1.概述爬虫,怎么分析网页中的html
2.问题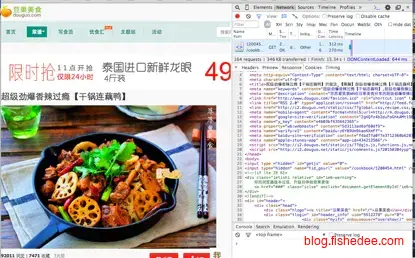
我们最近要需要抓取豆果的文章下来,然后存到我们的数据库。问题是我们抓取到的都是html代码,怎么将从里面分析出标题,封面图片,材料,步骤等结构化的数据呢?
# 3.解决 ## 3.1.正则表达式 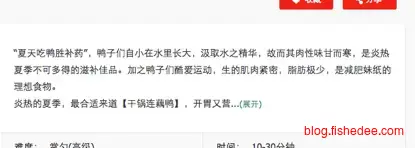
 使用正则表达式获取数据
使用正则表达式获取数据
/<div class=”xtip”>.*<\/div>/
正则的代码很难懂,维护性实在很头痛。 ## 3.2.jquery选择器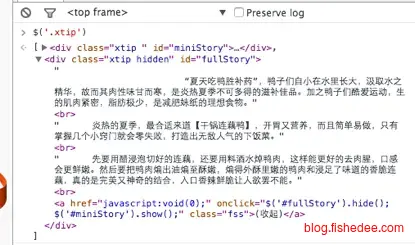 如果我们在浏览器上,要获取某个div的text,我们只需要用jQuery选择器做这么一件事$(‘.xtip’)。那么,在服务器上我们可以用类似jquery的语法来获取某个元素的数据么?答案是phpQuery##
3.3.headerless browser
如果我们在浏览器上,要获取某个div的text,我们只需要用jQuery选择器做这么一件事$(‘.xtip’)。那么,在服务器上我们可以用类似jquery的语法来获取某个元素的数据么?答案是phpQuery##
3.3.headerless browser 对于富ajax应用,第一次拉数据时返回的只是js文件,需要抓取数据都需要靠ajax来运行,怎么破?既然数据需要ajax来运行,那么我们就在服务器上运行一个浏览器吧,然后在浏览器上插入我们的js代码,监控所有ajax返回的数据。
# 4.其他问题 ##
4.1.频率校验抓取太频繁,会被抓的。解决方案是,降低频率,换IP,换user-agent##
4.2.登陆态需要登陆才能抓取数据的网站怎么做爬虫?##
4.3.验证码需要验证码才能抓取数据的网站怎么破? #
5.解决现在,你可以写一个12306抢票软件了。
对于富ajax应用,第一次拉数据时返回的只是js文件,需要抓取数据都需要靠ajax来运行,怎么破?既然数据需要ajax来运行,那么我们就在服务器上运行一个浏览器吧,然后在浏览器上插入我们的js代码,监控所有ajax返回的数据。
# 4.其他问题 ##
4.1.频率校验抓取太频繁,会被抓的。解决方案是,降低频率,换IP,换user-agent##
4.2.登陆态需要登陆才能抓取数据的网站怎么做爬虫?##
4.3.验证码需要验证码才能抓取数据的网站怎么破? #
5.解决现在,你可以写一个12306抢票软件了。
相关文章