1 概述
使用InfluxDb与Grafana做一个监控系统。在项目部署上线后,我们如何监控系统的健康与性能状况,例如,我们时常需要收集以下数据:
- 获取系统中每个时刻的error数量与crash数量,当这些数量突然增大时,肯定不健康的。这个时候,开发者可以从日志中找出问题所在。
- 获取系统中每个时刻占用的堆内存数量,golang协程数量,golang的IO等待的数量,如果这些数量持续长时间处于一个高水平的状态,也肯定是不健康的。这个时候,开发者可以从远程pprof的性能分析中,知道系统的堆内存集中在什么地方,协程block在什么地方等等。
- 获取系统的API请求的延时与吞吐量,以了解系统的性能水平,如果延时过高,就会影响用户体验,如果吞吐量稍大时,就会导致内存飙升,就证明系统的性能还需继续完善。
- 获取系统的各个路径与各个模块的延迟与吞吐量的水平。当我们发现总体API的延迟过高时,我们就需要深入地分析是哪些API的延时过高,这些API在执行时哪个模块的延时过高。通过这些的数据,我们才能找出性能瓶颈来针对性优化系统,而不是两眼一瞎,凭感觉优化。
所以,在系统上线后,要持续完善系统的第一步是做好监控系统。当监控系统发现问题后,我们再通过日志系统,性能分析系统等工具来协助解决问题。
2 采样
监控的第一步是采集数据,然后上报到存储系统。和日志系统不同的,监控系统的数据大多数是聚合性的。例如:
- 监控每秒的error数量和crash数量,我们需要将每秒的数据sum起来。
- 监控系统的API请求的延时和吞吐量,我们需要以每分钟为取样数据,计算它的平均延迟mean,最大延迟max,P99延迟precent等,以及计算它的每秒能处理的请求数量meanrate。
- 监控系统的堆大小,协程大小,这些瞬时值,就不需要做聚合了。
要获取聚合结果,我们有两个办法:
- 直接将每个时刻的数据丢到存储系统,然后由存储系统做聚合计算,很明显,这样的办法对存储系统的计算量要求大,而且推送的数据量大。
- 在本地的内存中提前做好每秒数据的聚合结果,然后再推送到存储系统,存储系统只需要简单计算就能做结果展示了。
很明显,第二个方法更好,golang中有方便的go-metrics库实现了这个方法,它能在本地内存中采样数据并聚合结果。
2.1 Counter
c := metrics.NewCounter()
metrics.Register("foo", c)
c.Inc(47)Counter是计数器指标,这个指标能不断累加同一个Atomic.Int64的数值。注意,这个指标并没有在每一秒后自动清零,它会不断变大,直至重启服务器。当我们将这个数据提交到存储系统后,我们需要在存储系统中执行difference操作(前后连续数值相减)来获取每秒的Counter递增数值。
Counter常用于记录系统中每个时刻的error数量与crash数量等等。
2.2 Gauge
g := metrics.NewGauge()
metrics.Register("bar", g)
g.Update(47)Gauge是一个瞬间指标,这个指标仅存储一次数据,当再次Update数据以后,前一次存储的数据就会丢失。例如,Gauge指标是每300ms收集一次,而我们只在每1s中Snapshot一次的时候,就会导致Gauge的指标每秒内丢失2次~3次的数据。所以,要注意合理安排好Gauge指标的收集周期,和执行Snapshot的周期。
Gauge常用于系统中每个时刻占用的堆内存数量,golang协程数量,golang的IO等待的数量,GC每次停顿时间等等。
2.3 Meter
m := metrics.NewMeter()
metrics.Register("quux", m)
m.Mark(57)Meter是一个记录速率(数量/每秒)的数据,每秒速率不是一个静态的数值,它需要在一个指定的取样区间中才能计算出来。例如,最近一分钟的速率(m1),最近三分钟的速率(m3),最近十五分钟的速率(m15),甚至是迄今为止的平均速率(meanrate)。
要实现这个聚合结果,有两个方法:
- 最朴素的计算最近一分钟的速率,我们就需要记录最近一分钟内的所有数据。当新的数据进来后,就剔除旧的一分钟以外的数据,然后插入新数据,最后聚合这一分钟内的数据计算速率平均值。这样做的优点是简单暴力准确,缺点是内存占用太大,计算太慢。如果系统每秒接收6k个请求,就需要在内存中存储360k的请求的数据(一分钟内取样数据)。计算上即使用上了平衡树的算法,每次插入也需要log(N)的复杂度。
- go-metric使用的是EWMA算法,就是将一分钟划分为12个区间(每5s一个区间),每收到一个Mark的时候,就累加当前的5s区间的数值,当5s到达以后,就将前11个区间的速率与当前区间的速率加权平均,然后将所有区间往前一位。这样做的优点是,无论多快的请求,它占用的空间都是固定的,计算量也是固定的。缺点是与真实数值会一点偏差。
Meter常用于记录系统的吞吐量。
2.4 Histogram
s := metrics.NewExpDecaySample(1028, 0.015) // or metrics.NewUniformSample(1028)
h := metrics.NewHistogram(s)
metrics.Register("baz", h)
h.Update(47)Histogram是一个计算最值,平均值,P99值的数据,也是最难实现的指标。
要计算系统的最值,平均值,P99值,不太容易。朴素的做法是将系统自启动开始的数据全部记录下来,然后每次Snapshot的时候进行排序,然后计算最值,平均值和P99值,但显然这样的做法内存占用大得不可接受,而且得出来的数据的借鉴意义不大,因为受前面数据的权重太高所影响,后面的数据无法很好地改变整体指标。
进一步的改进就是,让系统只保留reservoirSize大小的队列,当新的数据进来时,如果队列是满的,就先剔除最旧的数据,再插入到队列尾部,如果队列不是满的,就直接插入到尾部。然后每次Snapshot的时候,就只计算整个队列的最值,平均值和P99值。显然,这样的效果好得多,能反映最近的指标变化,并且计算量和空间量都是固定的。但是,如果每秒有1k个请求,而当队列的reservoirSize设置为100的时候,就会造成前面的900个请求是被无情丢弃的,计算出来的指标是局部不全面的。
go-metrics的UniformSample使用了随机剔除+固定reservoirSize队列的算法,就是当队列是满的时候,不是剔除最旧的数据,而是随机剔除一个数据,这样就比第二个方法较好一点。但是,随机剔除的问题是,运气不好的情况的话,可能剔除的都是最新的数据,留下的都是上一分钟的数据,造成指标的结果也是不准确的。
go-metrics的ExpDecaySample算法进一步优化,它使用了随机与时间共同权重剔除+固定reservoirSize队列的算法,每个数据在插入的时候,会赋予一个权值,这个权值是时间与随机相结合的权重,随机数越大权重越大,时间越新权重越大。当队列满的时候,剔除的是权重最小的数据。因此,这个算法实现了优先剔除旧数据,对于新数据则随机剔除的效果。这个算法空间和计算量都是固定的,而且结果也比较准确。
Meter常用于记录系统的延迟。
2.5 Timer
Timer其实就是使用了ExpDecaySample(1028,0.015)的Histogram和Meter的组合,就不啰嗦了。
3 存储与计算
存储上我们选择时序数据库InfluxDb,时序数据库的特点是以时间为key,插入速度快,查询操作复杂,很少做删除或修改数据的操作,没有联表操作,更没有一致性。
3.1 基本概念
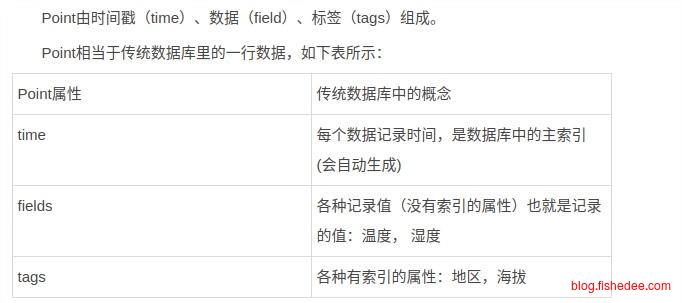
//语法
select|insert <measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
//例子
insert payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3i 1516167115623067775InfluxDb中measurement相当于数据库中的Table,tag相当于数据库中的索引字段,field相当数据库中的非数据库字段。在InfluxDb中,只有tag字段是被索引的,按照tag字段查找数据很快,而用field字段是没有索引的,按照field字段查询数据很慢,每次都需要全部数据搜索一次。另外,严格的来说,InfluxDb的主索引字段是时间,二级索引字段是所有的tag。
CREATE RETENTION POLICY "two_hours" ON "food_data" DURATION 2h REPLICATION 1 DEFAULTInfluxDb中还有RETENTION POLICY保留规则的概念,默认规则是保存全部数据,当如上设置的时候,就会改变默认保留规则为2小时,就是这个food_data数据库内的所有measurement默认剔除2小时以前的数据,Table的全称应该叫为RP.measurement。保留规则保证了InfluxDb会不断删除旧的数据,避免浪费空间。
CREATE CONTINUOUS QUERY "cq_30m" ON "food_data" BEGIN
SELECT mean("website") AS "mean_website",mean("phone") AS "mean_phone"
INTO "a_year"."downsampled_orders"
FROM "orders"
GROUP BY time(30m)
END另外一个新的概念是CONTINUOUS QUERY,连续查询。就是每隔一段时间聚合一个measurement的数据到另外一个measurement中。例如,以上的代码指定每隔30分钟,将order的measurement的数据聚合到”a_year”.”downsampled_orders”的measurement。a_year是一个保留规则名称,保留规则的名称则是在声明RP规则时定下来的。连续查询是InfluxDb保证聚合性能的方法,通过每隔一段时间聚合最近一个时间段的数据,而不是每次都全量聚合数据。
最后,整个类sql操作是无schema的,你可以动态添加measurment,动态添加field和tag,而不需要像关系数据库一样需要提前声明schema。
3.2 架构浅析
我们简要地分析一下,InfluxDb是如何实现目前为止最快的时序数据库的。
| time | tag1 | tag2 | field1 | field2 |
|---|---|---|---|---|
| time1 | ||||
| time2 | ||||
| time3 | ||||
| time4 |
刚开始看influxDb的时候,以为它就是这样的一个表。tag字段就是可筛选的列,field就是存储的值,不可筛选的列,然后主键是time。
| tags | field1 | field2 |
|---|---|---|
| tag1=tag1_value1&tag2=tag2_value1 | time1=value1,time2=value2,time3=value3,… | |
| tag1=tag1_value1&tag2=tag2_value2 | time1=value1,time2=value2,time3=value3,… | |
| tag1=tag1_value2&tag2=tag2_value1 | time1=value1,time2=value2,time3=value3,… | |
| tag1=tag1_value2&tag2=tag2_value2 | time1=value1,time2=value2,time3=value3,… |
实际上,influxDb的主键是所有tag的组合,列是field,那么值就是这个的filed下,将所有时间的这个field对应的value的集合。
seriesKey = measurement + 所有 tag_name/tag_value 的序列化字符串
key = measurement + 所有 tag_name/tag_value 的序列化字符串 + 分隔符 + 某个单独的filedNameinfluxDb中,主键称为seriesKey,它的值是measurement+tags。key就是主键下某个列,因此是seriesKey+fieldName。
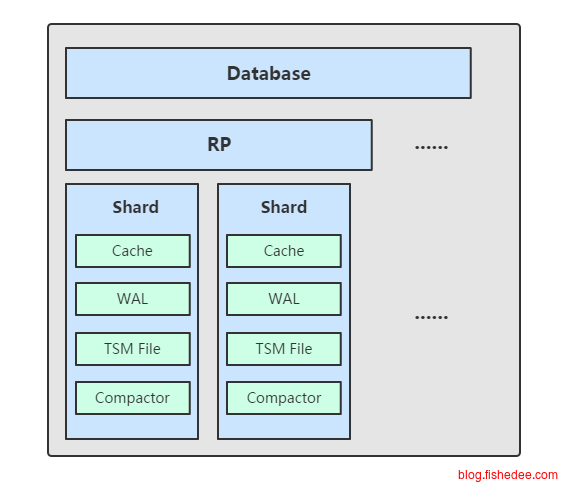
最后为了凸显时间序列数据库的场景,数据不是按照主键来分区,而是按照时间来分区。所以,查找某段时间的数据,只需要查找特定的shared,而不是查找所有的shared。例如是每隔一段1小时就生成一个新的shared目录。要注意的是,一个shared目录中就将所有measurement在这个时间段的时间都存放进去,而不是像数据库一样,一个表一个文件。另外,因为有RP策略的设定,按照时间对文件分区后,当RP执行淘汰旧数据时,就只需要直接删除旧的shared目录就可以了。但是,不同的RP策略的measurement,就不能放在同一个shared中,因为这样过期执行删除操作时会出问题。
因此,在大概知道influxDb的结构后,它的场景应该集中在,在任意全tag组合下的某个field的任意时间段聚合操作。不要尝试做单一tag下的某个field的任意时间段聚合操作,或者做无tag下的某个field的任意时间段聚合操作,因为这样做不能匹配单一主键,value数据是散乱存放的,查询效率很低。
# wal 目录结构
-- wal
-- mydb
-- autogen
-- 1
-- _00001.wal
-- 2
-- _00035.wal
-- 2hours
-- 1
-- _00001.wal
# data 目录结构
-- data
-- mydb
-- autogen
-- 1
-- 000000001-000000003.tsm
-- 2
-- 000000001-000000001.tsm
-- 2hours
-- 1
-- 000000002-000000002.tsm每个shared目录由四部分组成,cache组件,wal文件,tsm文件,compactor组件
3.2.1 tsm文件

一个tsm文件由四部分组成,Header,Blocks,Index,Footer。注意,一个tsm文件就是某个RP规则和某个时间段下,所有的measurement的数据。

Header就是保留一下版本号和MagicNumber,没什么好说的

Blocks文件就只存放时间戳和field_value数据,连field_name的数据都不存放。另外,数据是连续存放的,InfluxDB 中会针对不同的field_value数据类型来采用不同的压缩方式对数据进行压缩。另外,CRC校验码用来检查这个block里面的数据有没有问题。

type BlockIndex struct {
MinTime int64
MaxTime int64
Offset int64
Size uint32
}
type KeyIndex struct {
KeyLen uint16
Key string
Type byte
Count uint32
Blocks []*BlockIndex
}以时间为一级索引后,tsm的文件承载的就是seriesKey,也就是key,即主键+列的二级索引工作,它的value就是多个point的数据,每个point的数据包括,这个point在fieldName下的fieldValue值和时间戳。而在Index文件中就是Count个Block数据,每个Block数据包括偏移量和数量,时间戳范围。很明显,这个数据结构的每一个KeyIndex都是不定长度的,那怎么在磁盘中快速索引呀。
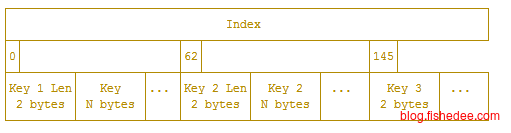

答案是这个数据结构的设计压根就不是在磁盘中索引的,而是在内存中索引。每个TSM文件的Index部分会整个读进内存中,并且生成一个offset的数组。如果要搜索某个key下面的数据,就会在内存中执行二分搜索,先获取offsets数组的中间数据,根据offset获取它在Index数组的元素,根据Index数组元素的key,再决定是在offset中取左边,还是取右边的数据。最后定位到某一个key上就简单了,获取这个key对应的block数据,包括偏移量和长度,然后在磁盘中批量读取Block部分的数据。
例如,我们要读取最近三天的关于某个全tag下的某个field的value的总数。首先,获取三天时间所在的所有分区。对于每个分区,用二分查找查找key为“全tag+fieldName”的Index的位置。最后根据Index获取多个Block,筛选Block中的时间字段在最近三天内的Point,将它们的value计数在一起就可以了。
type SeriesIDs []uint64
type Measurement struct {
Name string `json:"name,omitempty"`
fieldNames map[string]struct{} // 此 measurement 中的所有 filedNames
// 内存中的索引信息
// id 以及其对应的 series 信息,主要是为了在 seriesByTagKeyValue 中存储Id节约内存
seriesByID map[uint64]*Series // lookup table for series by their id
// 根据 tagk 和 tagv 的双重索引,保存排好序的 SeriesID 数组
// 这个 map 用于在查询操作时,可以根据 tags 来快速过滤出要查询的所有 SeriesID,之后根据 SeriesKey 以及时间范围从文件中读取相应内容
seriesByTagKeyValue map[string]map[string]SeriesIDs // map from tag key to value to sorted set of series ids
// 此 measurement 中所有 series 的 id,按照 id 排序
seriesIDs SeriesIDs // sorted list of series IDs in this measurement
}
//Series就是主键结构,它可能分散到多个分区上。
type Series struct {
Key string // series key
Tags map[string]string // tags
id uint64 // id
measurement *Measurement // 所属 measurement
// 在哪些 shard 中存在
shardIDs map[uint64]bool // shards that have this series defined
}但要注意的是,这样只解决了根据所有的tagName与tagValue组合的key搜索的数据,如果我要查找单个tagName下指定的tagValue对应的有哪些Point的时候怎么办?InfluxDb的方法简单暴力,在读取Index部分的时候,在内存中生成一个seriesByTagKeyValue的二级map,这个数组可以根据在指定的tagName和指定的tagValue下获取它的所有series数据,根据series数据我们又开始愉快地在Index与Offset部分中进行二分搜索了。

最后一个Footer部分存放的就是Index部分在TSM文件的偏移量,以方便我们在拿到TSM文件时就能直接定位到Index部分。
3.2.2 cache组件与wal文件
在解决了InfluxDb如何做查询的问题后,我们来探讨一下InfluxDb如何实现快速写入数据。总的来说,它的做法和搜索引擎的做法非常类似。
- 插入数据,添加数据时先写入到内存cache中,然后将每条数据直接加入到一个wal文件的尾部并flush。当内存的cache数据满了以后,就将cache的数据转储为TSM文件,并删除临时的wal文件。wal文件的意义在于,即使机器在中途断电,数据也不会丢失,重启后可以从wal文件中重建cache数据。
- 删除数据,删除数据时如果数据在cache,在直接删掉,如果数据在TSM文件,就将数据的标志位记录为已删除就可以了,也就是软删除,而不是物理删除。
- 修改数据,不支持。

wal文件是按照插入顺序,依次存放每个point的数据。它不像TSM文件的index部分数据是按照key的字典序保存的,它是按照插入顺序依次存放的,这样的做法保证了最快的插入速度(磁盘是顺序写,而且无读取操作,只有写入操作)。
type Cache struct {
commit sync.Mutex
mu sync.RWMutex
store map[string]*entry
size uint64 // 当前使用内存的大小
maxSize uint64 // 缓存最大值
// snapshots are the cache objects that are currently being written to tsm files
// they're kept in memory while flushing so they can be queried along with the cache.
// they are read only and should never be modified
// memtable 快照,用于写入 tsm 文件,只读
snapshot *Cache
snapshotSize uint64
snapshotting bool
// This number is the number of pending or failed WriteSnaphot attempts since the last successful one.
snapshotAttempts int
stats *CacheStatistics
lastSnapshot time.Time
}cache就是简单地按照key实现的map。key就是measurement + 所有 tags 的序列化字符串 + 分隔符 + 某个单独的filedName。当cache的大小超过maxSize以后,这个cache就会转换为只读的snapshot cache,然后由compactor将数据转储到新的TSM文件,之后的插入操作将会在新的cache中进行。
3.2.3 compactor组件
compactor操作每隔一秒会定期运行一次,它的工作有两个:
- 当cache的大小超过maxSize以后,或cache的文件最后一次写操作的较长的时间以后,将其转储到TSM文件中
- 将多个小的TSM文件合并为一个新的TSM文件,合并的时候顺道将软删除的point变为物理上的删除。
3.3 schema设计与优化
有了基本概念和基本原理以后,我们进一步说明如何设计InfluxDb的schema,才能实现最大的性能优化:
- 避免根据type不同而设计不同的measuremnt名称。例如,我们要记录/user/get与/user/add两个请求的请求情况,如果我们分别存放都不同的user_add_request与user_get_request的measurement中,就会造成不方便。因为InfluxDb不支持跨表查询,我们无法聚合这两个请求的请求次数,以及做延迟对比。我们应该只建立一个api_request的measuremnt,然后通过tag来区分不同的API请求。
- 避免过多的series。InfluxDb的tag过滤查询完全依赖于内存中的Index部分与seriesByTagKeyValue的映射。如果series的数量太多,就会占用太多的内存。避免过多的series有两个要求,不要设置过多的tag_name字段,以及tag_value区分度不要太多,例如tag_value不要存放UUID,随机字符串这些数据。
- 避免正则查询。虽然InfluxDb支持正则查询,但很显然,他不能通过seriesByTagKeyValue的映射来快速查找到所在的Series,它只能通过遍历所有的Series来实现。所以,尽量避免tag上进行正则查询,而是试试能不能在schema上将单个tag_name转换为多个tag_name。
- 合理配置InfluxDb。cache-max-memory-size,cache-snapshot-memory-size,cache-snapshot-write-cold-duration是控制cache文件什么时候才转储到TSM文件。这些数值越大,插入性能就越好,但占用的内存也越大,所以要根据实际情况合理配置InfluxDb。
4 展示与报警
监控数据的展示与报警使用的是Grafana,这个挺简单的,都是UI操作,就不啰嗦了。
5 总结
参考资料:
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!