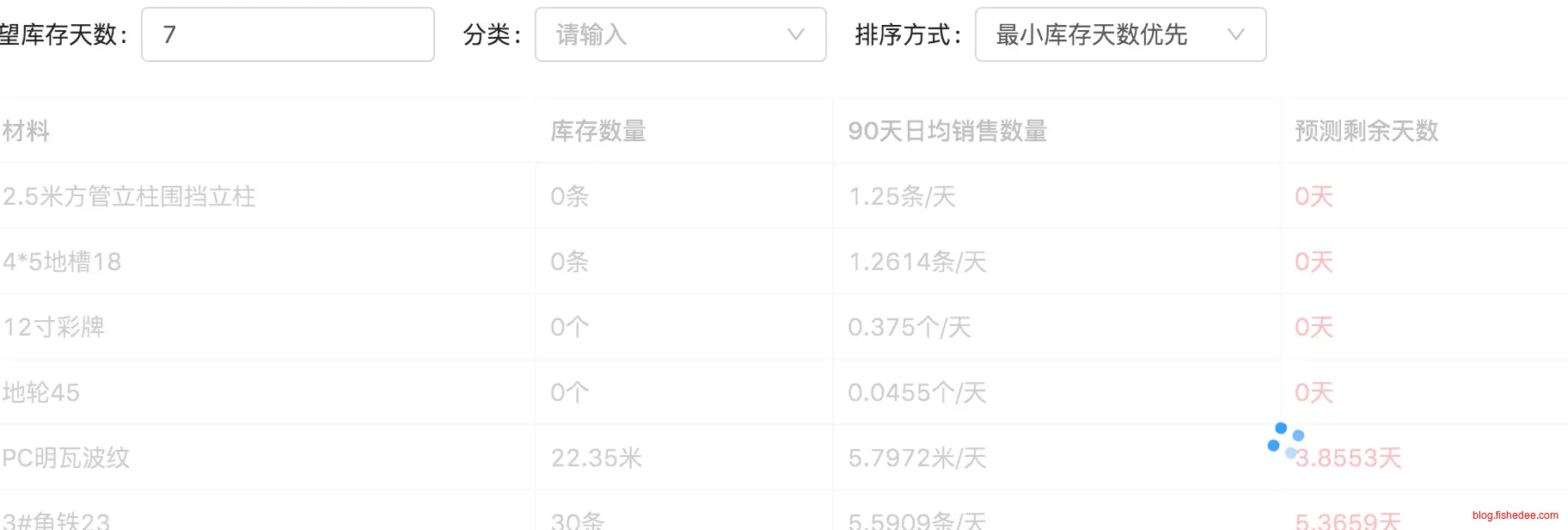
当打开特定的页面后,页面开始转菊花,打开Chrome的Network,发现某些请求的延迟高达10秒以上。所有页面绝大部分的情况都是秒开的,发生这样的情况,不会固定在特定的时间和页面,是一种随机发生的现象。
3 后台请求处理速度
后来,当发现这种情况后,我第一时间打开后台日志,每个请求的处理时间都是在毫秒级的。甚至写了个小工具,分析一个星期内,所有的请求处理时间都没有超过300ms的。
log_format timed_combined '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" ' '$request_time $upstream_response_time';但是仍然不够放心,我对nginx前端修改了日志格式,让它输出后端代理的处理时间request_time和看看upstream_response_time
然后分析nginx日志access.log,所有请求的处理时间依然是少于300ms的。
4 Fidder抓包
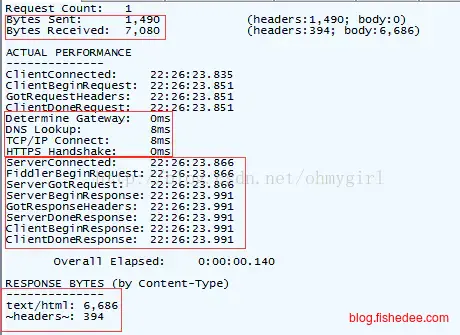
开了Fidder一整天,抓本地所有的包,发现出问题的时候,耗时主要集中在ServerGotRequest的阶段,我确实不知道这个字段是什么意思,Google了一遍也没有找到结果。我决定搞更深入的更底层的抓包,搬出了大杀器tcpdump。
5 Tcpdump抓包
Wireshark在Windows可以做到和tcpdump一样的效果,但是我担心问题是出现在我的盗版Windows系统上,没有将我的包发送出去,所以,我直接在路由器上抓包,而不是在Windows客户端上抓包
5.1 路由器抓包
我用的华硕路由器AC86u,插入U盘以后,选择Download Master,它就会自动下载各种固件。然后打开路由器的ssh功能。
ipkg update
ipkg upgrade
ipkg install tcpdump输入以上命令,安装好tcpdump
nohup tcpdump -i br0 -tttt -s0 -X -vv host xx.xx.xx.xx -w captcha.cap &将sd卡mount在一个文件夹上,然后在文件夹上执行以上脚本,br0是网卡名,tttt是时间戳格式,-s0,获取全部长度的数据,-X以 HEX 和 ASCII 模式输出数据包的内,host就是指定包的IP地址,-w就是写入包的位置
5.2 服务器抓包
sudo nohup tcpdump -tttt -s0 -X -vv tcp port 80 -w captcha.cap &服务器也是用linux了,轻松地也是用tcpdump进行抓包即可
6 抓包结果
6.1 过程
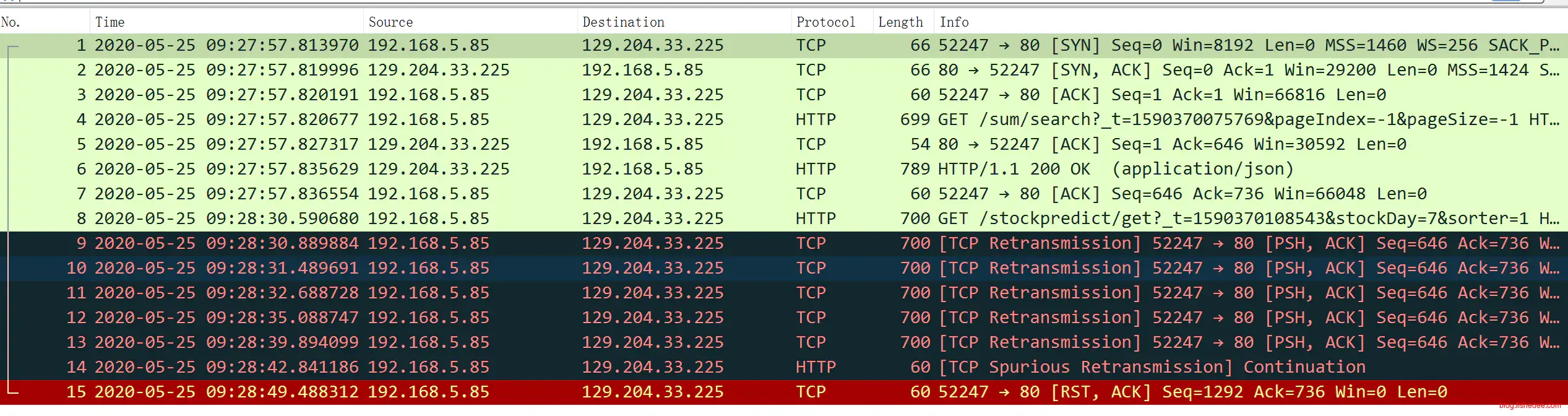
客户端路由器抓包结果如上图
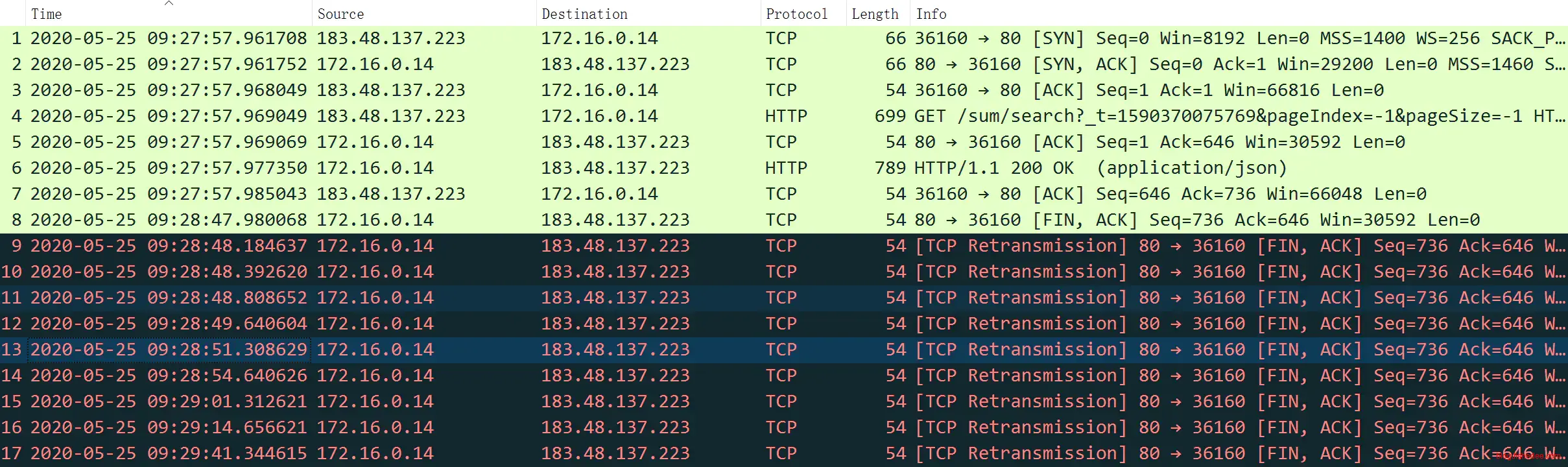
服务器抓包结果如上图
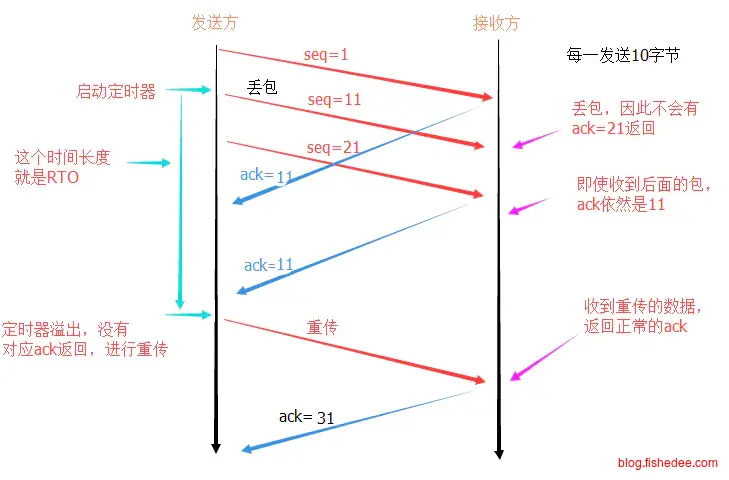
从结果中可以看出,9:27:57完成最后一个请求以后,30秒以后Chrome沿用同一个连接请求/stockpredict/get的结果,发现一直无法获得服务器的ACK请求。Chrome认为请求的HTTP包没有到达服务器,所以TCP自动执行重发机制。TCP重发的时候,根据RTO时间逐渐翻倍时间来重传的,看客户端记录中可以看出。
- 第一次重传是,9:28:30
- 第二次重传是,9:28:31
- 第三次重传是,9:28:32
- 第四次重传是,9:28:35
- 第五次重传是,9:28:39
- 第六次重传是,9:28:42
经过六次重传以后,客户端依然没有收到服务器发来的ACK请求,它绝望地发送RST,ACK请求,认为该TCP连接已经异常,单方面强行关闭链接,而没有经过传统的FIN的四次挥手的过程。
而站在服务器的角度上看,这个请求在9:27:57以后就没有发送任何一起请求过来,所以,根据HTTP 1.1长连接的配置,服务器在9:28:47执行标准的四次挥手的断开TCP连接的流程。但是发出的FIN请求并没有产生ACK回复,所以服务器不断重复发送FIN断开连接的请求,重复的次数竟然到达了9次,却没有收到1次的ACK回复,服务器也绝望到直接关断连接。
keepalive_timeout 50s;nginx中设置长连接的最长无请求的保留时间是keepalive_timeout字段
6.2 诡异
从分析可以得到,在9:28:27以后,客户端与服务器之间的这条TCP连接似乎完全断开了一样,互相无法发包到达对方。但是,由于我抓到的是全量的TCP包。抓包中可以看出,这段时间内的该服务器与该客户端的其他TCP连接都是十分正常的,发包都是能立即到达的
第二个诡异的地方是,客户端请求的36160端口是半个小时才用过的,现在半个小时后又被重用了,所以这个端口被wireshark标记为tcp port number reused。
第三个诡异的地方是,目前我只在这个系统内操作才会出现这种无限转菊花的问题,访问百度和新闻网站没有这个问题。
最后诡异的地方是,这个系统曾经部署在阿里云上,当时也没有这种无限转菊花的问题。
7 可能原因
种种原因指向了问题可能出在腾讯云身上,而我也在知乎上有找到类似的抱怨,但与我的现象依然有点区别。提交工单后,询问客服,客服看着我的抓包结果图后,仍然说是业务层面的问题,不是云平台自身的问题。
确实,就这么大个平台,不可能就我这么一个人就遇到了这个bug吧。我斗胆猜测,问题可能是:
- NAT分配端口重复,单个NAT分配的端口仅有65536个,如果这个NAT机器接收的连接过多过快,就会产生重复的端口分配,甚至会提前丢弃一部分不活跃的端口映射条目
- NAT转换时间过期,从我的客户端到服务器之间肯定经过了多层的NAT,NAT有一个端口转换的保留时间,如果在一定时间内,两个目的地的端口之间没有任何请求的话,就会删除这个端口转换记录,导致这条连接无法找回到达对方的路。
- 营运商主动丢弃,客户端与服务器之间的并发连接数过多,为了节省资源,主动丢弃一部分的连接
由于缺少进一步的分析,我暂时的解决方案是
- 将服务器的固定公有IP,转换为弹性公有IP,切换网络拓扑的话可能会切换不同的网络结构,避免了有问题的机器
- 将nginx长连接保留时间缩短到30秒,避免NAT转换时间过期的问题
- 开启nginx的so_keepalive,配置为5s:2:2,代表当客户端5秒没有发请求过来的时候,主动发送keepalive包来检查客户端是否存在,如果keepalive没有ack包的时候,2秒后再检查2次,2次均失败的话直接断开连接。这个配置是为了客户端因为异常退出的时候,主动释放TCP资源。另外,10秒的主动探活保证了通信链路的NAT和路由设备都保留两者的通信信息。这个配置经常用来保证TCP长连接不会被LVS或者F5等负载均衡机器回收。
- 将http 1.1升级到http 2.0,http 2.0支持在不同请求可以并发重用在一个tcp连接上,避免了不断重复新建tcp连接以提高并发度的问题。
8 总结
如果你有更好或更进一步的分析方法,不妨联系我
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!