1 概述
统计学习应用场景
2 预处理
2.1 分词
分词就是将句子划分为单词,因为在中文语境中,词语与词语之间是没有空格隔开的,需要我们用算法分割开来,例如句子”中华民族从此站起来了“,分词以后就变为”中华民族/从此/站起来/了“
2.1.1 词典最大匹配法
词典最大匹配法的方法,是通过查询词典,从左往右活着从右往左,尽可能将能成为一个单词的字组合起来。 例如,原来的句子中,从左往右匹配时
- 中,词的开始
- 中华,有这个词,所以不分割
- 中华民,没有这个词,但是含有单词是以“中华民”喂前缀的,所以也不分割
- 中华民族,有这个词,所以不分割
- 中华民族/从,没有这个词,而且没有单词是以“中华民族从”为前缀的,所以分割
- 中华民族/从此,有这个词,所以不分割
- 中华民族/从此/站,没有这个词,而且没有单词是以“从此站”为前缀的,所以分割
- 中华民族/从此/站起,有这个词,所以不分割
- 中华民族/从此/站起来,有这个词,所以不分割
- 中华民族/从此/站起来/了,没有这个词,而且没有单词是以“站起来了”为前缀的,所以分割
2.1.2 独立最大概率法
\[ C=W_1W_2W_3\\ C=W_4W_5W_6 \]
当一次句子可以划分为以上两种方法时,独立最大概率法是假设单词之间是独立的,然后取最大概率的那个
\[ P(C)=P(W_1)P(W_2)P(W_3)\\ P(C)=P(W_4)P(W_5)P(W_6) \]
单词出现的概率可以用从大量标注数据中统计出来,取最大概率序列的方法最直观就是暴力搜索,更好的办法是动态规划。因为每个位置的切分方法仅有以下几种,以当前字为一个词,或以当前2个字为一个词,或以当前3个字为一个词等等,然后往前递归就可以了。
2.1.3 马尔可夫模型
\[ P(C)=P(W_1)P(W_2|W_1)P(W_3|W_2)\\ P(C)=P(W_4)P(W_5|W_4)P(W_6|W_5) \]
马尔可夫法更进一步,它将第二个以后出现的词的概率假设为条件概率,是在已知前一个词的条件下计算当前词出现的概率。分词更加准确可靠,只是需要训练的数据量要大得多了。取最大概率序列的方法依然为动态规划。这个方法也被称为N-gram方法
2.1.4 隐马尔可夫法模型
中/B 华/M 民/M 族/E 从/B 此/E 站/B 起/M 来/E 了/S
将分词看成是序列标注问题,定义四个标注,B代表词的开始,M代表词的中途,E代表词的结束,S代表单字词。然后将标注看成隐藏状态序列T,句子看成是字的观测序列O,然后分词问题就看成了在已知O的情况下,如何求最大概率的T的问题了。
类似的马尔可夫的方法还有MEMM和CRF,是目前分词效果最好的方法。
2.2 关键词和停顿词
在做文章分类,文章相似度匹配时,一个简单的方法就是将所有词都提取出来做词频向量做比较,可是这样的话向量太大了。一个简单的办法就是我们只提取有效的关键词,去掉常用的停顿词(例如,的,么,是,了这些),然后只用这些关键词来做词频向量。
另外,搜索引擎中要搜索“汽车是什么结构”这个句子时,它会先提取关键词”汽车”和“结构”,然后根据词重来选择优先显示“汽车”的内容,还是”结构”的内容。
2.2.1 TF-IDF



从公式中,很容易就能看出,TF是描述该词与该文档的相关性,IDF是该词在众多文档中的区分度有多高,两者相乘就能得出该词在本文档中的权重,显然权重越高的单词,就越有可能是关键词。而那些IDF本身就很低的单词,我们就将其列入停顿词。
2.3 词袋
词袋就是从语义上将单词降维为小量维度的向量,一般用在文章分类,上下文分析中。
2.3.1 word2vec
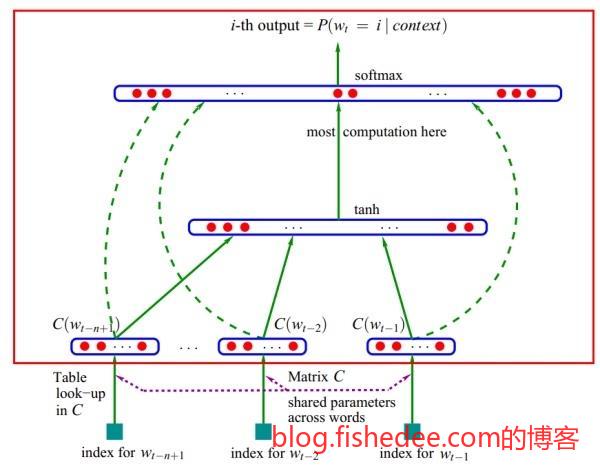
使用深度学习的方法计算,具体原理我也不太懂。
3 预测
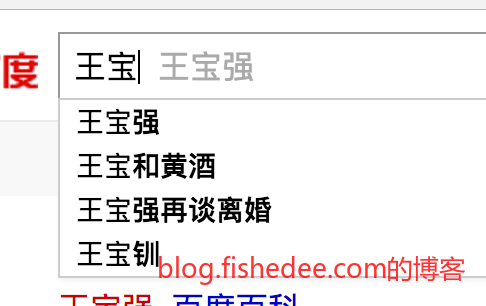
预测是一个很常见的NLP问题,例如你在搜索引擎中输入了“王宝”两个字,搜索引擎会分析出你下一步你最想输入的是“强”字。
3.1 马尔可夫模型
设已经输入的词为\(w_1,w_2,...w_n\),而我们要做的就是预测词为\(w\),用概率的问题描述就是
\[ P(w|w_1,w_2,...w_n) \]
w取什么时以上概率最大?
根据马尔可夫假设,使用2-gram模型,那么
\[ P(w|w_1,w_2,...w_n)=P(w|w_{n-1},w_n) \]
所以我们统计一下语料库就能得到这个数据了
4 词性标注
\[ 我/rr, 的/ude1, 爱/vn, 就是/v, 爱/v, 自然语言/gm, 处理/vn \]
词性标注是在已经给定句子分词的情况下,给定每个词语的词性。例如,以上的句子中,第一个“爱”是名词,而第二个“爱”是动词。
4.1 隐马尔可夫模型
将看到的词语为观测序列,标注序列为状态序列,词语与标注之间为转移概率。那么问题就转变为已知观测序列的状况下,求状态序列。显然,可以直接套用隐马尔可夫模型来解决了。
相似的方法还有,MEMM和CRF。
5 命名实体识别
命名实体识别是从文本中识别具有特定类别的实体,例如人名、地名、机构名等。命名实体识别是信息检索,查询分类,自动问答等问题的基础任务,其效果直接影响后续处理的效果,因此是自然语言处理研究的一个基础问题。
5.1 隐马尔可夫模型
处理的方法和HMM处理词性标注一样,就不再啰嗦了,更好的方法也是MEMM和CRF。
6 摘要
文章摘要就是在已经有一篇文章的情况下,自动生成出它的摘要信息。
6.1 抽取式
先使用TF-IDF分析出文章的关键词,然后对每个句子用关键词是否存在进行打分,抽取出前k个最关键的句子合并起来作为文章摘要
7 分类
垃圾邮件分类,垃圾短信分类,评论分类,等等这些都是文本分类的方法
7.1 k近邻
k近邻的方法比较暴力,直接对所有的数据进行余弦相似度计算,取最靠近的几个文章,然后取文章分类最多的那个作为类别。
7.2 贝叶斯模型
贝叶斯模型相当简单,假设特征向量X中的每个成分都是相互独立的,然后用先验概率来推算出后验概率,实践证明这是一种相当简单,但是很有效的方法。
7.3 马尔可夫模型
马尔可夫模型在贝叶斯模型中更进一步,假设特征向量X中的每个成分只往前依赖一步,这样就能得到一个更为精准的分类判断。例如,在贝叶斯模型中,出现“打字员”这个词就会认为垃圾短信的概率较大。但是在马尔可夫模型中,它不但考虑“打字员”,还考虑词语前的一个词语。例如,当出现“招收打字员”时垃圾的概率较大,但是当出现“辞去打字员”时垃圾的概率就比较小,毕竟后面的词语更像是一种小说的描述。
8 总结
NLP目前仍然是统计学习方法的主战场,需要训练的参数小,效果好。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!